A2RAG:コストを意識した信頼性の高い推論のための適応的エージェント型グラフ検索
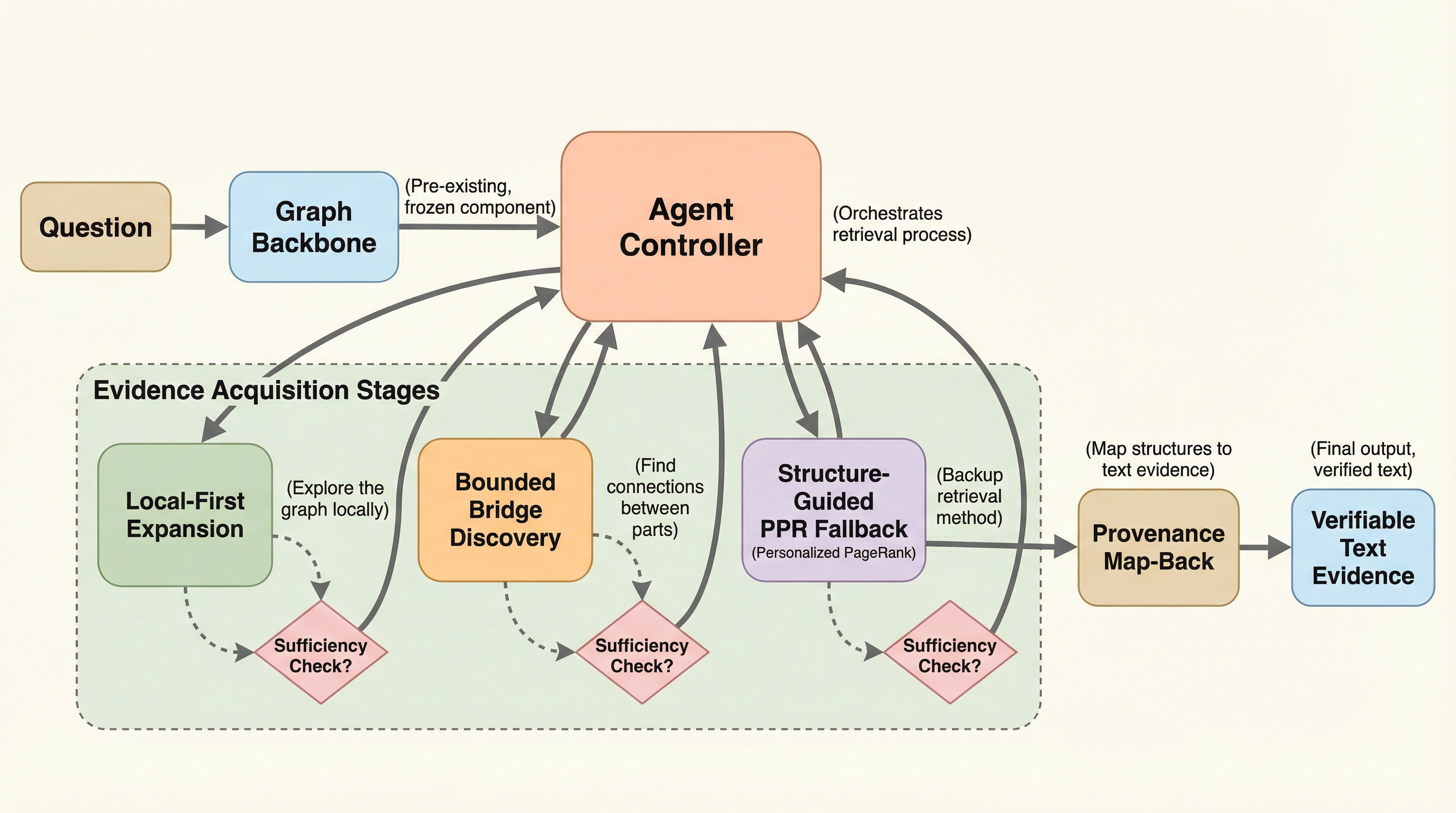
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。
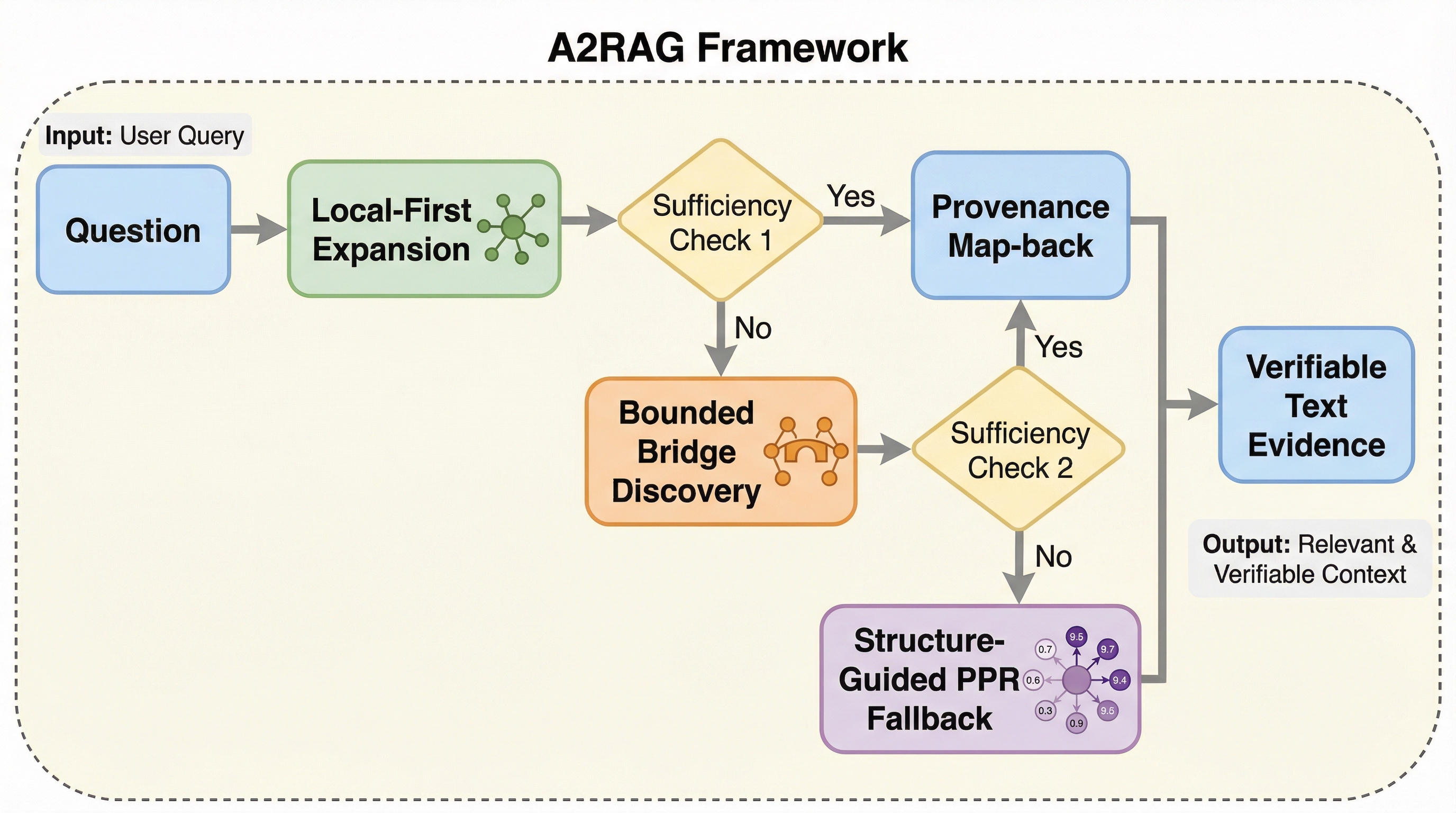
従来のGraphRAGは、全ての質問に対して一律の高度な検索を行うため、簡単な質