DynaWeb: ウェブエージェントのためのモデルベース強化学習フレームワーク
従来のウェブエージェントの強化学習は、実際のインターネット上での試行錯誤を必要としていましたが、これには高額なコストや予期せぬ購入といったリスク、そして動作の非効率性という大きな課題がありました。
TL;DR(結論)
従来のウェブエージェントの強化学習は、実際のインターネット上での試行錯誤を必要としていましたが、これには高額なコストや予期せぬ購入といったリスク、そして動作の非効率性という大きな課題がありました。本研究で提案されたDynaWebは、ウェブ環境の挙動を模倣する「ウェブ世界モデル」を構築し、エージェントが仮想空間内での「想像」を通じて学習を行うことで、実環境への依存を大幅に削減するモデルベース強化学習フレームワークです。この手法は、世界モデルによるシミュレーションと実データの専門家軌跡を組み合わせることで、WebArenaやWebVoyagerといった難易度の高いベンチマークにおいて、既存のオープンソースモデルを凌駕する高い成功率と学習効率を達成しました。
なぜこの問題か
現在、人工知能のパラダイムは、オープンな環境で複雑かつ長期的なタスクを自律的に実行できるプロアクティブなエージェントシステムへと急速に移行しています。大規模言語モデル(LLM)は、高度な推論や柔軟なアクション生成、自然言語による対話を可能にするエージェントの強力なバックボーンとして台頭してきました。ウェブドメインにおいて、LLMベースのエージェントは、プロンプティングや構造化された推論、アクションの抽象化といった技術の進歩により、実際のウェブサイトをナビゲートし、ユーザーが指定した目標を達成する強力な能力を示しています。しかし、模倣学習を超えて、オンライン強化学習(RL)を用いてウェブエージェントを訓練することは、堅牢性や探索能力、長期的な意思決定を大幅に向上させる可能性を秘めている一方で、実環境との相互作用に伴うコストとリスクという根本的な制約に直面しています。 オンライン強化学習の有効性は、実環境との相互作用のコストによって制限されています。大規模なオンポリシーの経験を収集するには、エージェントがライブのインターネットと直接やり取りする必要がありますが、これは非効率で高価であり、大規模な制御が困難です。…
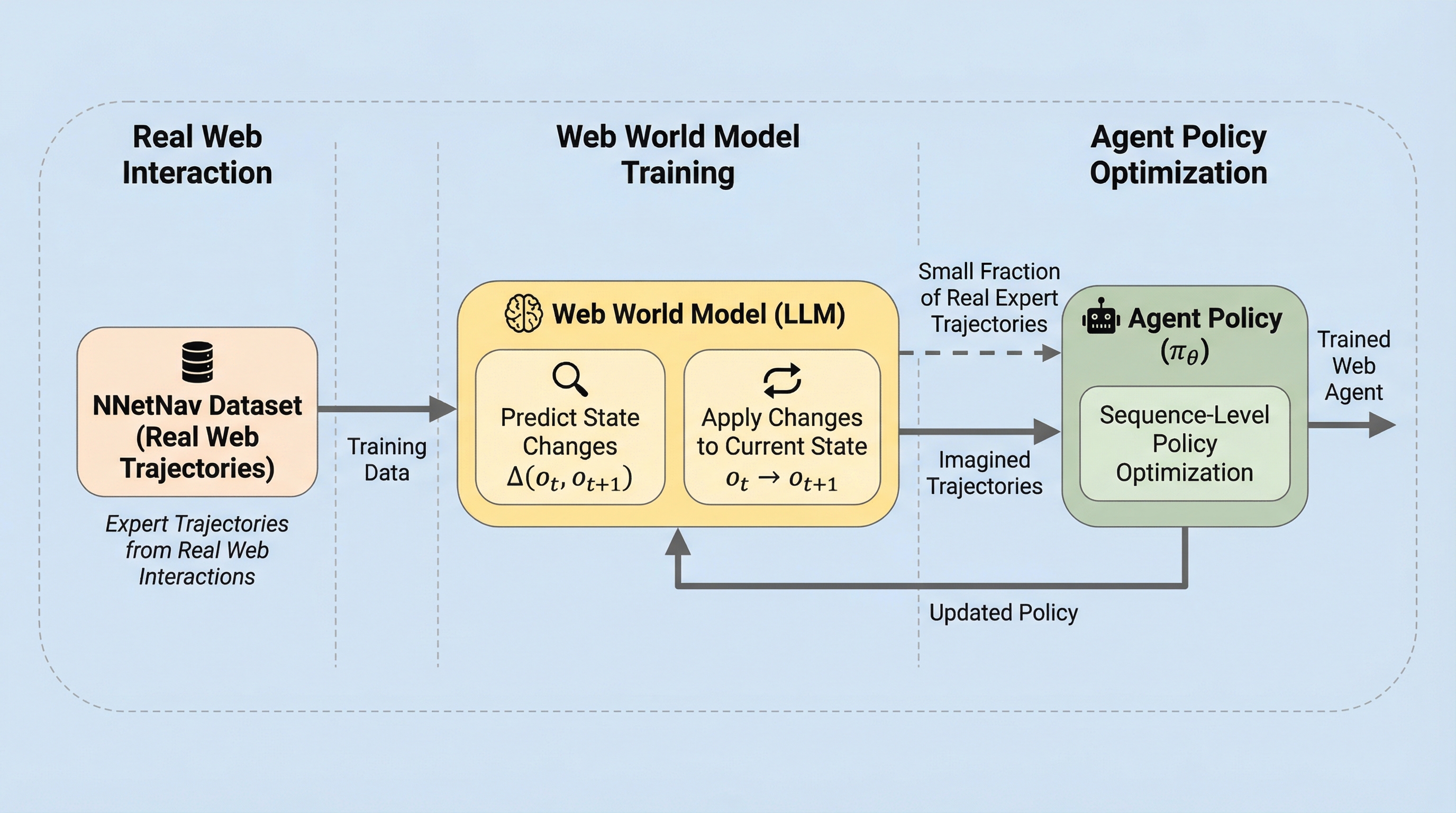
核心:何を提案したのか
本研究では、古典的なモデルベース強化学習を現代のウェブエージェントの視点から再考し、DynaアーキテクチャやDreamerのような想像ベースの学習フレームワークに触発された「DynaWeb」を提案しました。DynaWebは、ウェブ世界モデルを単なる計画やデータ生成のツールから、オンライン強化学習の中核コンポーネントへと昇格させるMBRLフレームワークです。このフレームワークにおいて、世界モデルは制御可能な合成ウェブ環境として扱われ、コストのかかる実際のアクションを代替または補完します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related