読んだことすべてを信じてはいけない:誤解を招くツール説明下におけるMCPの挙動の理解と測定
Model Context Protocol(MCP)は、大規模言語モデル(LLM)が自然言語の説明を通じて外部ツールを呼び出すための標準規格ですが、ツールの説明文と実際の実行コードの整合性を強制する仕組みが欠如しています。
TL;DR(結論)
Model Context Protocol(MCP)は、大規模言語モデル(LLM)が自然言語の説明を通じて外部ツールを呼び出すための標準規格ですが、ツールの説明文と実際の実行コードの整合性を強制する仕組みが欠如しています。 本研究では、10,240個の現実のMCPサーバーを調査した結果、約13%に深刻な不一致があり、説明にない特権操作や金融取引、プロセスの強制終了といった隠れたリスクが存在することを明らかにしました。 ツールの人気や「公式」という属性が必ずしも正確な説明を保証するわけではなく、AIエージェントが誤った判断を下す可能性があるため、体系的な監査と透明性の確保が急務であると提言しています。
なぜこの問題か
Model Context Protocol(MCP)は、Anthropic社によって2024年末に導入された、LLMと外部ツールやデータソースを接続するためのオープンな標準規格です。このプロトコルにより、AIエージェントは開発ツール、クラウド管理、金融システムなど、多様な外部システムと自律的に連携できるようになりました。しかし、この柔軟性の裏には、従来のソフトウェアアーキテクチャとは異なる深刻なセキュリティ上の課題が潜んでいます。 従来のAPIやAndroidのようなモバイルプラットフォームでは、明示的な権限チェックやアクセス制御が実行時に強制されます。一方でMCPは、LLMがツールの「説明文」を読み、その意味を解釈して呼び出しを判断するという、自然言語ベースのセマンティックなインターフェースに依存しています。つまり、ツールの説明文が、サーバー、モデル、ユーザーの間の事実上の「行動契約」として機能しているのです。しかし、MCP自体はこの説明文と実際のコードの挙動が一致しているかどうかを確認する仕組みを持っていません。 多くの場合、MCPサーバーはローカル環境で広範なシステム権限を持って実行されます。…
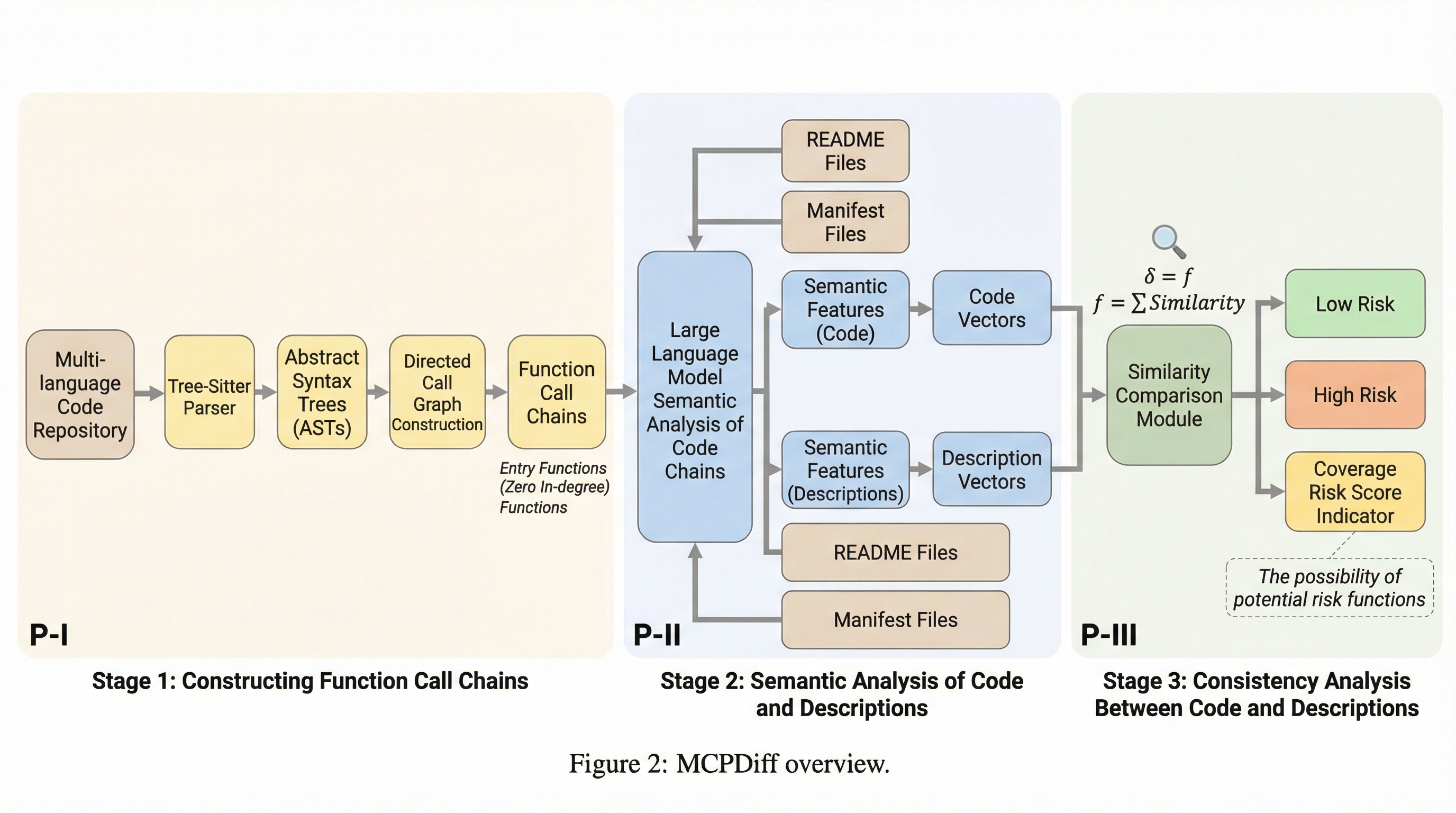
核心:何を提案したのか
本論文の核心的な提案は、MCPエコシステムにおける「説明とコードの不一致」を体系的に特定し、定量化するための自動静的解析フレームワーク「MCPDiFF」の開発です。これは、MCPサーバーが「何を行うと主張しているか」と「実際にコードで何を行っているか」の間のセマンティックな乖離を大規模に検出する初めての試みです。 MCPDiFFは、多言語ソースコードのパース、関数呼び出しチェーンの構築、そして大規模言語モデル(LLM)を活用したセマンティック比較を組み合わせた高度なパイプラインを備えています。このフレームワークの主な目的は、デプロイ前に誤解を招く説明や隠された機能をスケーラブルかつ説明可能な形で検出することにあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related