問での過剰なコスト消費と、複雑な質問におけるグラフ化の際の情報欠落という二つの課題を抱えていました。 本研究が提案するA2RAGは、回答の妥当性を検証して必要時のみ再試行する「適応型制御ループ」と、局所から広域へ段階的に探索範囲を広げつつ元のテキストから詳細を復元する「エージェント型検索機」を統合したフレームワークです。 ベンチマークを用いた検証では、従来の反復的な手法と比較して検索精度を最大11.8ポイント向上させつつ、トークン消費量と処理遅延を約50パーセント削減することに成功し、実用的な効率と信頼性の両立を証明しました。
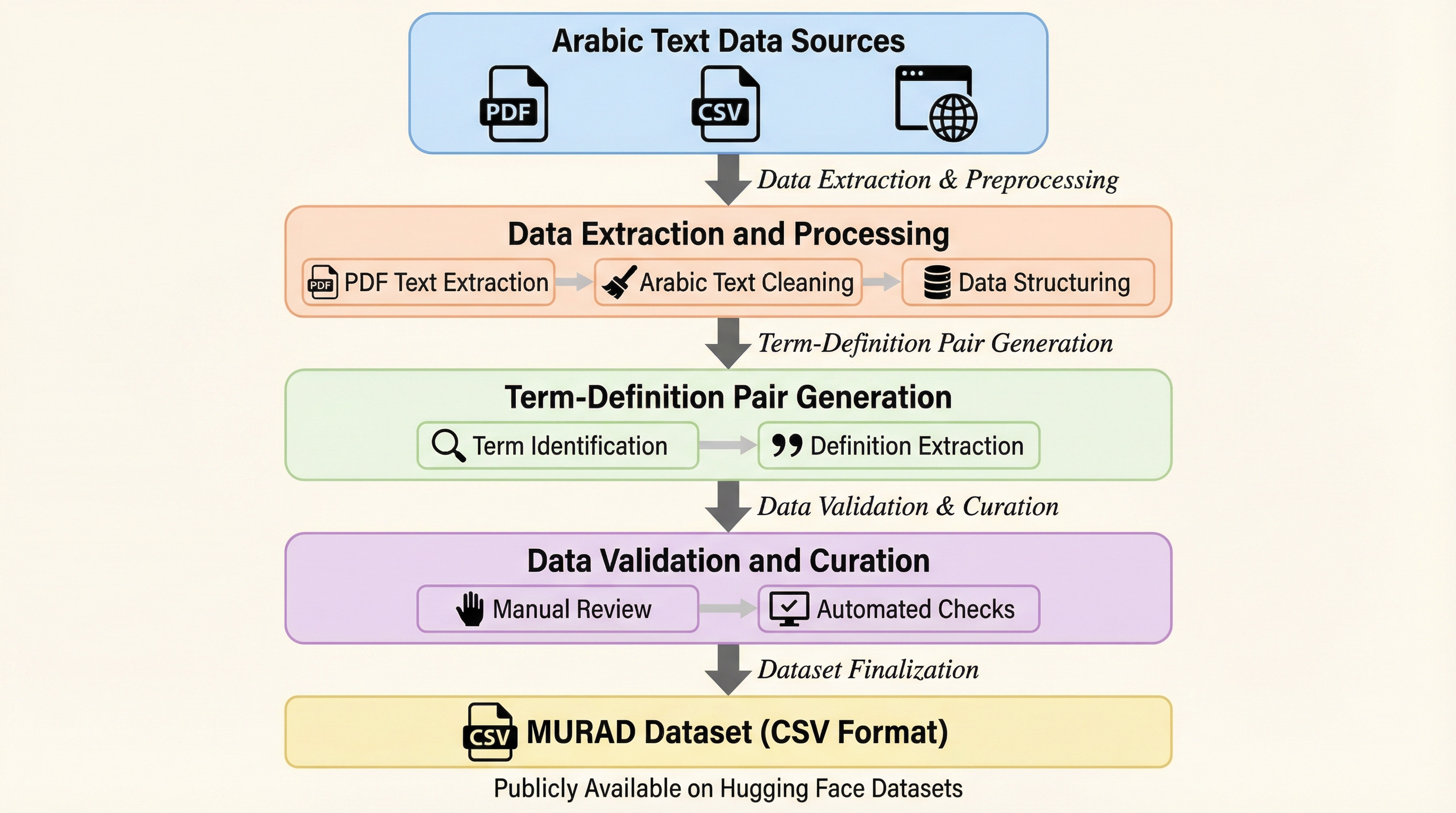
1. MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。 2.
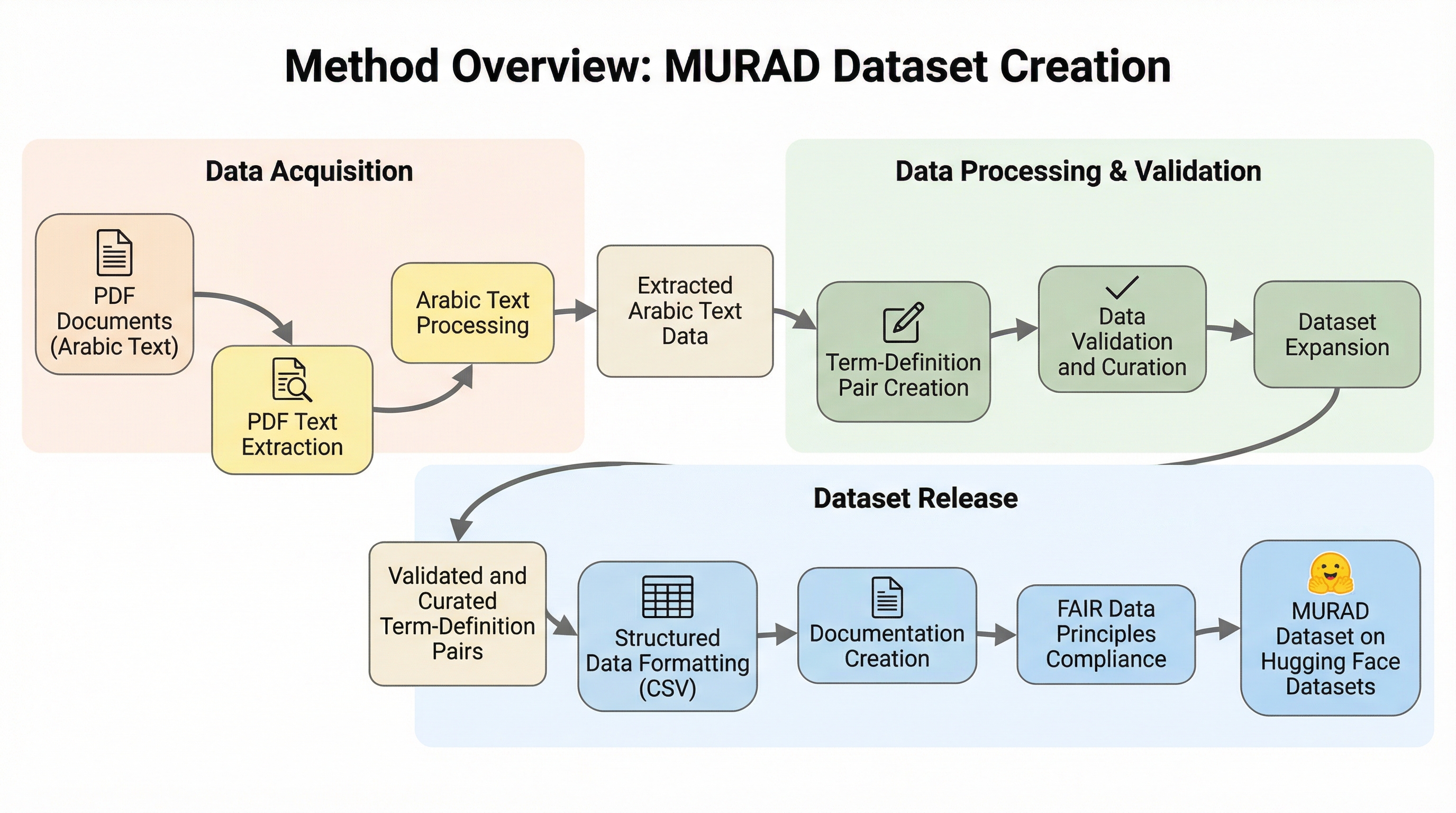
