LLMに基づくSQL生成:プロンプティング、自己改善、および適応的重み付き多数決
本研究では、大規模言語モデル(LLM)を用いたText-to-SQLの精度を向上させるため、単一エージェントの自己改善とアンサンブル投票を統合したSSEVパイプライン、および複雑な企業データベースに対応する多機能エージェントフレームワークであるReCAPAgent-SQLを提案しました。
TL;DR(結論)
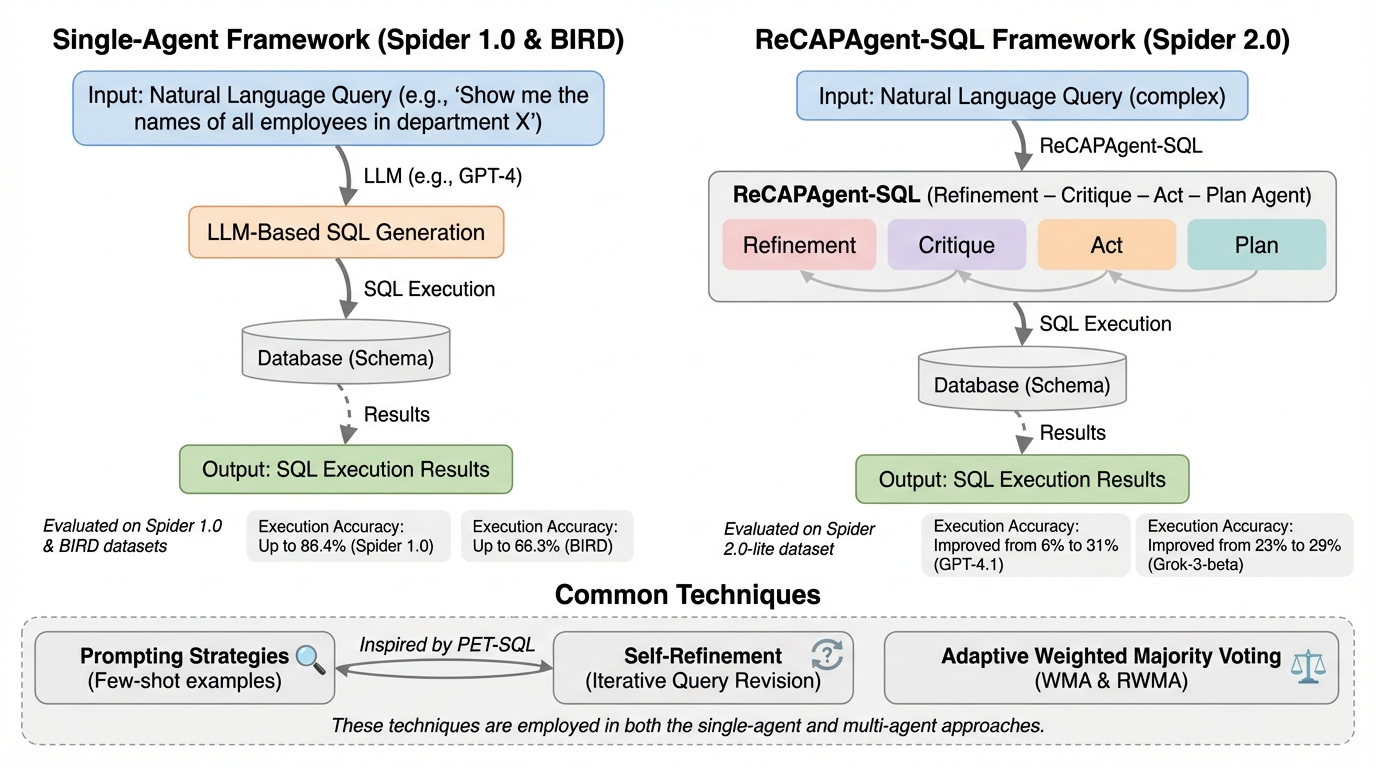
本研究では、大規模言語モデル(LLM)を用いたText-to-SQLの精度を向上させるため、単一エージェントの自己改善とアンサンブル投票を統合したSSEVパイプライン、および複雑な企業データベースに対応する多機能エージェントフレームワークであるReCAPAgent-SQLを提案しました。 この手法の中核は、正解データがない推論時でも動作する重み付き多数決アルゴリズム(WMA)とそのランダム化版(RWMA)であり、複数のLLM専門家の過去のパフォーマンスに基づいて重みを動的に更新し、最も信頼できる回答を適応的に選択する仕組みを備えています。 検証の結果、Spider 1.0で86.4%、BIRDで66.3%の実行精度を達成し、さらに難易度の高いSpider 2.0-LiteにおいてもGPT-4.1を用いた場合に精度を6%から31%へと大幅に向上させるなど、実世界の複雑なシナリオにおける有効性が示されました。
なぜこの問題か
Text-to-SQL技術は、自然言語による問い合わせをSQLクエリに変換することで、専門知識のないユーザーでもデータベースを直接操作できるようにし、データ分析の障壁を大幅に下げる可能性を秘めています。しかし、実用化にあたっては、ユーザーのクエリに含まれる曖昧さや、複雑なデータベーススキーマとの紐付け(スキーマリンク)の難しさ、さらには異なるSQL方言への適応やドメイン固有の知識の欠如といった深刻な課題が立ちはだかっています。既存のシステムは、外部知識や文脈情報の統合、およびステップバイステップの推論能力が不足しており、特にテーブル間の暗黙的な結合やクロスリファレンスの処理において不完全な推論に陥ることが少なくありません。 また、多くのText-to-SQLパイプラインは単一のモデルに依存しており、出力の選択戦略や適応的なフィードバックメカニズムが欠如しているため、過去の経験から学習して精度を高める仕組みが整っていませんでした。Spider 1.0やBIRDといった従来のベンチマークでは一定の成果が得られていたものの、より現実的で複雑な企業環境を模したSpider 2.…
核心:何を提案したのか
本研究の核心は、複数のLLMを「専門家」として扱い、それらの出力を動的に統合するマルチエージェント推論フレームワークの提案にあります。まず、単一エージェントによる自己改善とアンサンブル投票を組み合わせたSSEV(Single-Agent Self-Refinement with Ensemble Voting)パイプラインを構築しました。これは、PET-SQLをベースにしつつ、正解ラベルがない環境でも動作する重み付き多数決アルゴリズム(WMA)およびそのランダム化版(RWMA)を導入したものです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related