MAR: モジュールを意識したアーキテクチャの洗練による効率的な大規模言語モデル
大規模言語モデルの計算コストとエネルギー消費を削減するため、アテンション機構を状態空間モデル(SSM)に置き換えて線形時間処理を実現し、さらにFFN層をスパイキングニューラルネットワーク(SNN)で疎化する二段階フレームワーク「MAR」を提案しています。
TL;DR(結論)
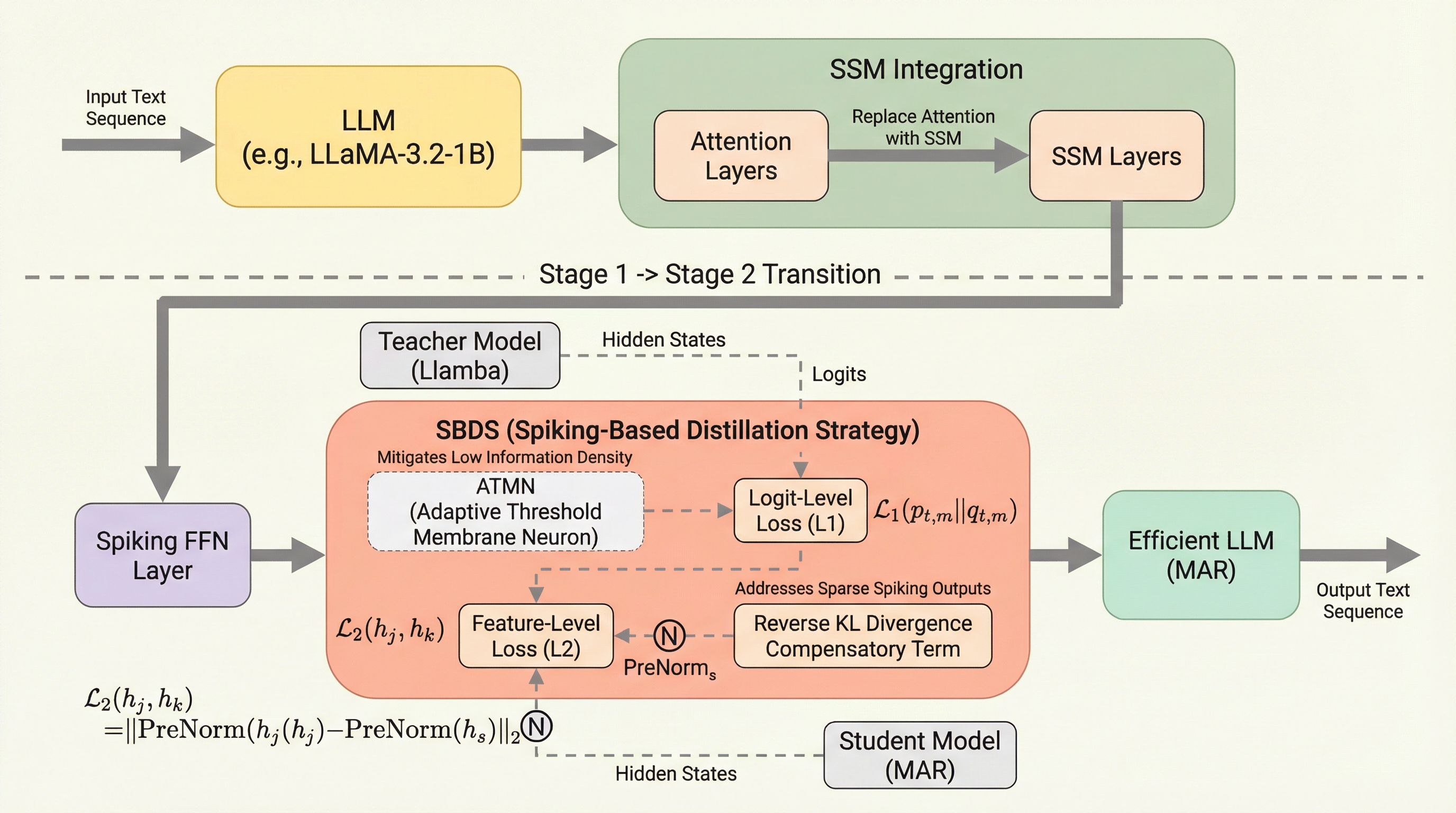
大規模言語モデルの計算コストとエネルギー消費を削減するため、アテンション機構を状態空間モデル(SSM)に置き換えて線形時間処理を実現し、さらにFFN層をスパイキングニューラルネットワーク(SNN)で疎化する二段階フレームワーク「MAR」を提案しています。 情報の低密度化を解消するため、負の信号を表現可能な「適応的三値マルチステップニューロン(ATMN)」を導入し、学習可能な閾値によってスパイクベースのモデルでありながら高い表現能力を確保し、従来の二値スパイクモデルが抱えていた精度の低下という課題を克服しました。 スパイク信号の疎でバースト的な特性に最適化した「スパイク対応双方向蒸留戦略(SBDS)」を採用し、逆KLダイバージェンスと事前正規化アライメントを組み合わせることで、リソース制約下でも元のモデルの性能を高度に維持しつつ、推論時の消費電力を大幅に低減することを実証しました。
なぜこの問題か
大規模言語モデル(LLM)は、自然言語処理の枠を超えて多様なドメインで驚異的な汎化能力と適応力を示していますが、その実用化においては膨大なパラメータスケールに伴う計算リソースの増大とエネルギー消費が大きな障壁となっています。特に、標準的なTransformerアーキテクチャが採用している自己アテンション機構は、入力系列の長さに応じて計算量とメモリ使用量が二乗で増加するという性質を持っており、これが長大なコンテキストを扱う際のボトルネックとなっています。また、モデルの大部分を占めるフィードフォワードネットワーク(FFN)における高密度な行列演算も、推論時のエネルギー消費の主要な要因となっています。 既存の研究では、量子化や知識蒸留といったモデル圧縮技術によって、アーキテクチャを変更せずにエネルギー消費を抑える試みが行われてきました。しかし、これらの手法だけではアテンション機構の二乗計算量という根本的な問題は解決できません。…
核心:何を提案したのか
本研究では、大規模言語モデルにおけるアテンションの二乗計算量とFFNの高密度演算という二つの主要な課題を同時に解決するため、「モジュールを意識したアーキテクチャの洗練(MAR)」という革新的な二段階フレームワークを提案しました。このフレームワークは、まずTransformerの各構成要素をより効率的な構造へと段階的に置き換えるアプローチを採ります。第一段階では、アテンション機構を状態空間モデル(SSM)へと変換し、系列長に対して線形な計算時間を実現します。第二段階では、FFN層などの全結合層にスパイキングニューロンを導入し、活性化を疎化することで演算コストを大幅に削減します。 MARの核心的な貢献は、SNNとSSMを統合する際に生じる情報の欠落や性能低下を防ぐための二つの主要な技術設計にあります。一つ目は「適応的三値マルチステップニューロン(ATMN)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related