RVR:包括的な質問応答のための検索・検証・再検索
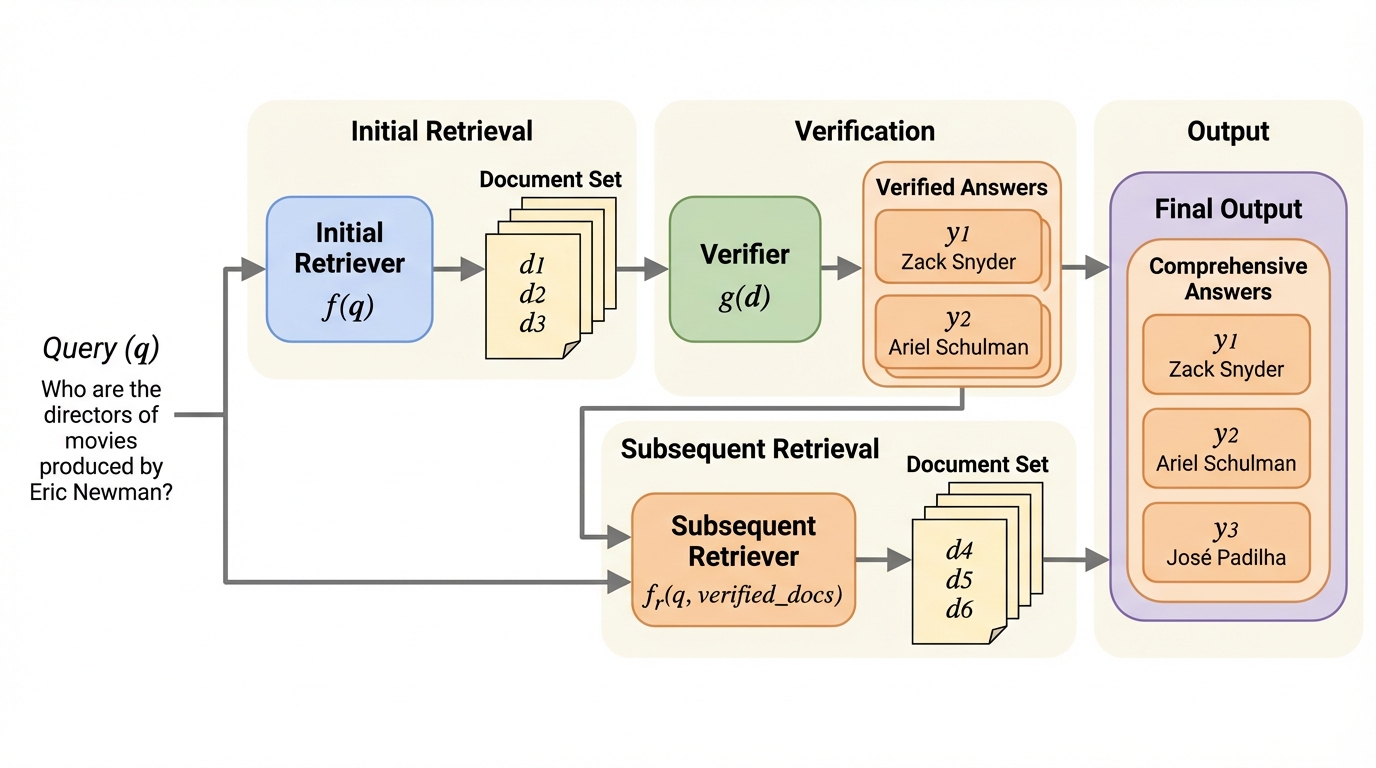
正解が多数あり得る質問では、上位文書を一度だけ並べる検索では答えの偏りや取りこぼしが起きやすく、関連性と網羅性を同時に高める工夫が必要です。 / RVRは、最初の検索結果を検証器でふるいにかけ、その「良い」と判断した文書を質問に連結して次の検索を回し、前の周回で未カバーの答えに対応する文書を追加で狙います。
TL;DR(結論)
- 正解が多数あり得る質問では、上位文書を一度だけ並べる検索では答えの偏りや取りこぼしが起きやすく、関連性と網羅性を同時に高める工夫が必要です。
- RVRは、最初の検索結果を検証器でふるいにかけ、その「良い」と判断した文書を質問に連結して次の検索を回し、前の周回で未カバーの答えに対応する文書を追加で狙います。
- QAMPARIでは完全再現の割合で相対10%以上・絶対3%の改善が報告され、QUESTとWebQuestionsSPでも複数のベース検索器に対して一貫した改善が示されています。
なぜこの問題か
大規模言語モデルに最新情報やロングテールの知識を与える方法として、外部コーパスからの検索は重要です。ところが質問によっては、正解が一つに定まらず、多数の妥当な答えが並立します。こうした多回答の設定では、単に「最も関連しそうな文書」を少数返すだけでは不十分で、答えの種類が偏らないように文書を多様に集める必要があります。 一回の検索で得られるランキングは、似た内容の文書が上位に固まりやすく、別の答えを含む文書が後方に押しやすいです。その結果、同じ答えを裏づける文書ばかりが集まり、別の答えは文書として回収できないままになる可能性があります。一方で、回収数だけを増やすと無関係文書も増え、後段の処理や利用が難しくなります。つまり、多回答検索では「ノイズを抑えつつ、未回収の領域を探索する」ことが同時に求められます。 近年は、検索を道具として使いながら推論し、複数回検索を呼び出すエージェント型の方式も提案されています。ただし本論文の整理では、それらは主に複数段の推論を進めるために異なる検索クエリを順に作る用途が中心で、同じ質問に対して答えの網羅性を最大化する目的に特化した反復設計とは必ずしも一致しません。…
核心:何を提案したのか
提案はRetrieve-Verify-Retrieve(RVR)という複数ラウンドの検索フレームワークです。目的は、多回答質問に対して答えのカバレッジを最大化することです。流れは、検索で候補文書を集め、検証器で高品質な部分集合を選び、その選ばれた文書を使って次ラウンドの検索を行う、という反復です。ここでの検証は単なる後処理のフィルタではなく、次の検索を「どこを探すべきか」に誘導する情報として扱われます。 具体的には、最初の検索で拾えた答えを含む文書を検証器が確定し、その確定文書を質問文に連結して再検索します。すると再検索側は、すでに確定した内容と重複しにくい補完的な文書、すなわち前周回で未カバーの答えが含まれる文書を見つけにいく構図になります。この反復により、一発勝負のランキングが持つ「同じ種類の文書に集中しやすい」性質を緩和し、網羅性の改善を狙います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related