あらゆるモダリティにおけるマルチベクター索引圧縮
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。
TL;DR(結論)
- テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。
- 本論文は、クエリが不明な索引作成時点でも使える「クエリ非依存」の圧縮として、SeqResize・MemTok・H-Pool・AGC(注意誘導クラスタリング)を同一の「固定ベクトル予算」で比較し、AGCで重要領域を中心にまとめる設計を示します。
- BEIR・ViDoRe・MSR-VTT・MultiVENT 2.0での評価では、AGCが学習型圧縮(SeqResize、MemTok)を一貫して上回り、非学習型の階層クラスタリング(H-Pool)より索引サイズ調整の自由度が高く、未圧縮索引に対しても競争的または改善する場合があると報告されています。
なぜこの問題か
オンライン情報は文章だけでなく、画像を含む記事、図表の多い文書、動画、音声などの混在へ広がっており、検索システムには「どのモダリティでも同じ枠組みで索引化して探せること」が求められます。そこで有力なのが、クエリも文書も複数ベクトルで表し、細粒度の一致を拾うlate interactionの考え方です。一方で、この方式は文書側のトークン(ベクトル)数が増えるほど、索引の保存コストとクエリ時の照合コストが文書長に比例して増えます。特にマルチモーダル文書は、時間方向のフレーム列や音声区間などが加わるため、表現が数千トークン規模になりやすく、直線的な増加が障壁になりやすいとされています。本文抜粋では、マルチベクトル設定で動画1本の索引が10MBになり得る例や、YouTubeの動画数推定(140億本)を用いた索引総量の試算(140ペタバイト規模)が示され、保存の現実的制約が強調されています。さらに重要なのは、長い表現を作っても実際の評価で使われる索引トークンがごく一部にとどまる場合がある点です。…
核心:何を提案したのか
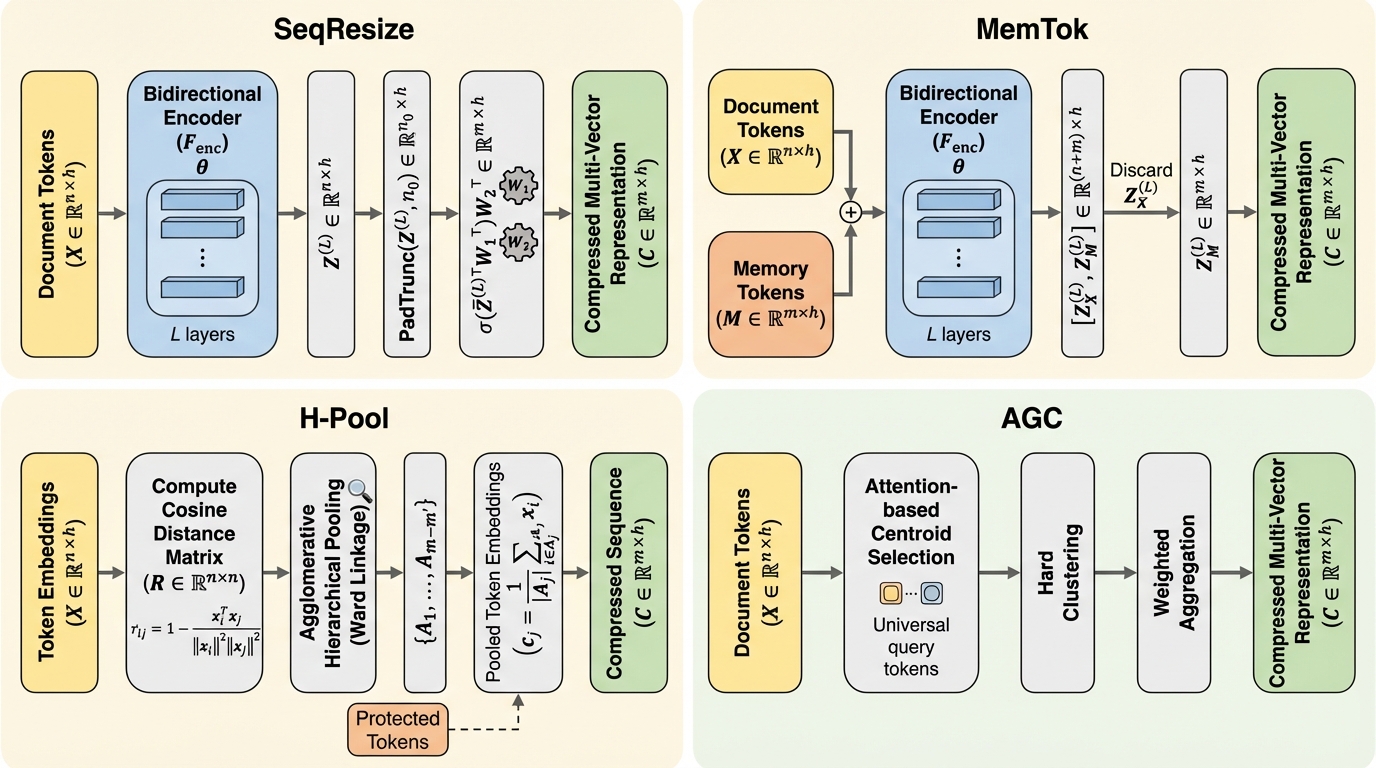
本論文の中心は、late interaction検索における文書側マルチベクトル表現を「固定ベクトル予算」の下で圧縮するために、クエリ非依存の複数手法を整理し、マルチモーダルでも堅牢に動く新手法AGC(attention-guided clustering)を提示した点です。枠組みとしては、クエリ表現は長さを制限せず、文書表現だけを元の文書長に関わらず常に (m) 個のベクトルへ写像することを要求します。これにより、索引の保存量とクエリ時コストが文書長から切り離され、ストレージや計算の制約に合わせて「どこまで圧縮するか」を設計上選びやすくなります。比較対象として、既存系のSeqResize、MemTok、H-Poolが扱われます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related