メカニスティックなデータ・アトリビューション:解釈可能なLLMユニットの学習の起源の追跡
Mechanistic Data Attribution(MDA)は、大規模言語モデル(LLM)内部の誘導ヘッドなどの解釈可能なユニットが、学習データのどのサンプルから影響を受けて形成されたのかを特定する新しいフレームワークです。
TL;DR(結論)
Mechanistic Data Attribution(MDA)は、大規模言語モデル(LLM)内部の誘導ヘッドなどの解釈可能なユニットが、学習データのどのサンプルから影響を受けて形成されたのかを特定する新しいフレームワークです。 Pythiaモデル群を用いた検証により、LaTeXやXMLといった反復構造を持つデータが誘導ヘッド形成の触媒として機能していることが明らかになり、特定のデータを増減させる介入によって回路の形成速度を因果的に制御できることが示されました。 誘導ヘッドの形成とインコンテキスト学習(ICL)能力の向上に直接的な因果関係があることを実証し、この知見を活用したデータ拡張パイプラインによって、モデル規模を問わず特定の機能回路の収束を加速させることが可能になります。
なぜこの問題か
大規模言語モデル(LLM)の急速な発展に伴い、その内部メカニズムを解明しようとする「メカニスティック・インタプリタビリティ(MI)」という分野が注目を集めています。これまでの研究では、特定のタスクを担う「誘導ヘッド」や、事実情報を保持する「知識ニューロン」、あるいは疎な自己符号化器(SAE)によって抽出される単一意味的特徴など、モデル内部の解釈可能なユニットが特定されてきました。しかし、これらの研究の多くは、学習済みのモデルが推論時にどのように動作するかを分析する「静的」なアプローチに留まっていました。現在の大きな課題は、これらの内部回路が学習データのどの部分に由来して形成されるのかという「因果的な起源」が不明であることです。 特定の論理的推論や事実の想起を司る回路が、学習コーパスのどのような統計的性質によって形作られるのかを理解することは、科学的な興味だけでなく、モデルの制御という実用的な観点からも極めて重要です。従来の学習データ帰属(TDA)手法は、モデル全体の損失や出力の尤度といったグローバルな挙動に焦点を当てており、内部の特定の機能ユニットに対するデータの寄与を詳細に追跡するツールは不足していました。…
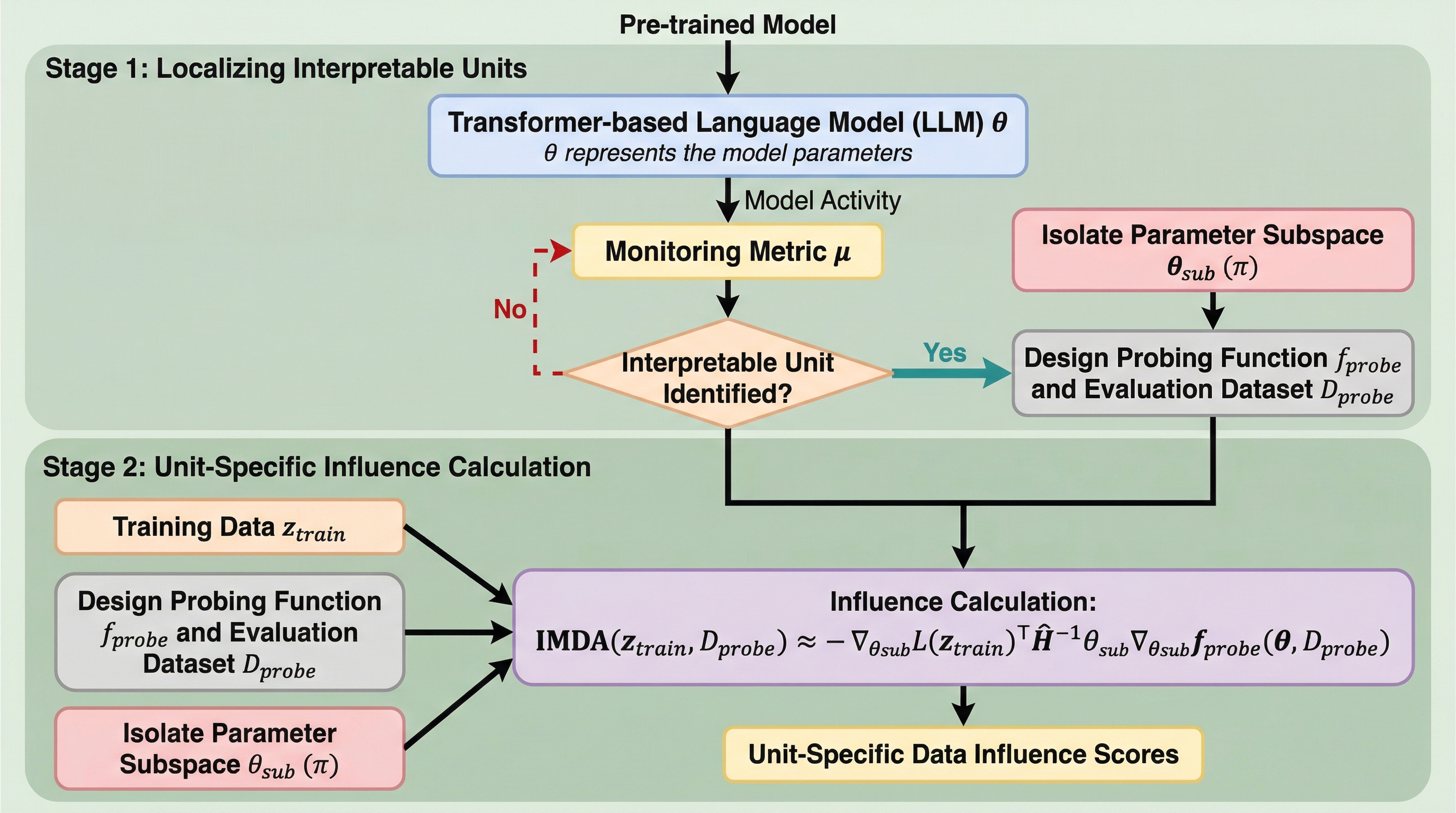
核心:何を提案したのか
本研究では、解釈可能なLLMユニットの学習起源を特定するためのスケーラブルなフレームワークである「Mechanistic Data Attribution(MDA)」を提案しました。MDAは、従来の影響関数(Influence Functions)を拡張し、モデル全体の挙動ではなく、特定のニューロンやアテンションヘッド、SAE特徴量といった個別の機能ユニットの挙動をターゲットとして、学習サンプルの影響度を定量化します。MDAの核心は、特定のユニットの機能的有効性を評価するための「プローブ関数」を導入した点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related