Pの捕捉:ブール検索の表現能力と効率的な評価について
現代の情報検索は、単純なキーワード検索から大規模言語モデル(LLM)や自律型エージェントが要求する複雑な記号論理的推論へと移行していますが、既存の検索エンジンは複雑な論理構造を効率的に処理できないという深刻な課題を抱えています。
TL;DR(結論)
- 現代の情報検索は、単純なキーワード検索から大規模言語モデル(LLM)や自律型エージェントが要求する複雑な記号論理的推論へと移行していますが、既存の検索エンジンは複雑な論理構造を効率的に処理できないという深刻な課題を抱えています。
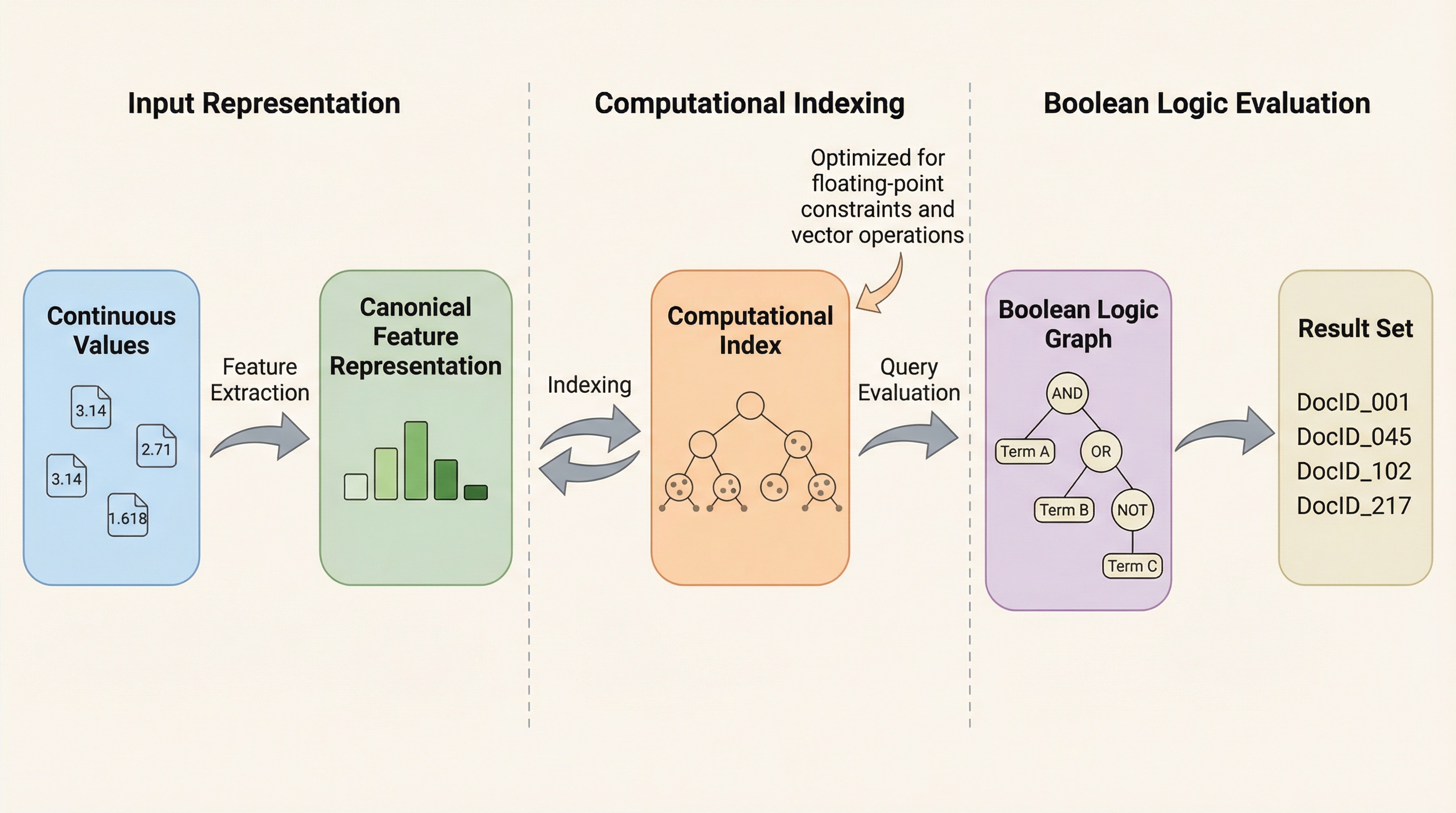
- 本研究では、有向非巡回グラフ(DAG)に基づく検索言語であるL_Rを定義し、これが計算複雑性クラスPに属するあらゆる問題を表現可能であることを理論的に証明するとともに、検索インデックスを汎用的な計算エンジンへと進化させるための基盤を確立しました。
- 提案されたComputePNアルゴリズムは、肯定と否定を組み合わせた「PN応答」という独自のデータ表現を用いることで、従来の検索手法が直面していた指数関数的な計算時間の増大やメモリ消費の爆発を回避し、大規模なデータセットに対しても多項式時間での効率的な評価を可能にしています。
なぜこの問題か
情報アクセスのパラダイムは、人間がキーワードを入力する時代から、大規模言語モデル(LLM)や自律型エージェントが検索エンジンと対話する時代へと劇的に変化しています。現在のアーキテクチャでは、検索エンジンは単なる「受動的なストレージ層」として機能しており、複雑な論理フィルタリングや算術的な制約の充足といった計算負荷の高い処理の多くは、検索結果を受け取った後のLLM側に委ねられています。この「取得してからフィルタリングする」という設計は、二つの重大なボトルネックを生じさせています。第一に、複雑な論理を含むクエリに対して再現率を確保するために、プランナーは膨大な候補文書セットを取得せざるを得ず、これがLLMのコンテキスト窓を飽和させ、推論の遅延増大と信頼性の低下を招いています。大量の不要な情報が混入する「コンテキスト・ノイズ」は、モデルが重要な信号に集中することを妨げ、結果の精度を著しく低下させます。第二に、複雑な推論には「推論・行動・観察」という反復的なエージェントループが必要となり、この反復サイクルがシステム全体の遅延の主要な原因となっています。…
核心:何を提案したのか
本論文の核心的な提案は、検索エンジンが単なるフィルタリングツールを超えて、多項式時間で計算可能なあらゆる特性をインデックス上で直接評価できる「計算エンジン」へと進化すべきであるという主張です。このビジョンを実現するために、著者らは有向非巡回グラフ(DAG)に基づく形式的な検索言語であるLRを定義しました。この言語は、従来の検索システムが採用していた単純な構文木とは異なり、論理的な部分計算の再利用を可能にする構造を持っています。著者らは、このLRが計算複雑性クラスPを正確に捉えること、すなわち、多項式時間で解けるあらゆる決定問題がこの検索言語によって表現可能であることを理論的に証明しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related