asr_eval:マルチリファレンスおよびストリーミング音声認識評価のためのアルゴリズムとツール
音声認識(ASR)の評価において、表記揺れや聞き取り困難な箇所を柔軟に扱うための新アルゴリズム「MWER」と、包括的な評価ライブラリ「asr_eval」が提案されました。 MWERは、複数の正解候補を波括弧で記述するマルチリファレンス構文、任意の挿入を許容するワイルドカード、ハルシネーションによる指標の歪みを抑える緩和ペナルティを導入し、より人間に近い評価を実現します。 ロシア語の長尺データセットを用いた検証では、従来のテキスト正規化に頼る評価が、モデルが特定の表記規則に過剰適合することで生じる「指標の錯覚」を引き起こし、真の性能向上を誤認させるリスクがあることが示されました。
TL;DR(結論)
音声認識(ASR)の評価において、表記揺れや聞き取り困難な箇所を柔軟に扱うための新アルゴリズム「MWER」と、包括的な評価ライブラリ「asr_eval」が提案されました。 MWERは、複数の正解候補を波括弧で記述するマルチリファレンス構文、任意の挿入を許容するワイルドカード、ハルシネーションによる指標の歪みを抑える緩和ペナルティを導入し、より人間に近い評価を実現します。 ロシア語の長尺データセットを用いた検証では、従来のテキスト正規化に頼る評価が、モデルが特定の表記規則に過剰適合することで生じる「指標の錯覚」を引き起こし、真の性能向上を誤認させるリスクがあることが示されました。
なぜこの問題か
音声認識システムの性能を測定する際、単一の正解テキスト(グラウンドトゥルース)と比較する従来の手法には限界があります。特に、数字の表記(「4」か「four」か)、通貨、単位、あるいは言い淀みや重複、語尾の屈折など、正解が一つに定まらないケースが多々存在します。これまではテキスト正規化によってこれらの差異を吸収しようとしてきましたが、正規化モデルはすべての言語で完璧に機能するわけではなく、特に語形成が豊かなロシア語などの非ラテン言語においては、正規化だけでは対応できない複雑な変化が頻発します。また、不明瞭な音声やノイズが混入した長尺の音声データでは、アノテーターが無理に文字起こしを行うことで、特定のモデルやチェックポイントに有利なバイアスが生じるリスクがあります。 さらに深刻な問題として、モデルの微調整(ファインチューニング)の過程で、モデルがデータセット固有の表記規則やアノテーターの癖に適応してしまう現象が確認されています。…
核心:何を提案したのか
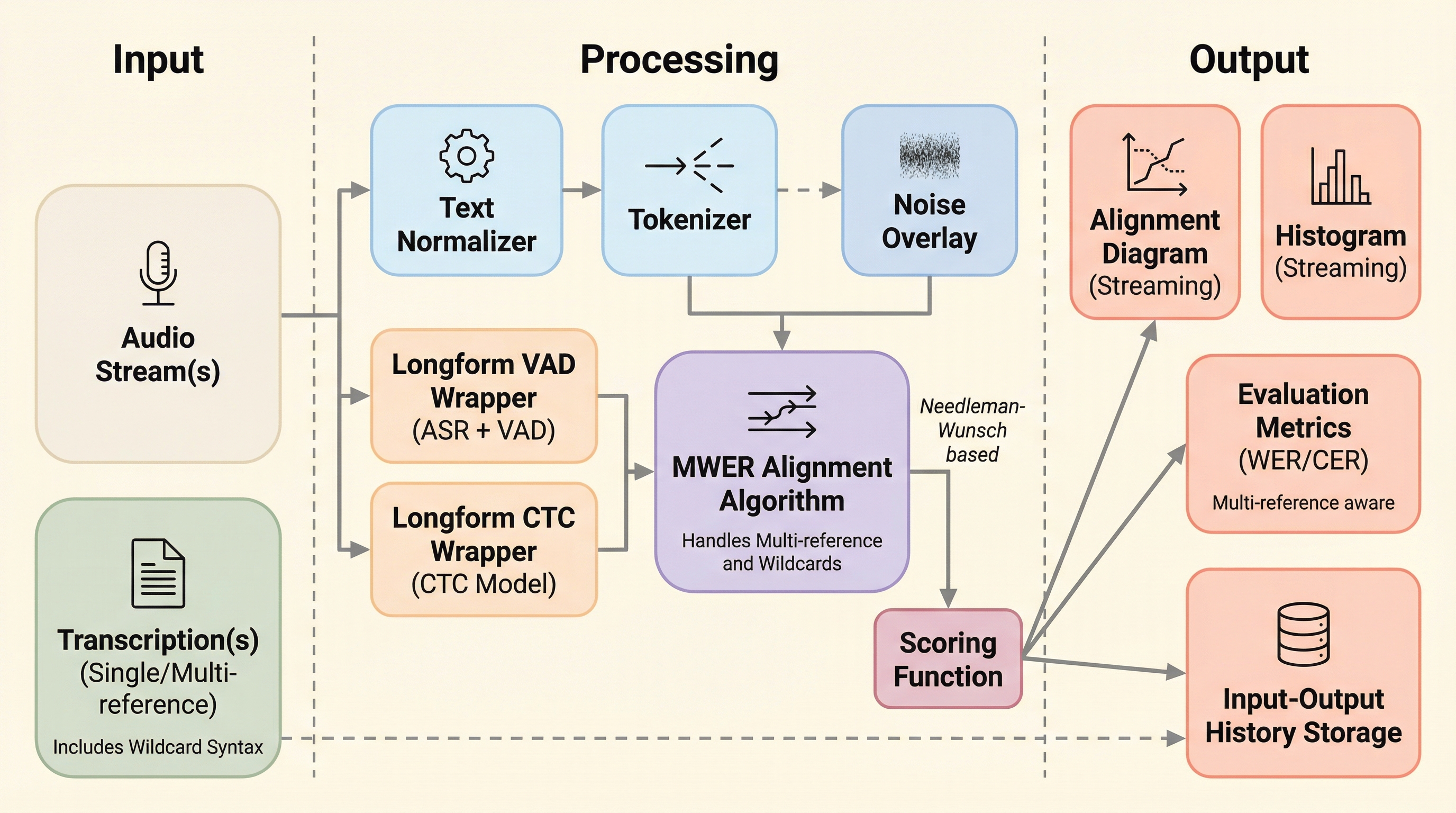
本論文では、音声認識評価の精度と信頼性を抜本的に高めるために、新しい文字列アライメントアルゴリズム「MWER」と、包括的な評価ツールキット「asreval」を提案しています。MWERは「Multi-reference(複数参照)」「Wildcard(ワイルドカード)」「Enhanced alignment(強化されたアライメント)」「Relaxed insertion penalty(緩和された挿入ペナルティ)」の頭文字をとったものです。このアルゴリズムは、複数の正解候補を同時に保持できる有向非巡回グラフ(DAG)のような構造をサポートし、任意の長さの挿入を許容するワイルドカード記号を扱うことができます。これにより、アノテーターは「どちらの表記も正解」という箇所を波括弧で列挙できるようになり、選択バイアスを排除することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related