Scale Can’t Overcome Pragmatics:VLMの推論不足は「報告バイアス」が生む
視覚言語モデルの推論不足は、モデルの大きさよりも、人間が画像説明で省略しがちな情報に強く左右されます。空間・時間・否定・カウントの4種類を軸に見ると、学習コーパスの報告バイアスがそのまま性能の穴になっており、スケール拡大や多言語化だけでは埋まりません。
論文図解
TL;DR(結論)
- 視覚言語モデルの推論不足は、単純な能力不足というより、人間が画像説明で重要な推論情報を省きがちな「報告バイアス」と強く結びついています。
- 著者らは空間・時間・否定・カウントの4種類に注目し、学習コーパスでの表現不足と、モデルの弱い性能が対応していることを示しました。つまり、どの推論が苦手かは偶然ではなく、学習データに何が書かれていないかとかなり対応しています。
- スケール拡大や多言語化だけでは根本解決せず、改善の本丸は「どの情報を書かせるか」を意識したデータ収集設計にあります。
なぜこの問題か
VLM の弱さを議論するとき、モデル構造や最適化だけが原因として語られがちです。しかし、画像と言語を結びつける学習では、どんなペアを大量に集めても、そこに必要な推論表現がほとんど含まれていなければ、モデルは推論を覚えにくいままです。ここで重要なのは、データ量ではなく、データが持っている会話上の偏りです。
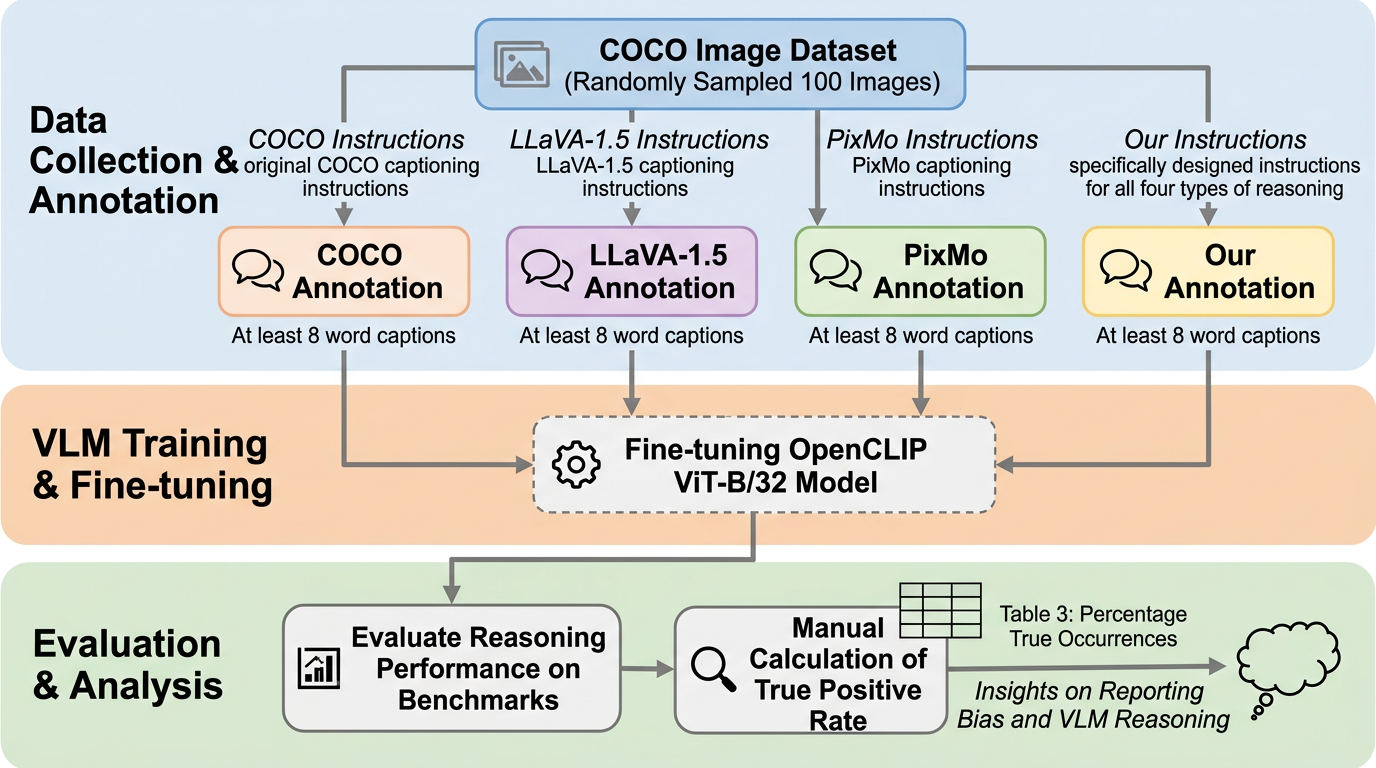
核心:何を提案したのか
著者らの提案は、新しい巨大モデルを作ることではありません。中心にあるのは、報告バイアスという仮説を4種類の推論能力に分解し、それを測るベンチマークと、学習データ側の出現頻度分析を対応づけることです。つまり、モデルの弱さをただ列挙するのではなく、「なぜその能力だけ学習されにくいのか」をデータ分布の観点から説明する枠組みを出しています。
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related