PhaseCoder:マルチモーダルLLMのためのマイク配置に依存しない空間オーディオ理解
現在のマルチモーダル大規模言語モデル(LLM)は音声をモノラルとして処理しており、音の方向や距離といった空間情報の活用が困難であったが、本研究ではマイクの数や幾何学的配置に依存せず、あらゆるデバイスで利用可能な空間オーディオエンコーダ「PhaseCoder」を提案した。
TL;DR(結論)
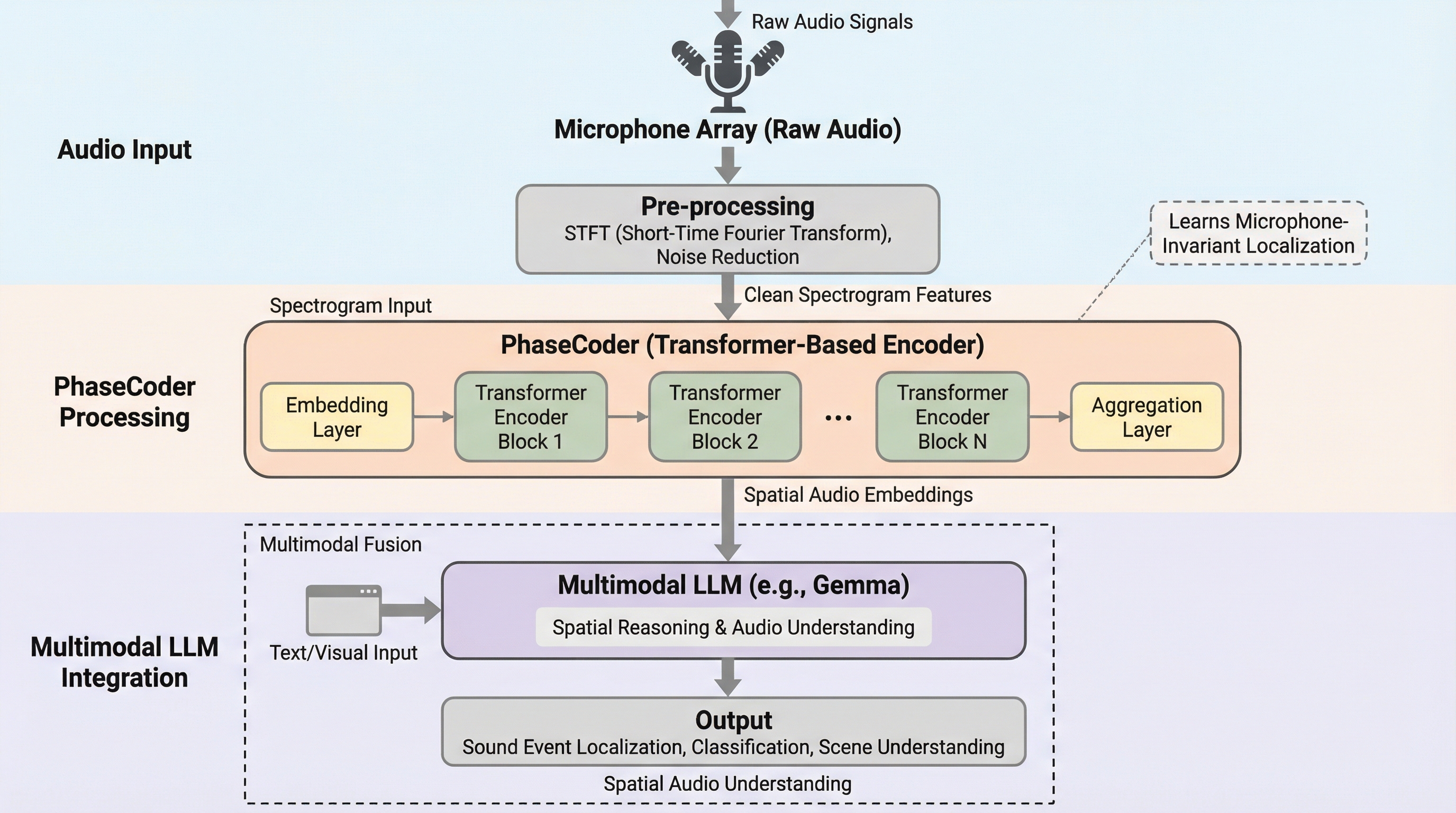
現在のマルチモーダル大規模言語モデル(LLM)は音声をモノラルとして処理しており、音の方向や距離といった空間情報の活用が困難であったが、本研究ではマイクの数や幾何学的配置に依存せず、あらゆるデバイスで利用可能な空間オーディオエンコーダ「PhaseCoder」を提案した。 PhaseCoderは、多チャンネルの生音声と各マイクの座標を直接入力として受け取り、トランスフォーマーのみの構成でノイズ除去や音源定位を行い、マイク配置に縛られない頑健な「空間オーディオトークン」を生成してLLMに統合することで、空間的な文脈を理解した推論を可能にする。 この空間トークンをGemma 3nモデルに統合して微調整することで、特定の方向からの音声のみを書き起こす「ターゲット書き起こし」や複雑な空間推論をLLMで初めて実現し、マイク配置に依存しない音源定位ベンチマークにおいて最高水準の性能を達成することに成功した。
なぜこの問題か
現在のマルチモーダル大規模言語モデル(LLM)は、話し言葉の内容を理解する能力には極めて長けているが、その音声が「どこから聞こえてくるか」という空間的な情報については、事実上の「盲目」状態にある。人間や動物にとって、音の方向や距離を把握する空間オーディオの理解は、騒がしい環境で特定の声を聞き取るカクテルパーティー効果や、獲物の位置を特定するために不可欠な生存能力である。ロボット工学や次世代のAIアシスタントといった、物理的な実体を持つAI(エンボディドAI)にとっても、周囲の状況を把握するために空間的な認識は極めて重要な要素となる。現代の多くのデバイスには、安価で小型な無指向性マイクが複数搭載されており、空間データを取得するためのハードウェア的な基盤は既に整っている。しかし、これらのマイクから得られる情報をLLMが直接理解し、推論に活用する手法は十分に確立されていない。 既存の空間オーディオモデルにおける最大の課題は、マイクの数や配置(幾何学的構造)が固定されていることを前提としている点にある。…
核心:何を提案したのか
本研究では、マイクの幾何学的配置に依存しないトランスフォーマーのみで構成された空間オーディオエンコーダ「PhaseCoder」を提案している。この名称は、空間情報が主にマイク間のわずかな位相差にエンコードされているという物理的事実に由来している。PhaseCoderは、多チャンネルの生音声データと各マイクの相対的な座標を直接入力として受け取り、音源の定位、距離の推定、およびノイズ除去を同時に実行する。このエンコーダの最大の特徴は、マイクの数や配置が異なる多様なデバイスに対して、単一のモデルで対応できる汎用性にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related