MAR: モジュールを考慮したアーキテクチャ洗練による効率的な大規模言語モデル
MARは、計算負荷の高い注意機構を線形時間の状態空間モデル(SSM)に置き換えた上で、フィードフォワードネットワーク(FFN)をスパイキングニューラルネットワーク(SNN)によってスパース化する、二段階のモジュール対応アーキテクチャ洗練フレームワークである。
TL;DR(結論)
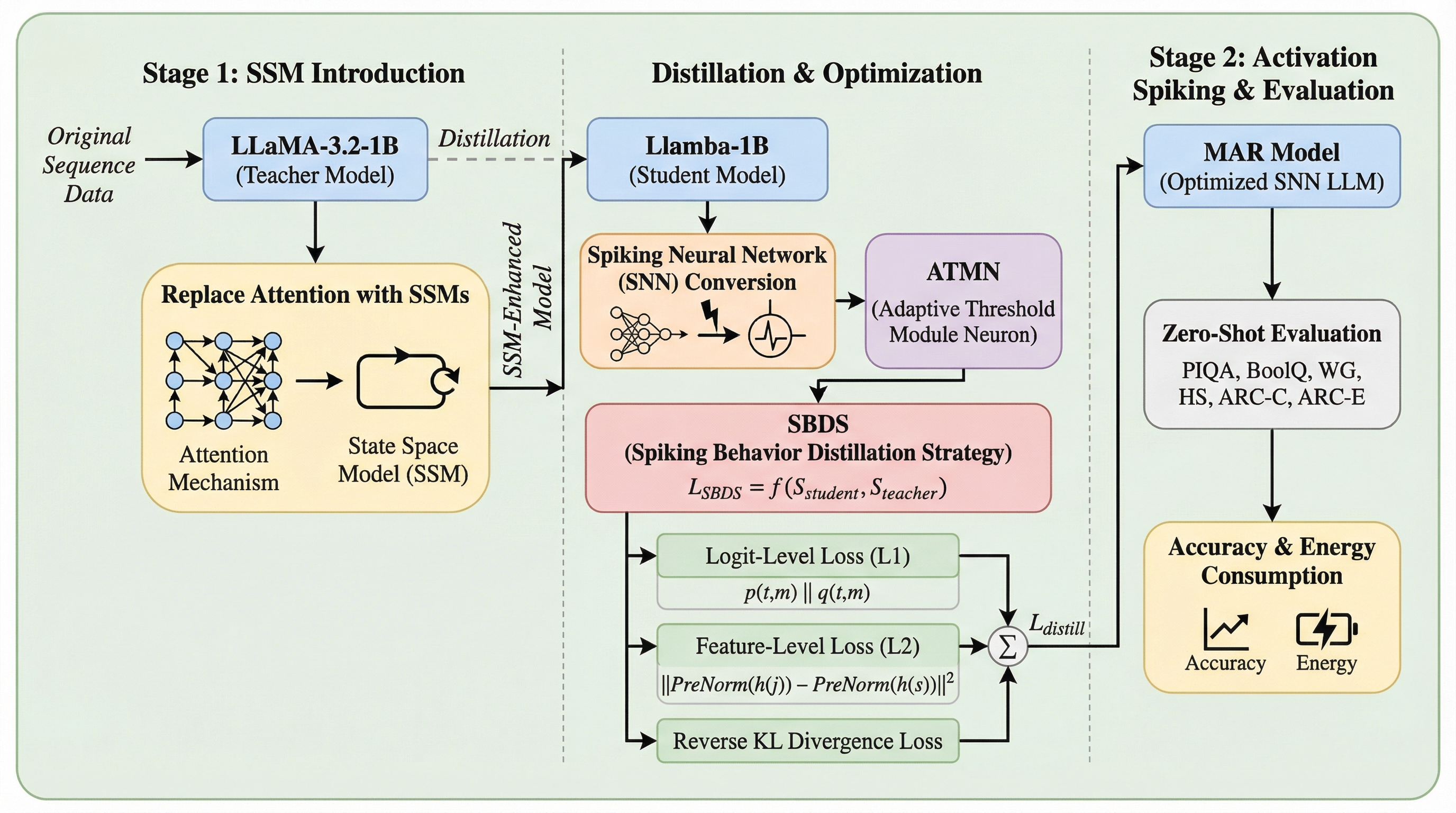
MARは、計算負荷の高い注意機構を線形時間の状態空間モデル(SSM)に置き換えた上で、フィードフォワードネットワーク(FFN)をスパイキングニューラルネットワーク(SNN)によってスパース化する、二段階のモジュール対応アーキテクチャ洗練フレームワークである。 従来のSNNが抱えていた情報密度の低さや時間的な不整合という課題を克服するため、負の信号も表現可能な適応型三値マルチステップニューロン(ATMN)と、事前正規化アライメントを含むスパイク対応双方向蒸留戦略(SBDS)を独自に設計している。 1.4Bのモデル規模でありながら、複数のベンチマークで7B規模の既存効率化モデルを凌駕する平均57.93%の精度を記録し、推論時のエネルギー消費を大幅に抑制しつつ、教師モデルである高密度モデルの性能を効果的に回復させることに成功した。
なぜこの問題か
大規模言語モデル(LLM)は多様な分野で優れた汎用性と適応性を示しているが、その膨大なパラメータ数と計算コストが開発および展開の大きな障壁となっている。特に、従来のTransformerアーキテクチャが採用している注意機構(Attention)は、系列長に対して二次関数的に計算量が増大するという課題を抱えている。これに対し、計算量を線形に抑えるための状態空間モデル(SSM)や、モデル圧縮技術としての量子化、知識蒸留などの研究が進められてきた。しかし、先行研究の多くは注意機構のコスト削減に焦点を当てており、実際には極端に長い系列を除けば、フィードフォワードネットワーク(FFN)がエネルギー消費の大部分を占めているという事実が見過ごされがちである。 本論文の分析によれば、LLaMA-3.2などのモデルにおいて、系列長が一定の閾値(例えば2470や9330)を下回る場合、FFNのエネルギー消費が注意機構を上回ることが示されている。このため、効率的なLLMを実現するためには、注意機構だけでなくFFNの最適化も極めて重要である。…
核心:何を提案したのか
本研究では、注意機構とFFNの両方を共同で最適化するための二段階フレームワーク「Module-aware Architecture Refinement(MAR)」を提案した。このフレームワークは、まず第一段階として、二次関数的な計算コストを持つ注意機構をSSMに置き換えることで、系列モデリングを線形時間で行えるようにする。具体的には、先行研究で成熟しているLlambaをベースラインとして採用し、注意機構を持たない再帰型モデルへと構造を変換する。次に第二段階として、FFNやその他の全結合層の計算コストを削減するために、活性化をスパース化するスパイキングニューロンを導入する。 MARの核心的な技術要素の一つは、情報密度の低さを解消するために設計された「適応型三値マルチステップニューロン(ATMN)」である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related