PhaseCoder:マルチモーダルLLMのためのマイク配置に依存しない空間オーディオ理解
PhaseCoderは、マイクの個数や配置といった幾何学的な条件に依存することなく、多チャンネルの音声データから豊かな空間情報を抽出することが可能な、トランスフォーマーのみで構成された画期的な空間オーディオエンコーダである。
TL;DR(結論)
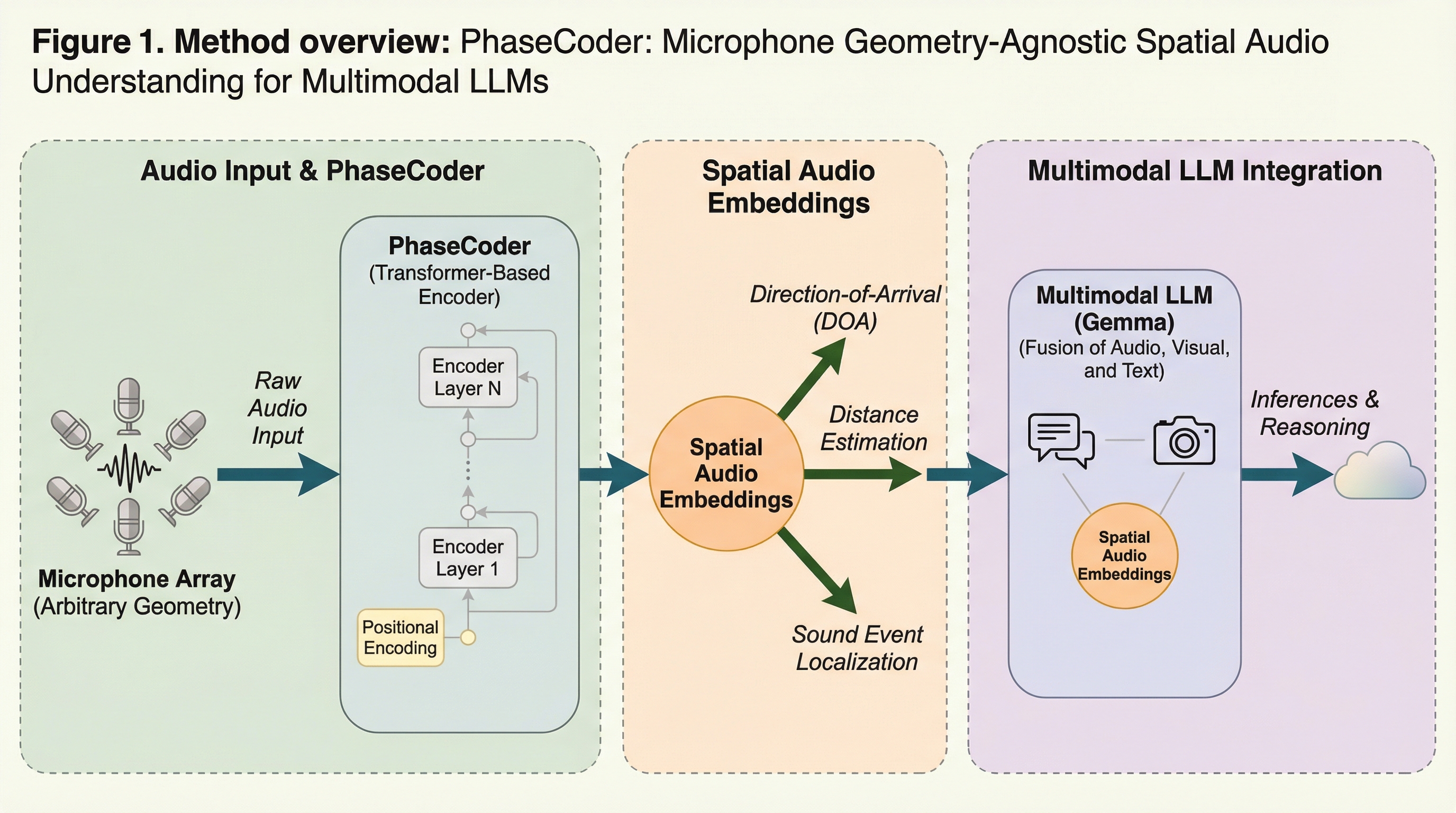
PhaseCoderは、マイクの個数や配置といった幾何学的な条件に依存することなく、多チャンネルの音声データから豊かな空間情報を抽出することが可能な、トランスフォーマーのみで構成された画期的な空間オーディオエンコーダである。 本手法は生の多チャンネル音声信号と各マイクの3次元座標を直接入力として受け取り、ノイズ除去や音源の定位、距離の推定を同時に行いながら、デバイスの形状に縛られない汎用的な「空間オーディオトークン」を生成する仕組みを持つ。 このトークンを用いてGemma 3n LLMを学習させることにより、特定の場所にいる話者の言葉だけを書き起こす「ターゲット転写」や、複数の音源間の位置関係を解釈する複雑な空間推論など、従来のモノラル音声処理では到達できなかった高度な知能を実現している。
なぜこの問題か
現在のマルチモーダル大規模言語モデル(LLM)は、音声を単一チャンネルのモノラルストリームとして処理しており、現実世界の理解に不可欠な豊かな空間情報を活用できていないという大きな課題がある。人間やフクロウなどの生物は、空間的な音響情報を利用して騒音下での会話を成立させるカクテルパーティー効果を享受したり、獲物の正確な位置特定を行ったりしているが、現在のAIはこの能力を欠いている。空間オーディオの理解は、ロボット工学における身体化された知能や、次世代のAIアシスタントが周囲の状況を正確に把握するために極めて重要な要素である。現代の多くのデバイスには安価で小型な全指向性マイクが複数搭載されているが、その潜在能力は十分に引き出されていないのが現状である。 既存の空間オーディオモデルの多くは、特定のマイク配置に固定されており、異なるデバイスへの展開が困難であるという致命的な制約がある。新しいデバイスが登場するたびに、そのマイク配置に合わせてエンコーダを再学習させる必要があり、これはLLMが持つ本来の汎用性を著しく損なうものである。…
核心:何を提案したのか
本研究では、マイクの配置に依存しないトランスフォーマーのみで構成された空間オーディオエンコーダである「PhaseCoder」を提案している。この名称は、空間情報が主にマイク間のわずかな位相差にエンコードされているという音響学的な事実に由来している。PhaseCoderは、生の多チャンネル音声とマイクの座標を直接入力として受け取り、音源の定位や距離の推定を行うとともに、堅牢な空間埋め込みを生成する能力を持つ。このエンコーダが生成する「空間オーディオトークン」は、マイクの構成に関わらず一貫した表現を提供するため、下流の様々なタスクに非常に適している。 研究チームは、この空間トークンを既存のモノラル音声トークンと組み合わせて処理できるように、40億パラメータを持つGemma 3n LLMをファインチューニングした。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related