ECO: フル精度マスターウェイト不要の量子化トレーニング
大規模言語モデル(LLM)の学習において、メモリ消費の大きな要因となっていた高精度なマスターウェイトを完全に排除し、量子化されたパラメータのみで学習を可能にする「Error-Compensating Optimizer(ECO)」が提案されました。
TL;DR(結論)
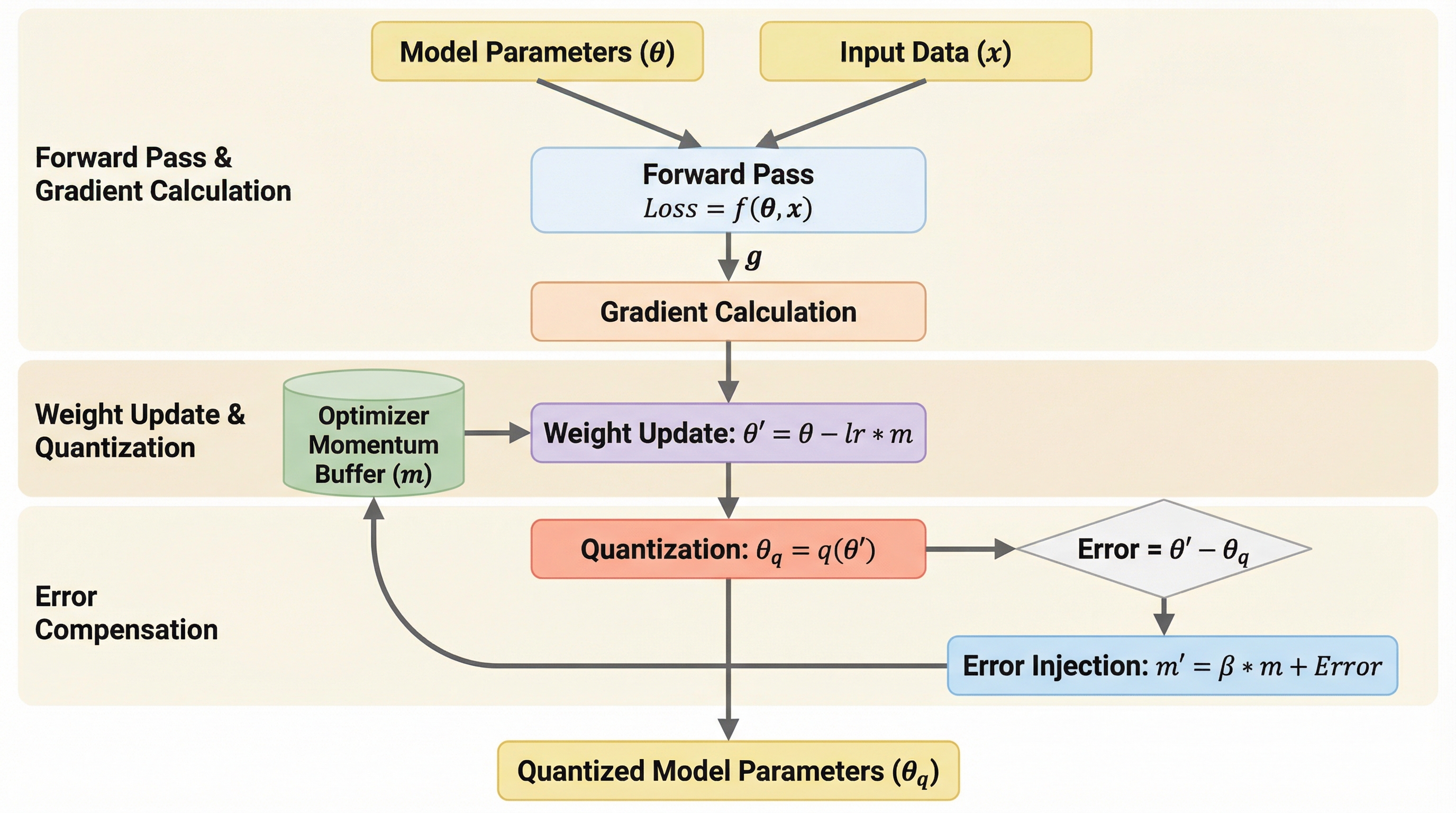
大規模言語モデル(LLM)の学習において、メモリ消費の大きな要因となっていた高精度なマスターウェイトを完全に排除し、量子化されたパラメータのみで学習を可能にする「Error-Compensating Optimizer(ECO)」が提案されました。 この手法は、各ステップで発生する量子化誤差をオプティマイザのモーメンタムバッファに直接注入することで、追加のメモリを一切消費せずに誤差フィードバックループを形成し、微小な更新情報の損失を防ぐ画期的な仕組みを持っています。 実験では、FP8やINT4を用いたLLMの学習において、マスターウェイトを用いる従来手法と同等の精度を維持しながら、静的メモリ使用量を最大25%削減し、メモリ効率と精度のトレードオフを大幅に改善することに成功しました。
なぜこの問題か
大規模言語モデル(LLM)の学習をスケールアップさせる際には、膨大な計算コストとメモリ使用量が大きな障壁となります。モデルのパラメータ数が数十億から数兆へと増加するにつれて、学習時のメモリ容量がボトルネックとなっており、これを解決するために低精度な量子化技術が注目されてきました。近年の研究では、FP8やそれ以下の精度を用いることで、アクティベーションメモリの削減や学習の加速が可能になっていますが、依然として「マスターウェイト」と呼ばれる高精度なパラメータのコピーを保持し続ける必要があるという課題が残されていました。 マスターウェイトが必要とされる主な理由は、勾配の更新値が低精度フォーマットの離散化の幅よりも小さい場合が多く、量子化されたウェイトに直接更新を適用すると、その更新が消失したり大きな量子化ノイズが発生したりするためです。このため、フォワードパスやバックワードパスを量子化しても、モデルウェイトのメモリ占有量は高精度なベースラインとほとんど変わらないという状況が続いていました。…
核心:何を提案したのか
本研究では、フル精度のマスターウェイトを必要とせずに、正確な量子化トレーニングを可能にする「Error-Compensating Optimizer(ECO)」を提案しています。ECOの核心的なアイデアは、各レイヤーのパラメータを更新した直後に、その更新されたウェイトを量子化し、そこで発生した量子化誤差をオプティマイザのモーメンタムバッファに直接注入するというものです。これにより、現在のステップで失われた更新情報が次以降のステップへと持ち越され、累積的に補償される「エラーフィードバックループ」が形成されます。 この手法の最大の特徴は、追加のメモリを一切必要としない点にあります。通常、エラーフィードバックを実現するためには誤差を保持するための専用バッファが必要になりますが、ECOは既存のモーメンタムバッファを再利用することで、この問題を解決しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related