Qwen3-ASR テクニカルレポート
Qwen3-ASRは、52の言語と方言に対応する1.7Bおよび0.6Bの音声認識モデルと、11言語に対応した世界初のLLMベース非自己回帰型強制アライメントモデルで構成される強力な製品群である。
TL;DR(結論)
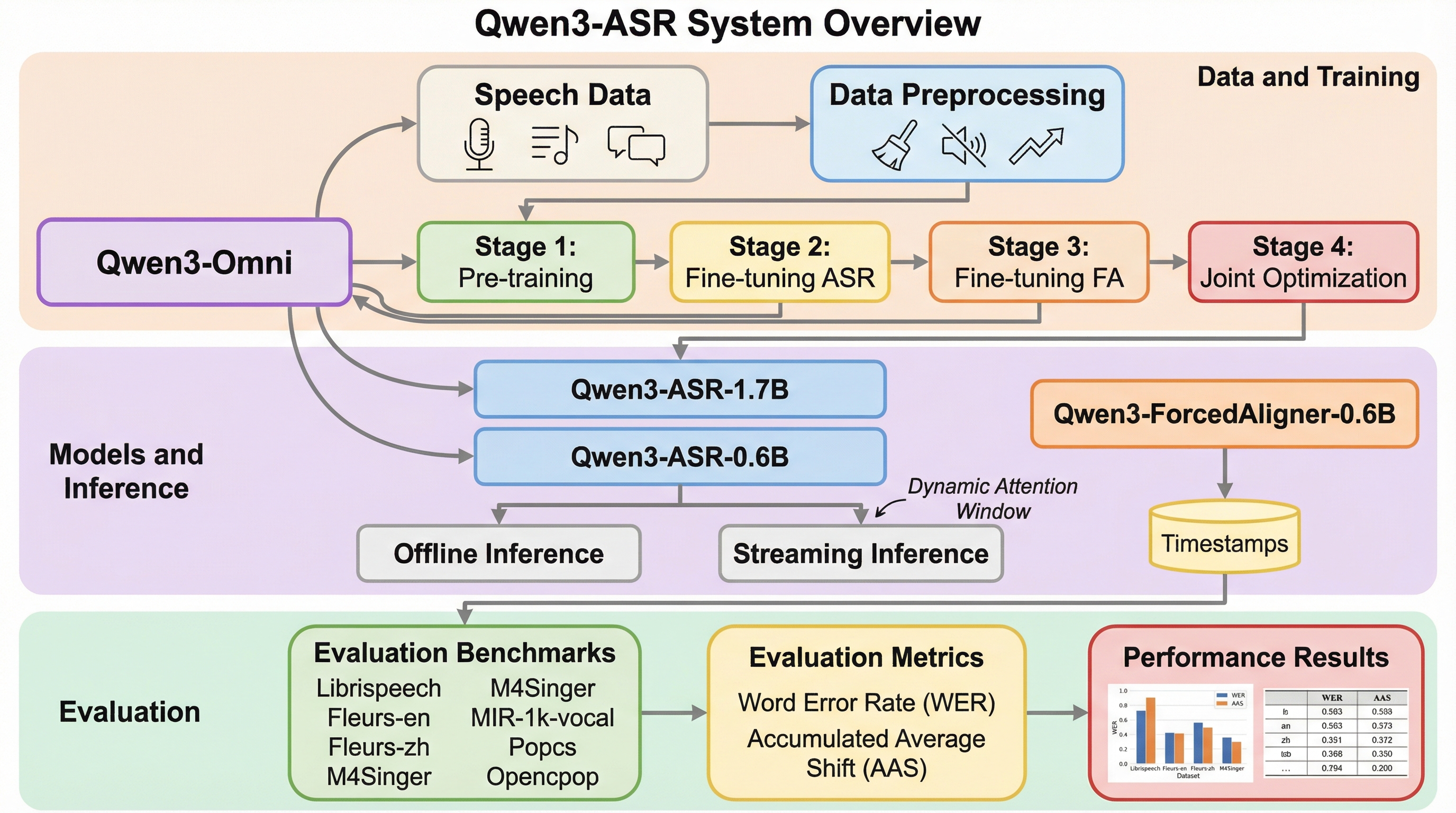
Qwen3-ASRは、52の言語と方言に対応する1.7Bおよび0.6Bの音声認識モデルと、11言語に対応した世界初のLLMベース非自己回帰型強制アライメントモデルで構成される強力な製品群である。 4000万時間の疑似ラベルデータと3兆トークンのマルチモーダル学習、さらにGSPOによる強化学習を組み合わせることで、歌声や極端なノイズ環境下でも商用APIに匹敵する極めて高い堅牢性と精度を実現した。 0.6Bモデルは1秒間で2000秒分の音声を処理可能な圧倒的な推論効率を誇り、強制アライメントモデルはタイムスタンプのズレを従来手法から最大77%削減することに成功し、Apache 2.0ライセンスで公開されている。
なぜこの問題か
音声認識(ASR)の技術体系は、従来のトランスデューサーやAEDといったエンドツーエンドのパラダイムから、大規模音声言語モデル(LALM)のパラダイムへと劇的な転換期を迎えている。従来のモデルは音響パターンのマッチングに過度に依存しており、長時間の書き起こしや複雑なノイズ環境、固有名詞の認識、そして多様な方言のカバーといった実世界の課題に対して限界があった。LALMアプローチを採用することで、大規模言語モデルが持つ高度な言語モデリング能力と広範な世界知識を直接活用できるようになり、音声信号を単なる音の並びとしてではなく、文脈を伴う意味のある情報として理解することが可能になる。これにより、従来のモデルでは困難であった自然な言語理解に基づいた書き起こしが実現される。 また、実用的な音声処理システムにおいては、単にテキストを出力するだけでなく、字幕生成や動画編集のために正確なタイムスタンプを付与することが強く求められている。これまではCTCやCIFといった技術を用いた後処理としてタイムスタンプを予測していたが、精度や処理速度の面で課題が残されていた。…
核心:何を提案したのか
本報告では、強力な音声理解能力を持つQwen3-Omniを基盤とした「Qwen3-ASR」ファミリーを提案している。このファミリーは、52の言語と方言に対応し、言語識別(LID)機能を内蔵した2つの音声認識モデル(Qwen3-ASR-1.7BおよびQwen3-ASR-0.6B)と、11言語に対応した軽量な多言語強制アライメントモデル(Qwen3-ForcedAligner-0.6B)で構成される。1.7BモデルはオープンソースのASRモデルとして最高水準の性能を達成しており、GPT-4oやGemini 2.5 Proといった商用の最先端APIと競合できる実力を持つ。一方、0.6Bモデルはモデルサイズと精度のバランスを最適化しており、デバイス上での展開や大規模なデータ処理に極めて適している。 特筆すべき提案は、世界初となる大規模言語モデル(LLM)ベースの非自己回帰型強制アライメントモデルの導入である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related