A2RAG:コストを意識した信頼性の高い推論のための適応的エージェント型グラフ検索
従来のGraphRAGは、全ての質問に対して一律の高度な検索を行うため、簡単な質問での過剰なコスト消費と、複雑な質問におけるグラフ化の際の情報欠落という二つの課題を抱えていました。 本研究が提案するA2RAGは、回答の妥当性を検証して必要時のみ再試行する「適応型制御ループ」と、局所から広域へ段階的に探索範囲を広げつつ元のテキストから詳細を復元する「エージェント型検索機」を統合したフレームワークです。 ベンチマークを用いた検証では、従来の反復的な手法と比較して検索精度を最大11.8ポイント向上させつつ、トークン消費量と処理遅延を約50パーセント削減することに成功し、実用的な効率と信頼性の両立を証明しました。
TL;DR(結論)
従来のGraphRAGは、全ての質問に対して一律の高度な検索を行うため、簡単な質問での過剰なコスト消費と、複雑な質問におけるグラフ化の際の情報欠落という二つの課題を抱えていました。 本研究が提案するA2RAGは、回答の妥当性を検証して必要時のみ再試行する「適応型制御ループ」と、局所から広域へ段階的に探索範囲を広げつつ元のテキストから詳細を復元する「エージェント型検索機」を統合したフレームワークです。 ベンチマークを用いた検証では、従来の反復的な手法と比較して検索精度を最大11.8ポイント向上させつつ、トークン消費量と処理遅延を約50パーセント削減することに成功し、実用的な効率と信頼性の両立を証明しました。
なぜこの問題か
大規模言語モデル(LLM)は、自然言語理解やコード生成、複雑な推論において革新的な能力を示していますが、金融や医療、法務といった重要分野での実用化には大きな障壁があります。それは、モデルがもっともらしいが根拠のない情報を生成してしまうハルシネーションの問題です。特に、意思決定の全プロセスに追跡可能性と監査可能性が求められる分野では、このリスクは許容できません。この解決策として、外部の知識ベースを参照するRAG(検索拡張生成)が標準的な手法となりましたが、従来のベクトル検索に基づくRAGは、断片的なテキストチャンクの取得に頼るため、複数の文書にまたがる情報の関連性を捉えることが難しく、文脈の断片化を引き起こすという弱点がありました。 これに対し、エンティティとその関係を知識グラフとしてモデル化するGraphRAGが登場し、構造的な依存関係を辿ることで多段階の推論を可能にしました。しかし、GraphRAGを実際の生産規模で運用すると、二つの根本的なボトルネックに直面します。第一に、質問の難易度が混在しているワークロードにおいて、一律の検索戦略を適用することの非効率性です。…
核心:何を提案したのか
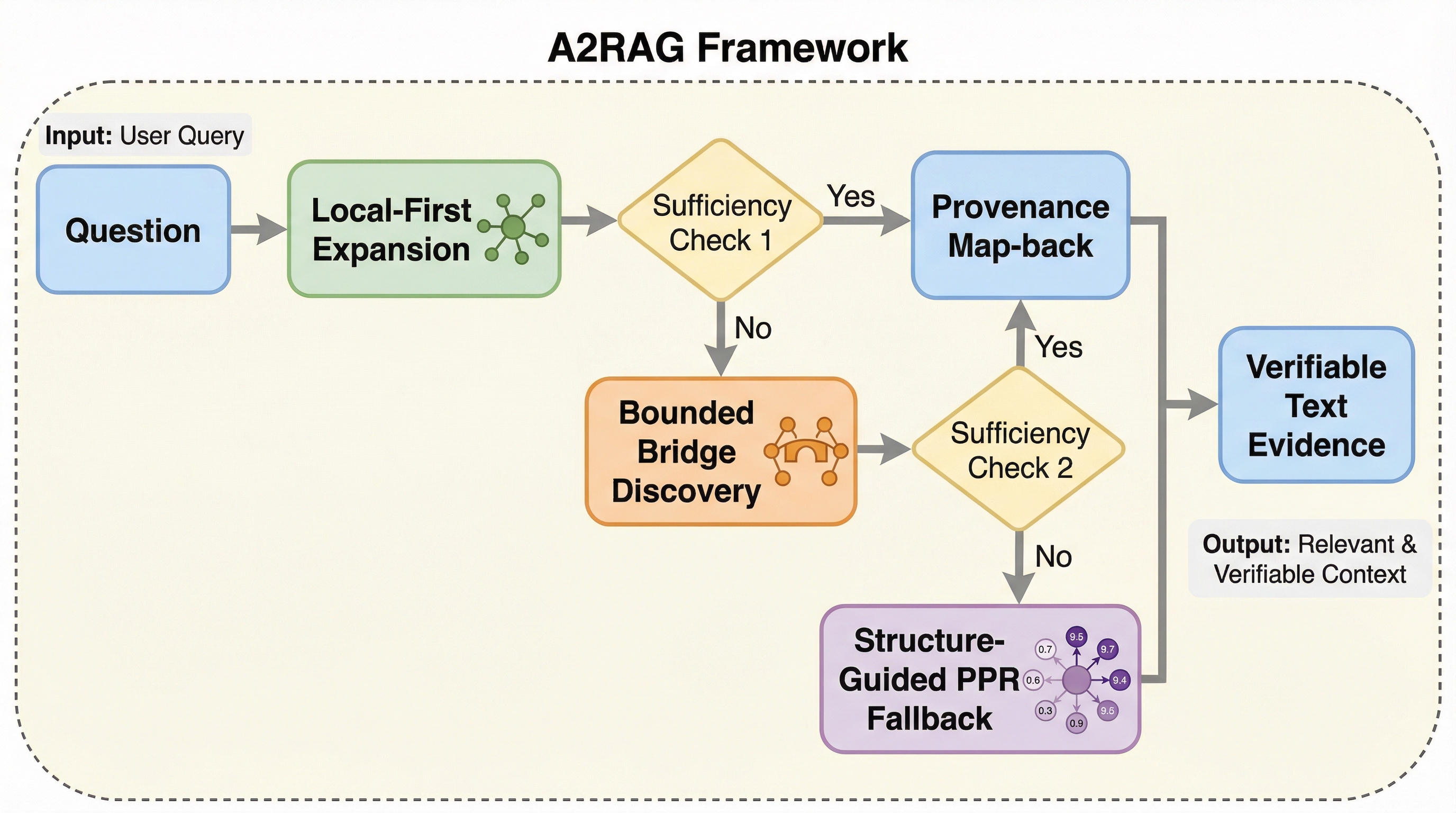
本研究では、回答レベルでの信頼性制御と、検索レベルでの段階的な証拠取得を分離して管理する統一フレームワーク「A2RAG」を提案しました。このフレームワークの核心は、コストを意識しながら信頼性の高い推論を実現するために、二つの補完的な層を組み合わせた点にあります。一つ目は「適応型制御ループ」であり、これは回答の質をグローバルな視点で監視する閉ループメカニズムです。生成された回答が質問に対して適切か、取得された証拠に基づいているかを検証し、不十分な場合には失敗の原因を分析して質問を書き換え、制限された予算内で再試行を指示します。これにより、一度の検索で正解に辿り着けない場合でも、自己修正を通じて精度を高めることが可能になります。 二つ目の層は「エージェント型検索機」です。これは、検索の実行を動的なプロセスとして捉え、必要最小限の労力で十分な証拠を収集するステートフルなエージェントとして機能します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related