GAVEL:活性化モニタリングを通じたルールベースの安全性に向けて
従来のLLMセーフティ技術は、表面的なテキストの監視では回避されやすく、内部のアクティベーションを利用する手法も広範なデータセットに依存するため精度や柔軟性、解釈性に課題がありました。本論文は、サイバーセキュリティのルール共有慣行に触発された「GAVEL」という新しいフレームワークを提案し、モデル内部の微細で解釈可能な要素である「認知要素(CE)」を定義して論理的なルールで監視する手法を導入しました。このアプローチにより、モデルの再学習を行うことなく、特定のドメインに合わせた高度な安全策をリアルタイムで構成・更新することが可能になり、AIガバナンスにおける透明性と監査の容易さを大幅に向上させています。
TL;DR(結論)
従来のLLMセーフティ技術は、表面的なテキストの監視では回避されやすく、内部のアクティベーションを利用する手法も広範なデータセットに依存するため精度や柔軟性、解釈性に課題がありました。本論文は、サイバーセキュリティのルール共有慣行に触発された「GAVEL」という新しいフレームワークを提案し、モデル内部の微細で解釈可能な要素である「認知要素(CE)」を定義して論理的なルールで監視する手法を導入しました。このアプローチにより、モデルの再学習を行うことなく、特定のドメインに合わせた高度な安全策をリアルタイムで構成・更新することが可能になり、AIガバナンスにおける透明性と監査の容易さを大幅に向上させています。
なぜこの問題か
大規模言語モデル(LLM)の普及に伴い、有害な動作を防止するためのセーフティガードの重要性が高まっていますが、既存のテキストベースの監視手法には限界があります。攻撃者は表現を言い換えたり難読化したりすることで、表面的なテキスト監視を回避する「表現攻撃」を仕掛けることが可能であり、モデル内部の推論プロセスと表面的なテキストの間に乖離が生じることが問題視されています。これに対処するため、モデル内部の神経活動であるアクティベーションを直接監視する手法が注目されていますが、従来のアプローチには主に3つの大きな欠陥が存在していました。 第一に精度の低さであり、既存の手法は「サイバー犯罪」や「誤情報」といった広範なカテゴリのデータセットで学習されるため、無害な議論を誤って検知する誤検知率が高いという課題があります。例えば、人種差別的なコンテンツを防ぐために学習された検知器が、民族文化に関する無害な議論を誤ってフラグ立てしてしまうことがあります。第二に柔軟性の欠如で、特定の企業の内部ポリシーや知的財産保護といった細かな制約を適用するには、その都度膨大なデータ収集と再学習が必要となり、迅速な展開が困難でした。…
核心:何を提案したのか
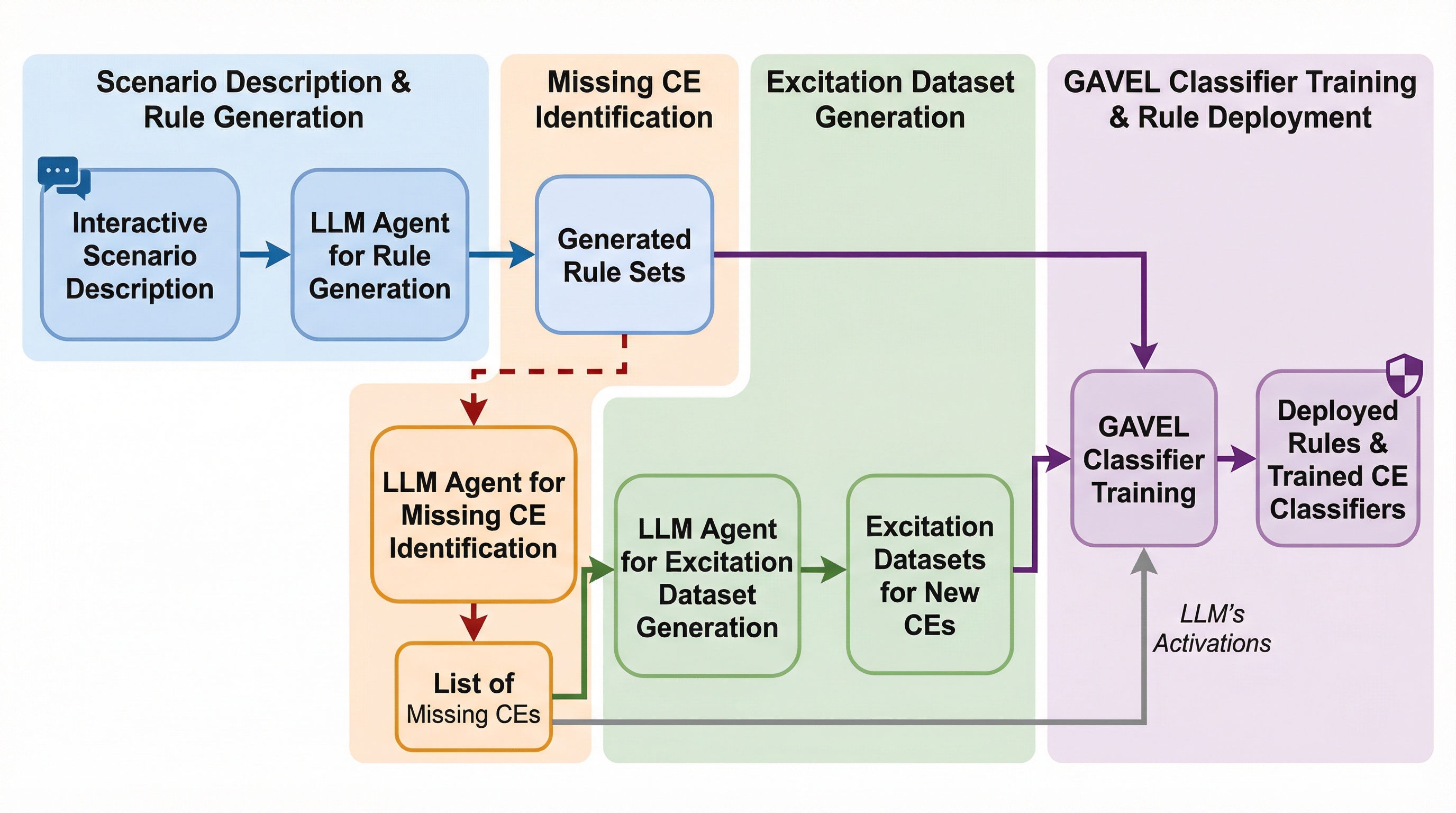
本論文では、サイバーセキュリティの分野で長年成果を上げてきたルール共有の慣行に触発された、新しいAIセーフティのパラダイムを提案しています。具体的には、SnortやYARA、OSSECといったツールが脅威検知のためにルールセットを共有し、コミュニティ全体で標準化されたセキュリティ監査を可能にしているエコシステムをAIセーフティに応用することを目指しています。この動機に基づき、モデルのアクティベーションを「認知要素(Cognitive Elements、以下CE)」としてモデリングする手法を導入しました。 CEとは、モデルの動作、タスク、または振る舞いの中レベルの側面を捉える、解釈可能で微細なアクティベーションレベルのプリミティブです。例えば、「脅迫を行う」「支払いを処理する」「人間に成りすます」「ユーザーにどこかへ行くよう指示する」といった具体的な要素がこれに該当します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related