CAR-bench:実世界の不確実性下におけるLLMエージェントの一貫性と限界認識を評価するベンチマーク
CAR-benchは、車載アシスタントという実世界の不確実な環境において、LLMエージェントの一貫性、不確実性への対処、および自身の能力限界の認識能力を評価するための新しいベンチマークである。従来のタスク完了重視の評価とは異なり、必要なツールや情報が欠落している場合に嘘をつかずに限界を認める「Hallucinationタスク」と、曖昧な要求を対話や内部検索で解消する「Disambiguationタスク」を導入している。最新の推論モデルを含む評価の結果、一度の成功(Pass@3)と常に成功すること(Pass^3)の間には大きな乖離があり、特に曖昧さの解消においては一貫した成功率が50%を下回るなど、実用化に向けた信頼性の課題が浮き彫りになった。エージェントが「何ができるか」だけでなく「何ができないか」を正しく認識することの重要性を、本ベンチマークは定量的に示している。
TL;DR(結論)
CAR-benchは、車載アシスタントという実世界の不確実な環境において、LLMエージェントの一貫性、不確実性への対処、および自身の能力限界の認識能力を評価するための新しいベンチマークである。従来のタスク完了重視の評価とは異なり、必要なツールや情報が欠落している場合に嘘をつかずに限界を認める「Hallucinationタスク」と、曖昧な要求を対話や内部検索で解消する「Disambiguationタスク」を導入している。最新の推論モデルを含む評価の結果、一度の成功(Pass@3)と常に成功すること(Pass^3)の間には大きな乖離があり、特に曖昧さの解消においては一貫した成功率が50%を下回るなど、実用化に向けた信頼性の課題が浮き彫りになった。エージェントが「何ができるか」だけでなく「何ができないか」を正しく認識することの重要性を、本ベンチマークは定量的に示している。
なぜこの問題か
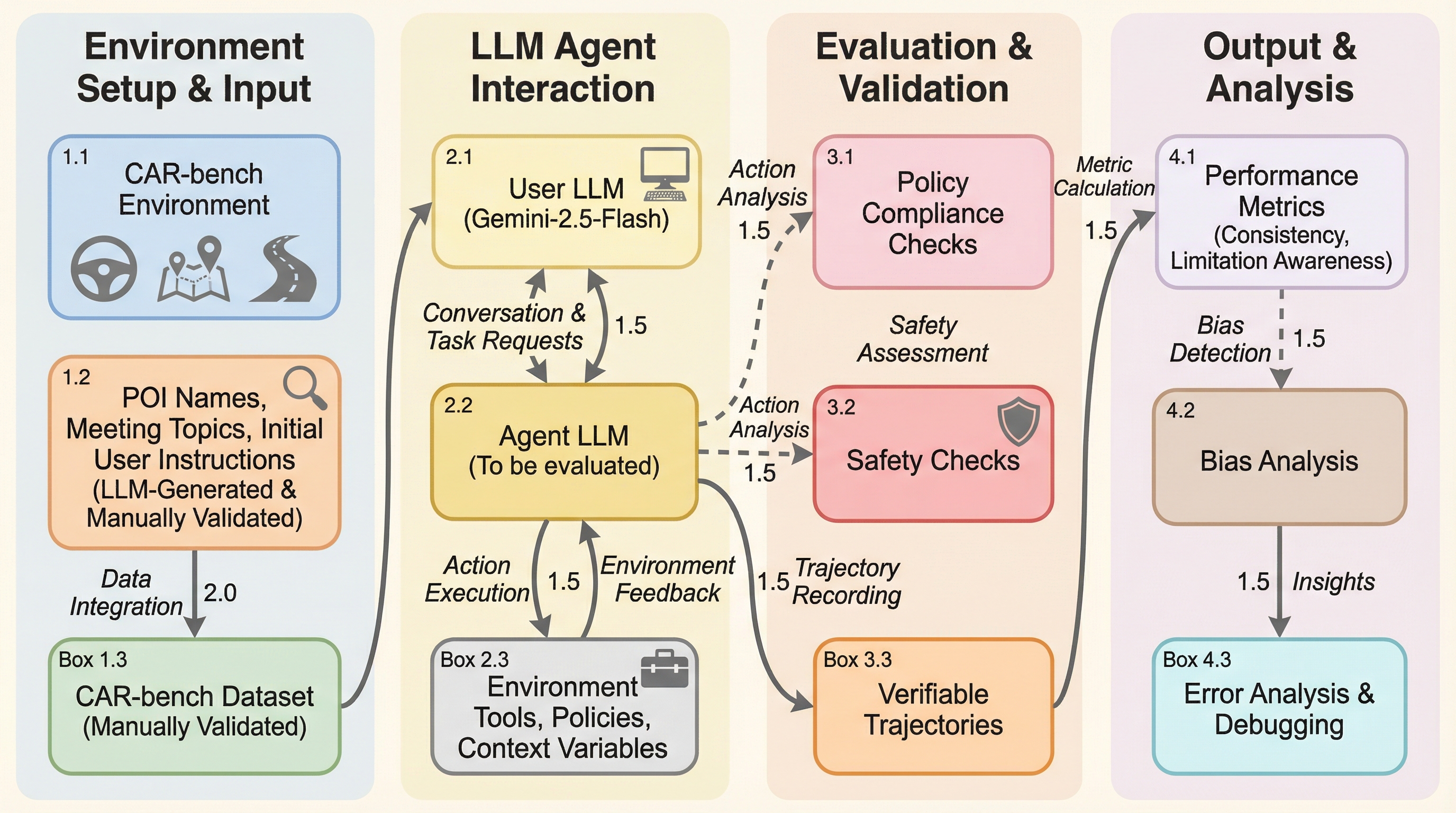
現在、大規模言語モデル(LLM)エージェントは、単一の質問応答を超えて、複雑で多段階のタスクを自律的に実行する方向へと進化している。しかし、これらのエージェントを実際のユーザー向けアプリケーション、特に車載音声アシスタントのような領域に導入するには、単なる実行能力以上のものが求められる。現実の環境では、ユーザーの要求はしばしば不完全であったり、曖昧であったりするため、エージェントには対話やツールの使用、ドメイン固有のポリシー遵守を通じて、内在する不確実性を管理する能力が不可欠となる。既存のベンチマークの多くは、理想的な設定下でのタスク完了に焦点を当てており、実世界での信頼性を見落としている傾向がある。例えば、従来のツール利用ベンチマークは、会話を考慮せずにAPI呼び出し能力のみを分離して評価したり、タスク情報が最初から完全に提供されている単発の対話を前提としたりしている。また、一部のベンチマークは事前に収集された理想的な対話履歴に依存しており、エージェントが動的にポリシーを形成する能力を十分にテストできていない。…
核心:何を提案したのか
本論文は、マルチターンの対話とポリシー制約の下で、LLMエージェントの一貫性、不確実性処理、および能力認識を体系的に評価する初のベンチマークである「CAR-bench」を提案している。このベンチマークは、自動車ドメインを非常に要求の厳しいテストベッドとして活用しており、実世界の複雑さを反映した6つの主要コンポーネントで構成されている。具体的には、タスク指示に従う「LLMシミュレートユーザー」、19のドメインポリシーに従う「エージェント」、情報取得とアクション実行のための58の「ツールセット」、そして「変更可能な状態変数」「固定のコンテキスト変数」「コンテキストデータベース」を備えたインタラクティブな環境が含まれる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related