MURADは、アラビア語の語彙と定義を紐付けた96,243組のペアを収録する、大規模でオープンな多領域統合型逆引き辞典データセットです。17の信頼できる出典から構築され、イスラム学、言語学、数学、物理学、工学などの13の専門領域を網羅し、OCRやGPT-4oを活用したハイブリッドなパイプラインによって高い精度と一貫性を確保しています。言葉が思い出せない「舌先現象」の解消や、意味検索、定義生成、埋め込み評価といったアラビア語の自然言語処理研究を促進し、学術的・技術的なコミュニケーションにおける用語の一貫性を支援することを目的としています。
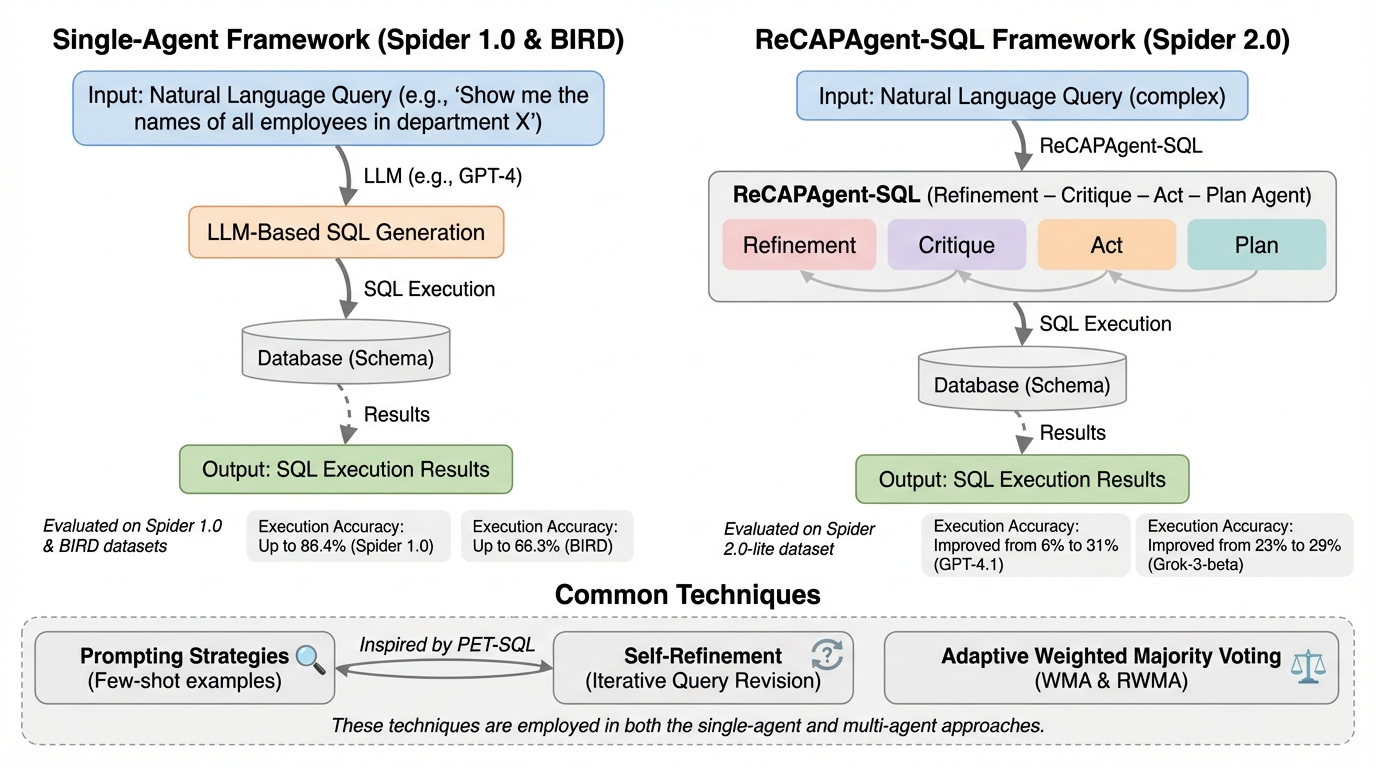
本研究では、大規模言語モデル(LLM)を用いたText-to-SQLの精度を向上させるため、単一エージェントの自己改善とアンサンブル投票を統合したSSEVパイプライン、および複雑な企業データベースに対応する多機能エージェントフレームワークであるReCAPAgent-SQLを提案しました。
