テキストデノイジングを通じたLLMベースのASRにおけるテキストのみの適応
大規模言語モデル(LLM)を活用した音声認識システム(ASR)において、音声とテキストが対になっていないテキストのみのデータを用いて新しいドメインに適応させることは、音声とテキストの整合性を維持する観点から困難な課題であった。
TL;DR(結論)
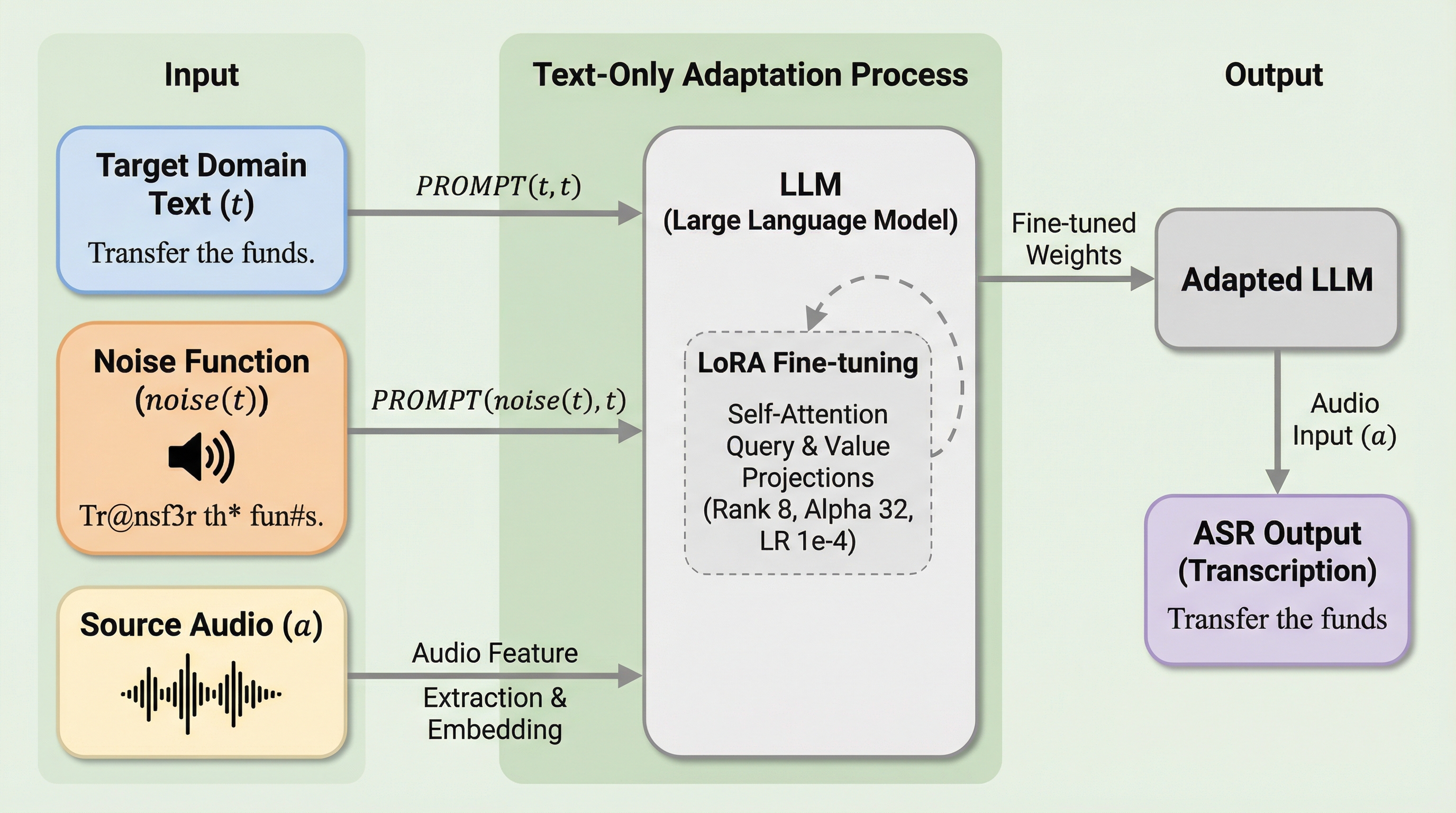
大規模言語モデル(LLM)を活用した音声認識システム(ASR)において、音声とテキストが対になっていないテキストのみのデータを用いて新しいドメインに適応させることは、音声とテキストの整合性を維持する観点から困難な課題であった。本研究では、この問題をテキストのデノイジング(ノイズ除去)タスクとして再定義し、LLMがノイズの混じった入力からクリーンな書き起こし文を復元するように学習させる新しい手法を提案している。 提案手法は、音声プロジェクターが生成する表現を「ノイズを含んだテキスト」として解釈し、ソースドメインの音声データとターゲットドメインのノイズ付きテキストデータを混合してバッチを構成する軽量な学習戦略を採用している。これにより、モデルのアーキテクチャを変更したり追加のパラメータを導入したりすることなく、音声とテキストのクロスモーダルな整合性を保ちながら、未知のドメイン特有の語彙や表現を効果的に学習させることが可能となった。 顧客対応電話や会議動画などの現実的なデータセットを用いた広範な評価の結果、提案手法は従来の最先端手法を凌駕し、最大で22.1%の相対的な単語誤り率(WER)の改善を達成した。特に音声データが収集困難な専門領域において、入手しやすいテキストデータのみでASRの性能を大幅に向上させることができるため、実用的な音声駆動型アプリケーションや会話型AIの発展に寄与する重要な成果であると言える。
なぜこの問題か
近年、大規模言語モデル(LLM)に音声能力を統合し、シームレスな音声対話や音声駆動型アプリケーションを実現することへの関心が高まっている。この文脈において、LLMベースの音声認識(ASR)システムは、強力な学習済み音声エンコーダとLLMを学習可能なプロジェクション層で結合することで、高い書き起こし精度を実現する実用的かつ計算効率の良い選択肢として浮上している。しかし、これらのシステムを新しいドメインに適用する場合、通常は大量の音声とテキストのペアデータが必要となるが、現実の運用環境ではそのようなリソースの収集は非常に高コストであり、専門的な領域になればなるほどデータの入手は困難になる。 一方で、テキストのみのデータはインターネット上や既存の文書から比較的容易に、かつ大量に入手可能であるため、テキストのみを用いたドメイン適応技術への期待が非常に大きい。しかし、既存の研究では、単純にターゲットドメインのテキストでLLMをファインチューニングすると、学習済みの音声とテキストの間の重要な整合性が破壊され、認識性能が逆に低下するという「破滅的忘却」の問題が発生することが指摘されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related