PACE:事前学習済みオーディオ継続学習
音声の事前学習モデルは、画像用モデルとは異なり、構造化された意味情報よりも低レベルなスペクトル情報に強く依存しているため、既存の持続的学習手法を適用するとセッション間で極めて大きな表現シフトが発生し、深刻な破滅的忘却を引き起こすことが本研究の分析によって解明された。
TL;DR(結論)
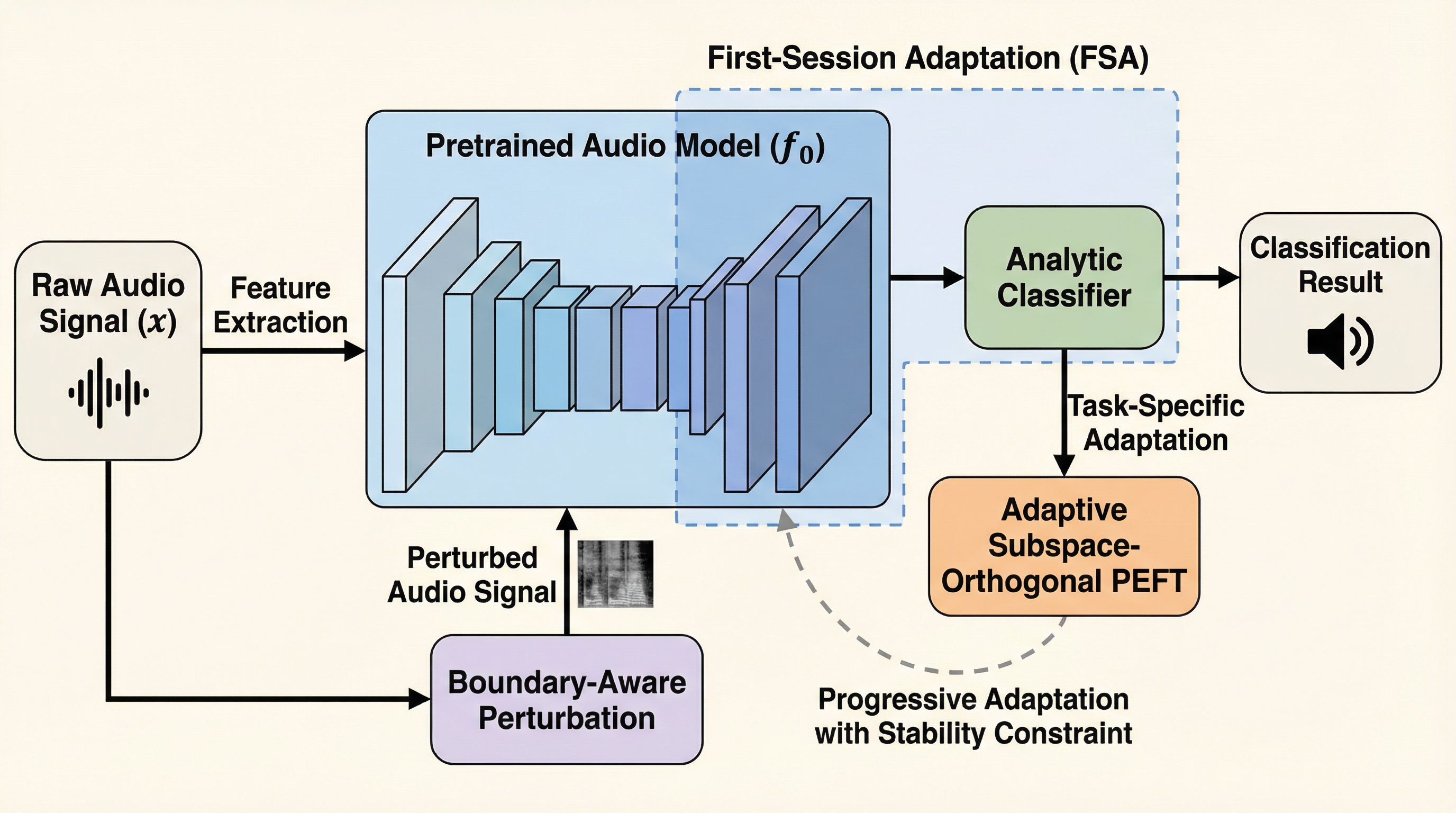
音声の事前学習モデルは、画像用モデルとは異なり、構造化された意味情報よりも低レベルなスペクトル情報に強く依存しているため、既存の持続的学習手法を適用するとセッション間で極めて大きな表現シフトが発生し、深刻な破滅的忘却を引き起こすことが本研究の分析によって解明された。 この課題に対し、初期セッションでの深い層の選択的適応(FSA)と、数学的に知識の干渉を防ぐ部分空間直交PEFTを用いた複数セッション適応(MSA)、さらに境界認識型スペクトル摂動を組み合わせた新フレームワーク「PACE」を提案し、リプレイデータなしでの学習を実現した。 6つの多様な音声ベンチマークを用いた検証の結果、PACEは既存の最先端手法を大幅に上回る精度を達成し、特に話者識別や楽器認識などの細かい粒度のタスクにおいて顕著な改善を示し、全てのデータを一度に学習する共同学習の性能限界に肉薄する極めて高い堅牢性を証明した。
なぜこの問題か
音声データは、人間のコミュニケーションや環境理解において極めて重要な情報源であり、会話の解析、音楽の分類、環境音の検知など、その応用範囲は多岐にわたる。近年、大規模なデータセットを用いた自己教師あり学習などの事前学習済みモデルが登場したことで、音声理解の能力は飛躍的に向上したが、現実世界のシナリオではデータの分布が時間とともに絶えず変化し続けるため、これらのモデルは新しい知識を学習する際に過去の知識を急速に失ってしまう「破滅的忘却」という深刻な問題に直面している。画像認識の分野では、パラメータ効率の良い微調整(PEFT)が持続的学習に有効であることが証明されているが、本研究の分析により、これらの手法を音声モデルに直接適用しても十分な性能が得られないことが明らかになった。この性能低下の根本的な原因は、音声バックボーンが構造化された意味情報よりも、低レベルなスペクトル細部や時間・周波数のパターンに焦点を当てるという独自の特性にある。 多くの音声モデルはスペクトログラムの再構成を目的として事前学習されているため、下流タスクで要求される高レベルな意味的分類目標との間に深刻な不一致が生じているのである。…
核心:何を提案したのか
本研究では、事前学習済み音声モデルの持続的学習における独自の課題を解決するために、PACE(Pretrained Audio Continual Learning)という革新的なフレームワークを提案した。PACEは、事前学習された表現を下流の持続的学習目標と段階的に再調整するための包括的なアプローチを採用している。まず、初期セッションの適応(FSA)において、モデルの全ての層を一律に更新するのではなく、意味的に重要な深い層のみを選択的にLoRAモジュールで調整する戦略をとる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related