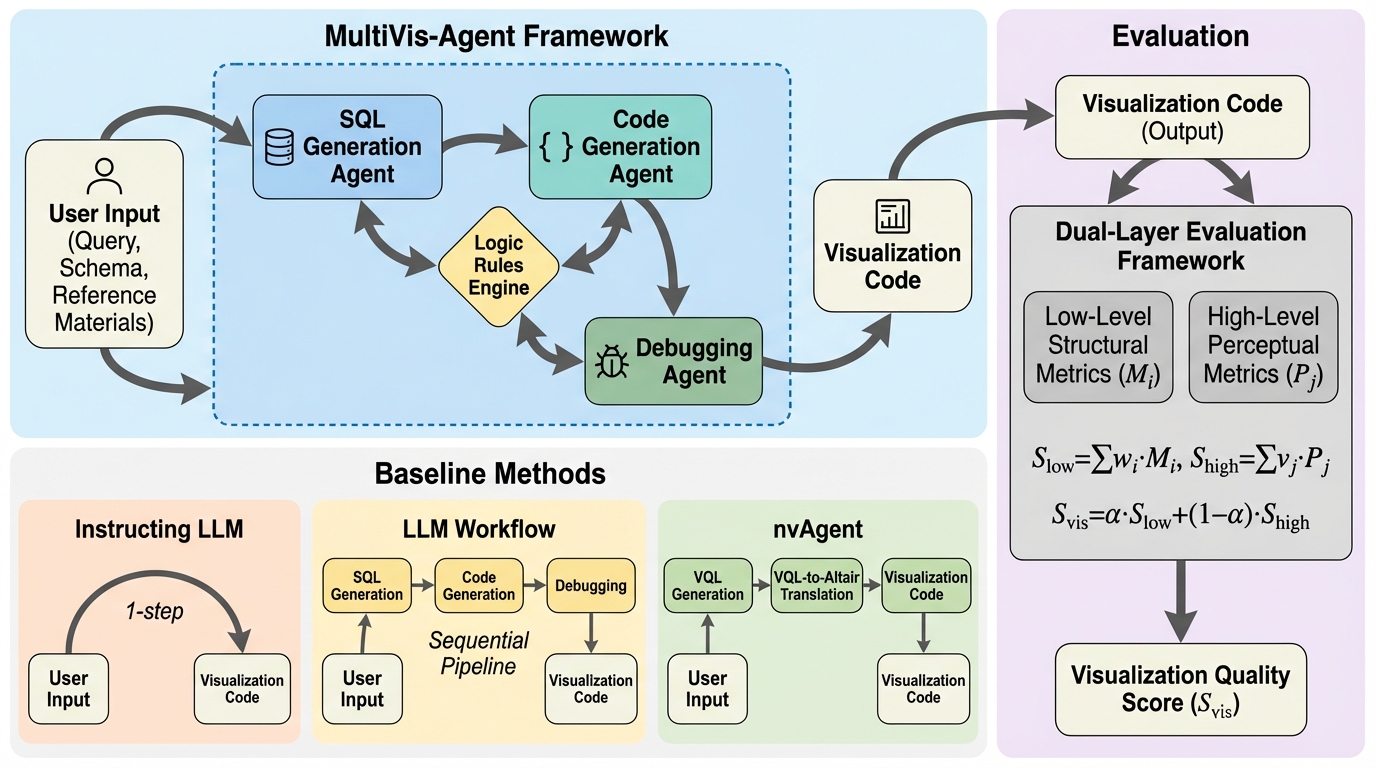
従来のテキストから可視化を行うシステムは、単一の入力形式や一度限りの生成プロセス、柔軟性に欠けるワークフローといった限界を抱えており、大規模言語モデル(LLM)を用いた手法でも無限ループや致命的な失敗といった信頼性の問題が課題となっていました。
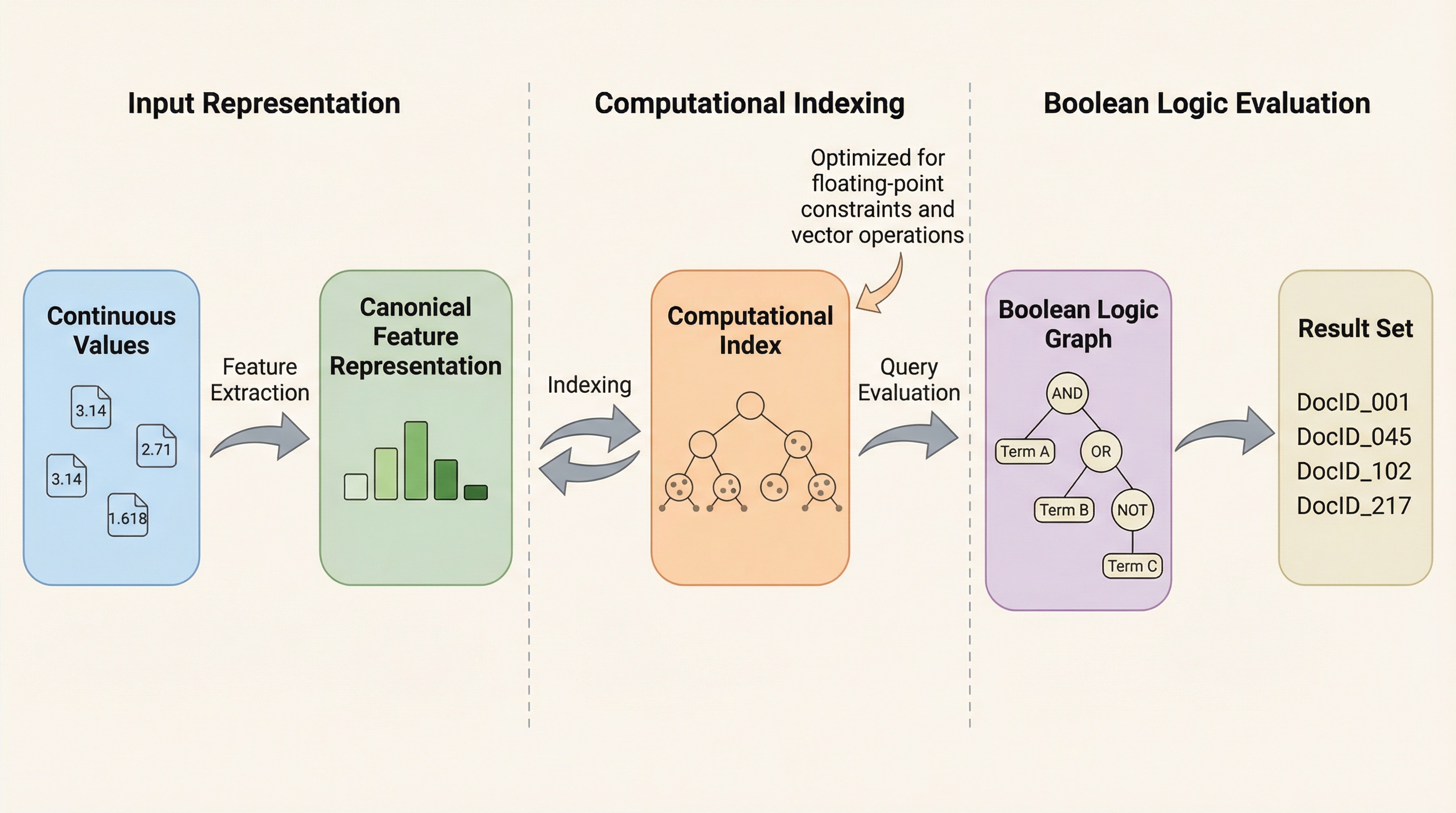
