下流タスクのフィードバックを用いた価値ベースの事前学習
従来の自己教師あり学習は、次トークン予測などの固定された代理目的関数を最適化する「オープンループ」な仕組みであり、膨大な計算資源が必ずしも最終的に必要な下流タスクの能力向上に効率よく割り当てられないという課題を抱えていた。
TL;DR(結論)
従来の自己教師あり学習は、次トークン予測などの固定された代理目的関数を最適化する「オープンループ」な仕組みであり、膨大な計算資源が必ずしも最終的に必要な下流タスクの能力向上に効率よく割り当てられないという課題を抱えていた。 本研究が提案するV-Pretrainingは、軽量な「タスクデザイナー」を導入し、少量の検証済みデータからのフィードバックを用いて事前学習のターゲットやビューを動的に再構成することで、各学習ステップが下流タスクの改善に寄与するよう制御する新しい枠組みである。 0.5Bから7Bの言語モデルを用いた実験では、わずか12%のGSM8Kデータを用いたフィードバックにより推論性能が最大18%向上し、視覚タスクでもセグメンテーションや深度推定の精度が改善されるなど、直接ラベルで学習することなく事前学習の効率を大幅に高めることに成功した。
なぜこの問題か
現在の基盤モデルの構築において、モデルの規模とデータ量を拡大することで性能を向上させる「ブラインドスケーリング」の時代は、収穫逓減の兆しを見せ始めている。基盤モデルは依然として、非常に方向性の定まらない方法で訓練されており、大規模でキュレーションの不十分なデータに対して静的な自己教師あり代理損失を最小化し、推論や知覚といった重要な能力が副産物として創発することを期待している。言語モデルにおいては次トークン予測が、視覚モデルにおいては自己教師ありの再構成や表現学習がその代理目的関数として機能しているが、これらは「オープンループ」なシステムとして機能しており、最適化の軌道は開始時に固定されている。このオープンループな性質は、事前学習におけるサンプル効率の悪さを招く要因となっている。人間はクローズドループのフィードバックを利用して誤りを迅速に修正しタスクを習得するが、モデルは修正的なガイダンスなしに何兆ものトークンを盲目的に消費し続ける。現在のパイプラインでは、フィードバックは主に事前学習後の教師あり微調整や好みの最適化を通じて注入されるが、これらの段階は導入が遅すぎるという問題がある。…
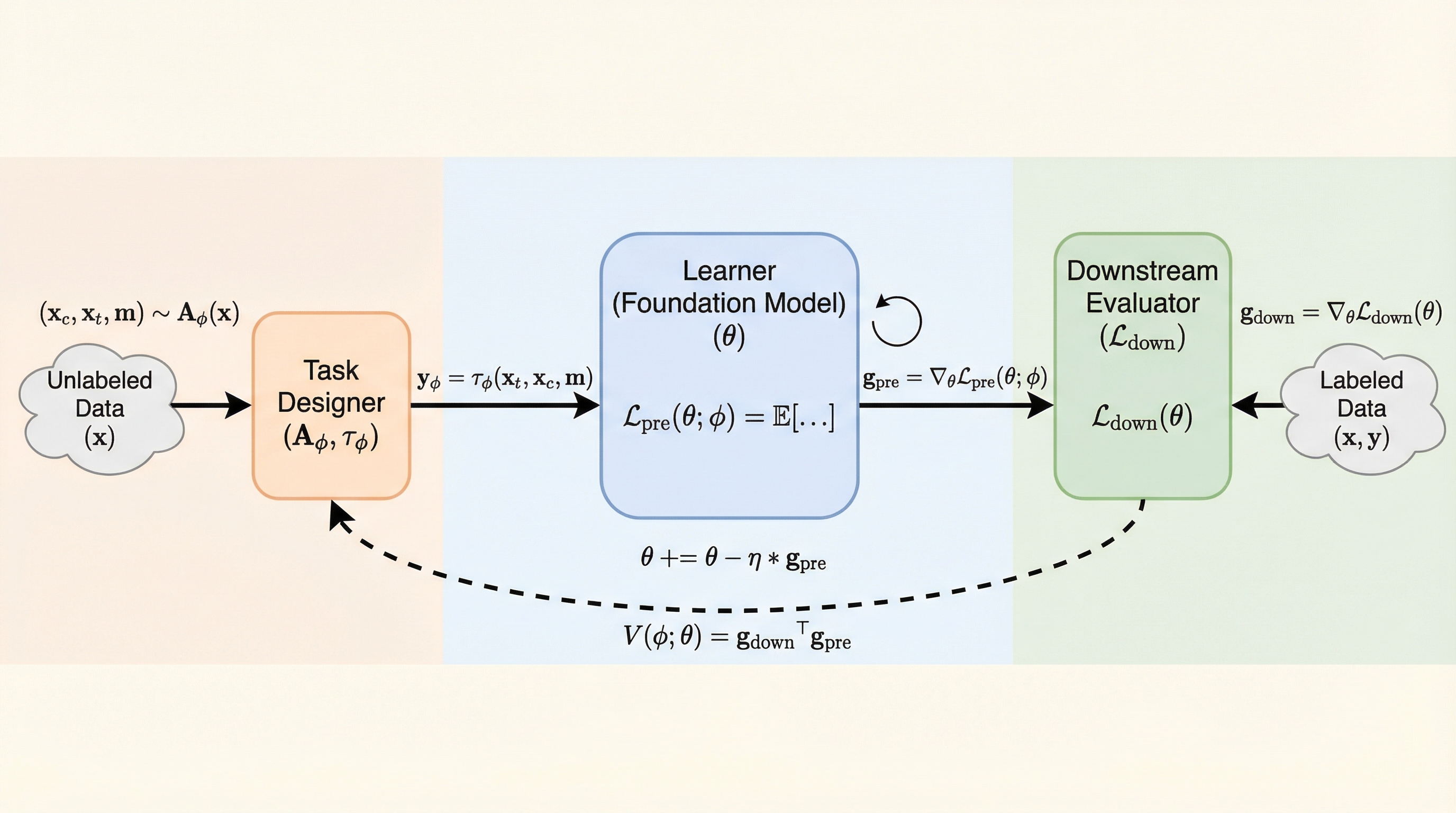
核心:何を提案したのか
本研究は、下流タスクのフィードバックを用いた価値ベースの事前学習フレームワークである「V-Pretraining」を提案した。このフレームワークの核心は、大規模な「学習者(Learner)」と、軽量な「タスクデザイナー(Task Designer)」を分離し、後者が事前学習タスクの構成を動的に制御する点にある。学習者はラベルのないデータのみを用いて訓練されるが、タスクデザイナーは少量のラベル付き検証セット(価値セット)を用いて訓練され、学習者の次の更新がターゲットとする能力にとってより価値のあるものになるよう、事前学習のターゲットやビューを再構成する。重要な点として、学習者自体は検証セットのラベルで直接更新されることは決してない。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related