大型言語モデルの制御におけるスタイルベクトルの有効性:人間による評価
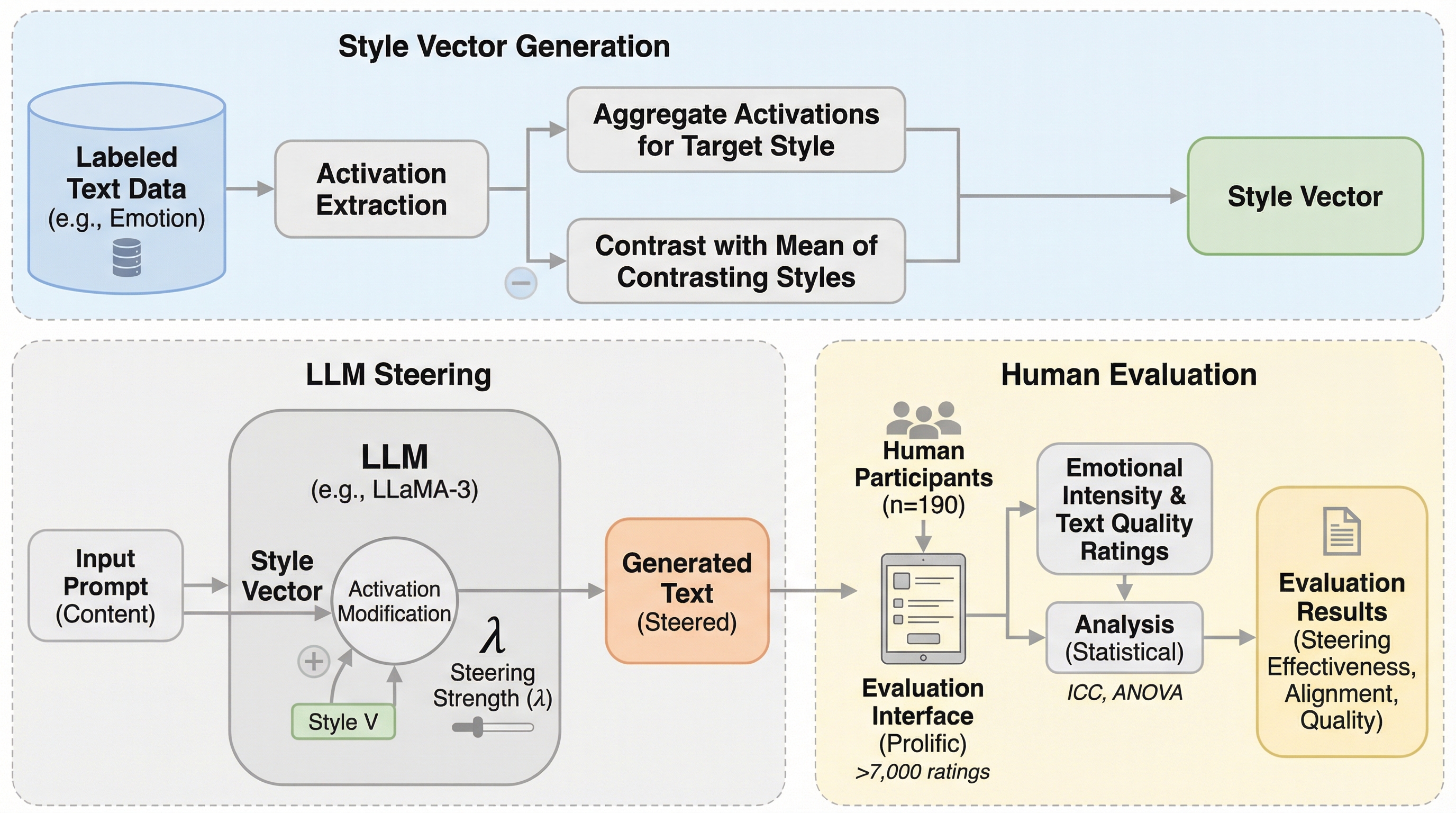
大型言語モデルの内部活性化を直接操作するアクティベーション・ステアリングは、追加学習や複雑なプロンプトを必要とせずに、出力の感情トーンを精密かつ段階的に制御できる軽量な手法である。本研究では、190人の参加者から7,000件以上の評価を収集する初の大規模な人間評価を実施し、人間がモデルの感情変化を明確に知覚できること、および自動評価指標と人間の直感が平均r=0.776という高い相関を示すことを証明した。特定の強度(λ≈0.15)でステアリングを行うことで、テキストの読みやすさを維持したまま「嫌悪」や「恐怖」などの感情を効果的に増幅できる一方、「驚き」の制御は比較的困難であるという感情ごとの特性や、モデルの基礎能力が制御の一貫性に寄与することが明らかになった。
TL;DR(結論)
大型言語モデルの内部活性化を直接操作するアクティベーション・ステアリングは、追加学習や複雑なプロンプトを必要とせずに、出力の感情トーンを精密かつ段階的に制御できる軽量な手法である。本研究では、190人の参加者から7,000件以上の評価を収集する初の大規模な人間評価を実施し、人間がモデルの感情変化を明確に知覚できること、および自動評価指標と人間の直感が平均r=0.776という高い相関を示すことを証明した。特定の強度(λ≈0.15)でステアリングを行うことで、テキストの読みやすさを維持したまま「嫌悪」や「恐怖」などの感情を効果的に増幅できる一方、「驚き」の制御は比較的困難であるという感情ごとの特性や、モデルの基礎能力が制御の一貫性に寄与することが明らかになった。
なぜこの問題か
現代の生成AI、特に大型言語モデル(LLM)は、人間と見間違うような自然な対話能力を獲得しているが、その内部プロセスは依然として「ブラックボックス」に近い状態にある。教育、カスタマーサポート、ヘルスケア、さらには航空宇宙のような安全性が重視される領域において、AIが生成する情報の正確さだけでなく、その伝え方や感情的なトーンを制御することは、人間とマシンの円滑なコミュニケーションにおいて極めて重要である。先行研究によれば、AIシステムの感情的な側面に対する人間の知覚は、信頼性や受容性に大きな影響を与え、安全性が重要な環境における使用意図の分散の最大78.5%を説明するとされている。つまり、AIが何を言うかだけでなく、どのように言うかが、ユーザーがそのシステムを信頼し、受け入れるかどうかの決定的な要因となるのである。 しかし、従来の制御手法には大きな課題がある。プロンプトエンジニアリングは特定のタスクには有効だが、感情のような微妙なスタイルの調整においては脆弱であり、手動での最適化に多大な労力を要する。…
核心:何を提案したのか
本研究は、LLMの内部アクティベーションを操作して出力を制御する「アクティベーション・ステアリング」の有効性を、人間による評価を通じて初めて体系的に検証したものである。具体的には、特定の感情(スタイル)を表現する際のモデル内部の活動パターンを「スタイルベクトル」として抽出し、それを推論時に注入することで、生成されるテキストのトーンを調整する手法を採用している。研究チームは、従来のAlpacaモデルから、より高性能なLlaMA-3(具体的にはLlama-3-8B-LexiUncensored)へとアーキテクチャをアップグレードし、より一貫性のある制御を実現した。この手法の最大の特徴は、モデルの再学習を一切行わずに、単一のパラメータ(λ)を調整するだけで、感情の強度をラジオのボリュームを操作するように段階的に変更できる点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related