現代の情報検索は、単純なキーワード検索から大規模言語モデル(LLM)や自律型エージェントが要求する複雑な記号論理的推論へと移行していますが、既存の検索エンジンは複雑な論理構造を効率的に処理できないという深刻な課題を抱えています。
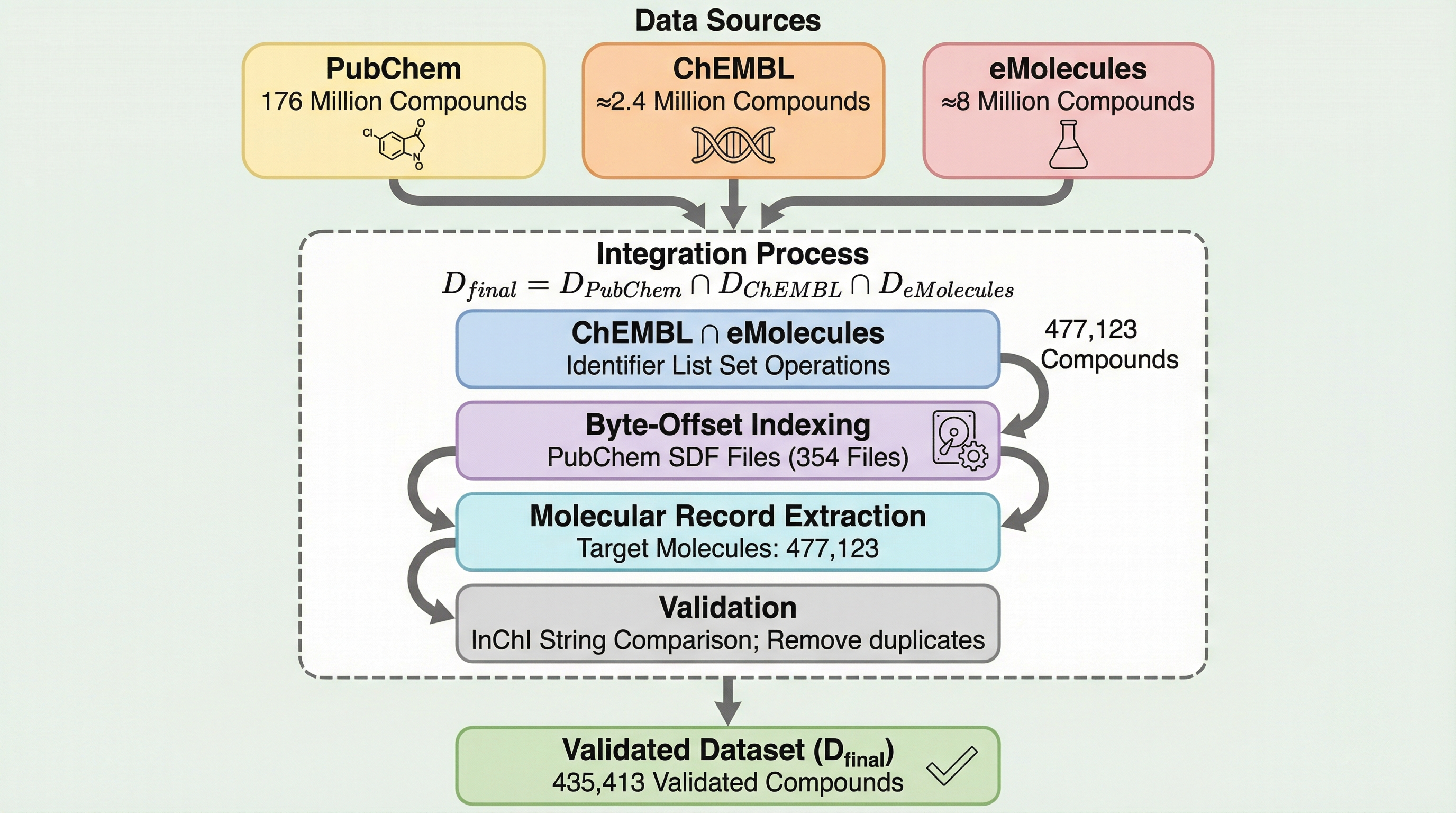
現代の創薬研究に不可欠な大規模化学データベースの統合において、従来の総当たり検索では100日以上を要していた計算時間を、バイトオフセットを用いたインデックス・アーキテクチャの導入によりわずか3.2時間へと劇的に短縮しました。
