MURAD:大規模マルチドメイン統合アラビア語逆引き辞典データセット
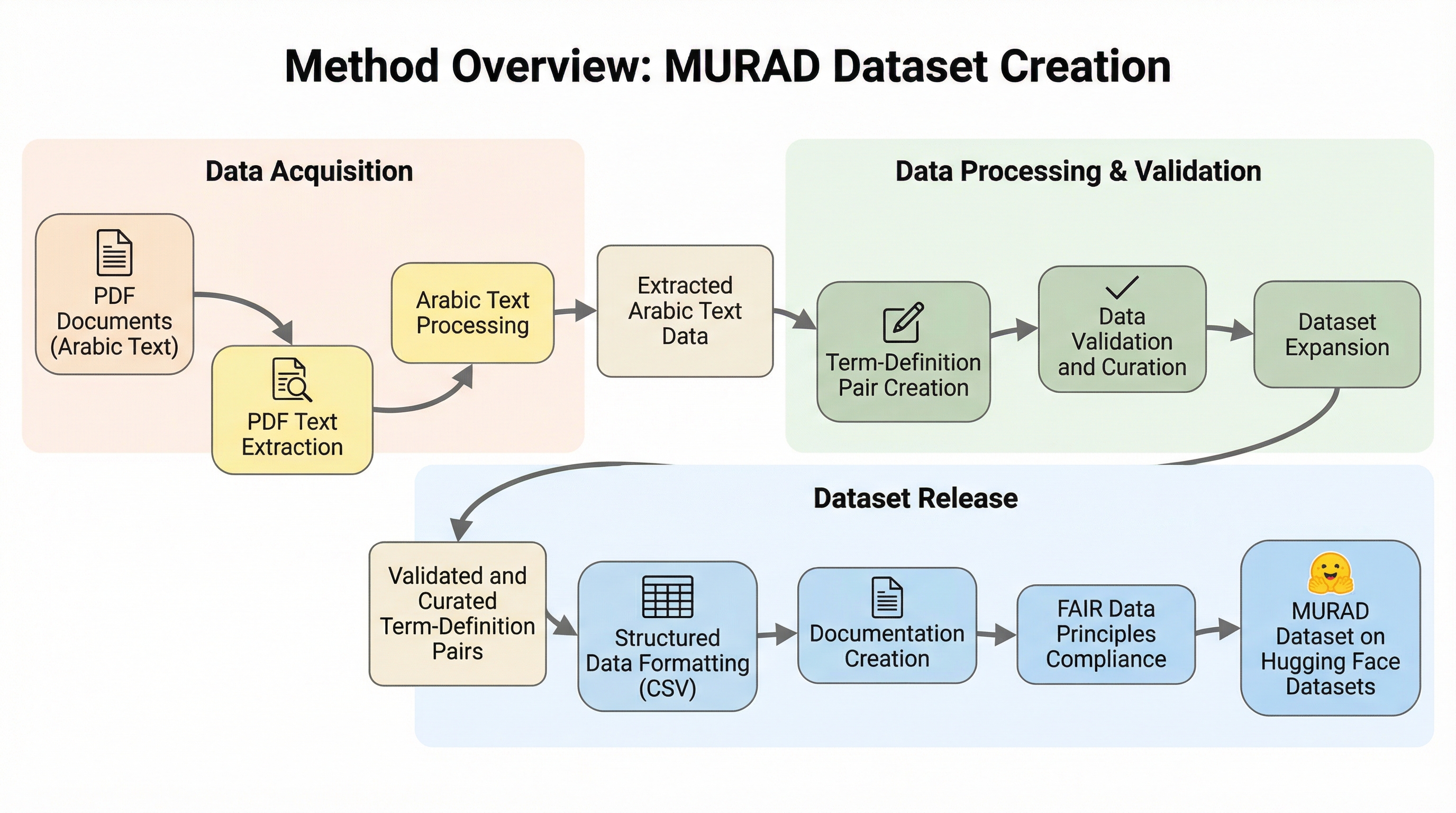
MURADは、アラビア語の語彙と定義を紐付けた96,243組のペアを収録する、大規模でオープンな多領域統合型逆引き辞典データセットです。17の信頼できる出典から構築され、イスラム学、言語学、数学、物理学、工学などの13の専門領域を網羅し、OCRやGPT-4oを活用したハイブリッドなパイプラインによって高い精度と一貫性を確保しています。言葉が思い出せない「舌先現象」の解消や、意味検索、定義生成、埋め込み評価といったアラビア語の自然言語処理研究を促進し、学術的・技術的なコミュニケーションにおける用語の一貫性を支援することを目的としています。
TL;DR(結論)
MURADは、アラビア語の語彙と定義を紐付けた96,243組のペアを収録する、大規模でオープンな多領域統合型逆引き辞典データセットです。17の信頼できる出典から構築され、イスラム学、言語学、数学、物理学、工学などの13の専門領域を網羅し、OCRやGPT-4oを活用したハイブリッドなパイプラインによって高い精度と一貫性を確保しています。言葉が思い出せない「舌先現象」の解消や、意味検索、定義生成、埋め込み評価といったアラビア語の自然言語処理研究を促進し、学術的・技術的なコミュニケーションにおける用語の一貫性を支援することを目的としています。
なぜこの問題か
アラビア語は言語的・文化的に非常に豊かな言語であり、科学、宗教、文学の各分野にわたる膨大な語彙を有していますが、単語を正確な定義と結びつけた大規模なデータセットはこれまで限定的でした。特に、概念や意味は分かっているのに特定の言葉が思い出せない「舌先現象(Tip of the Tongue)」を解消するための逆引き辞典システムの開発において、アラビア語のリソース不足は深刻な課題となっていました。英語やフランス語、中国語などの言語では逆引き辞典のリソースが確立されていますが、アラビア語はその形態的な複雑さや、書き言葉と話し言葉の二重言語状態、綴りの曖昧さなどが原因で、データセットの作成が遅れていました。 特に法律や工学といった専門領域では、正確な概念と用語の対応付けが極めて重要です。法律分野のアラビア語は、古典的な法学用語と現代の法制用語が混在しており、同じ概念でも国や法学派によって異なる用語が使われることがあり、契約や規制において誤解を招くリスクがあります。また、工学や技術分野では、英語やフランス語からの借用語が多く、翻訳の不一致や機関ごとの用語のばらつきが問題となっています。…
核心:何を提案したのか
本研究では、アラビア語で「意図」や「求められるもの」を意味する言葉にちなんで名付けられた「MURAD(Multi-domain Unified Reverse Arabic Dictionary)」というデータセットを提案しました。これは、現代のアラビア語辞典から慎重に収集された96,243組の「単語、定義、出典」のトリプレット(3つの要素の組)で構成されています。このデータセットは、古典アラビア語、言語学、イスラム学、さらには科学技術用語までを網羅する包括的なマルチドメインのカバレッジを特徴としています。各定義は、明快さと一貫性、そして意味的な精度を確保するために、8つの正式な辞書編集基準に従って洗練されています。 MURADは、これまでのアラビア語リソースと比較して最大規模のキュレーション済みデータセットです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related