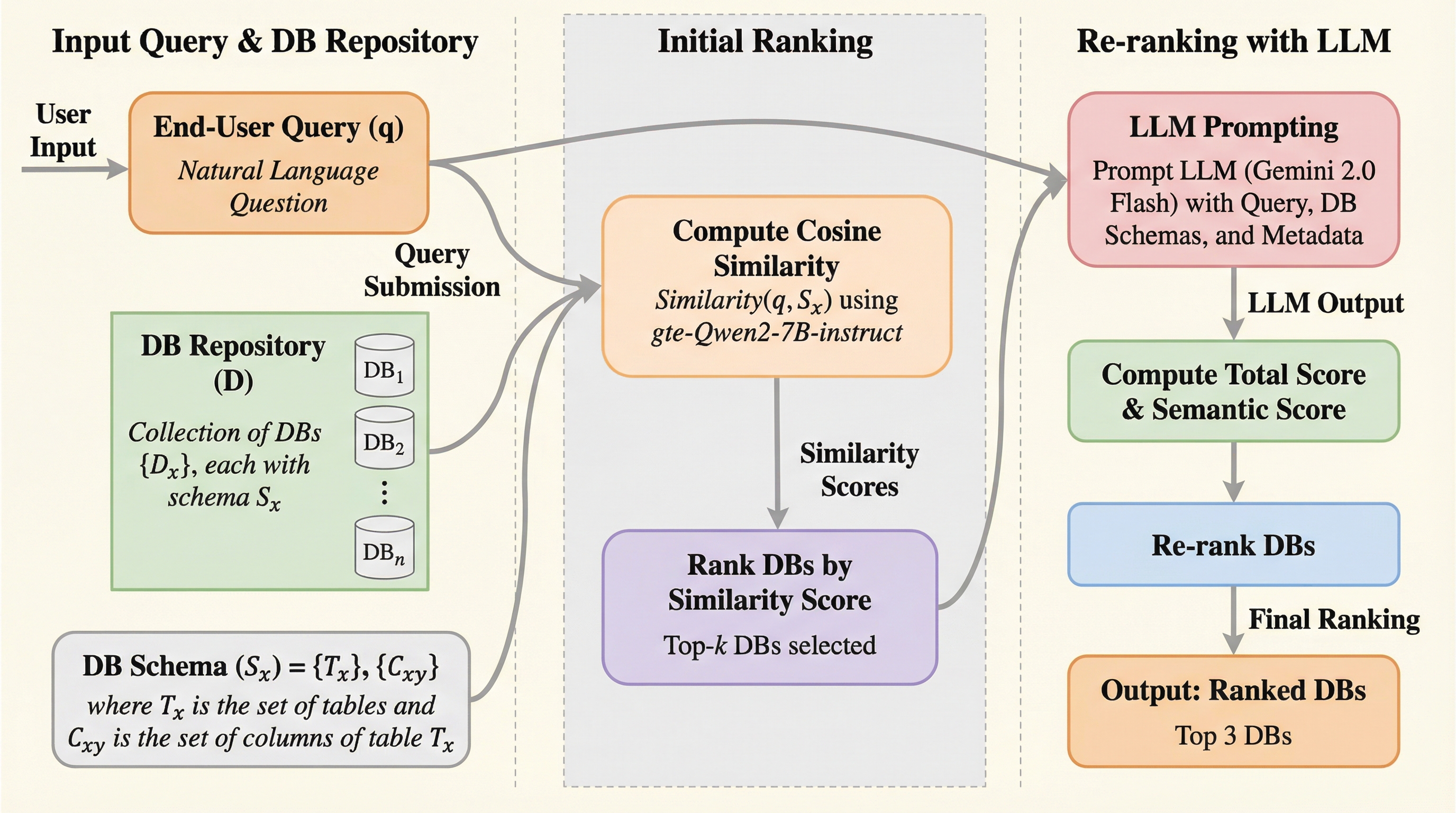
大規模な企業環境において、ユーザーの自然言語による質問を分散した多数のデータベースの中から最も適切なものへ自動的に振り分ける「クエリルーティング」の精度を向上させるため、既存のベンチマークを大幅に拡張した「Spider-Route」と「Bird-Route」を構築し、評価の妥当性を高めました。