テラバイト規模のデータ統合に向けたバイトオフセット・インデックス・アーキテクチャを用いた大規模ケモインフォマティクスの高速化
現代の創薬研究に不可欠な大規模化学データベースの統合において、従来の総当たり検索では100日以上を要していた計算時間を、バイトオフセットを用いたインデックス・アーキテクチャの導入によりわずか3.2時間へと劇的に短縮しました。
TL;DR(結論)
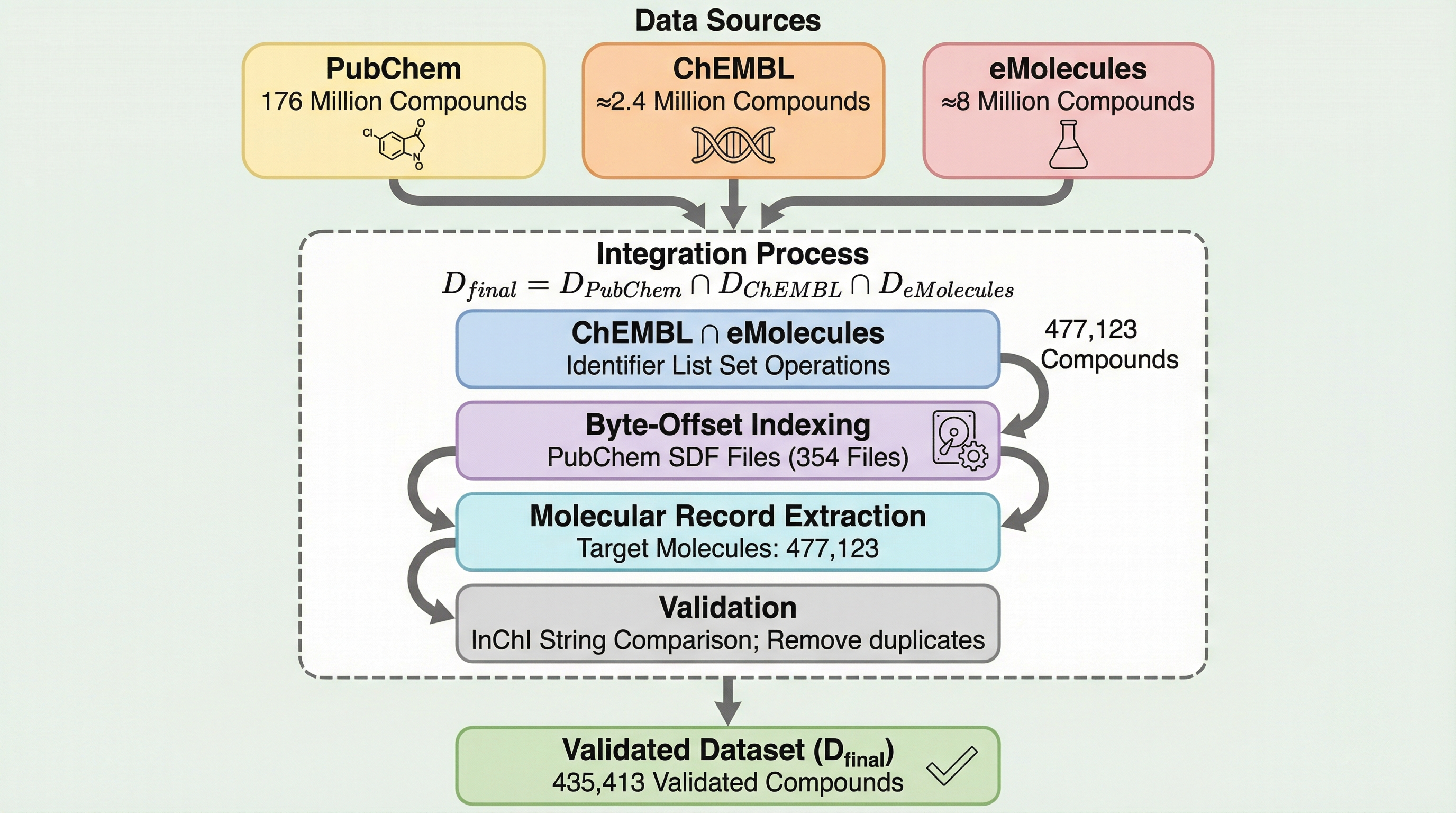
現代の創薬研究に不可欠な大規模化学データベースの統合において、従来の総当たり検索では100日以上を要していた計算時間を、バイトオフセットを用いたインデックス・アーキテクチャの導入によりわずか3.2時間へと劇的に短縮しました。この手法は計算複雑性を $O(N \times M)$ から $O(N+M)$ へと改善し、約740倍の高速化を実現すると同時に、ディスクI/Oボリュームを99.7%削減することに成功しています。さらに、1億7600万件規模のデータ検証を通じてInChIKeyのハッシュ衝突を実証し、科学的整合性を担保するために衝突のない完全なInChI文字列を用いた検証済み化合物の抽出パイプラインを構築しました。
なぜこの問題か
現代の製薬開発や化学情報学の分野では、化合物の特性予測やリード化合物の最適化を行うために、大規模な分子データセットで訓練された機械学習モデルが不可欠となっています。公開されている化学データの量は指数関数的に増加しており、PubChemだけでも1億7600万を超える固有の化合物が登録されています。高品質な訓練用データセットを構築するためには、PubChem、ChEMBL、eMoleculesといった複数の異種ソースから情報を統合し、重複排除や相互検証を行う必要があります。しかし、これらのデータはテラバイト規模の半構造化フォーマットであるSDFファイルで保存されており、その統合処理は計算上極めて重い負荷となります。 従来の直接検索アプローチでは、ターゲットとなる分子ごとに膨大なファイルを走査する必要がありました。本研究の分析によれば、約47万件のターゲット分子を1億7600万件のPubChemデータから抽出する場合、総当たり的なアルゴリズムでは約8.4×10の13乗回の比較が必要になります。これは、ハードウェアの故障や中断がないと仮定しても、連続稼働で100日以上の実行時間を要することを意味します。…
核心:何を提案したのか
本論文では、バイトオフセット・インデックス・アーキテクチャを用いることで、総当たり検索の拡張性の限界を克服する手法を提案しています。この提案の核心は、統合タスクを「インデックス構築」と「ターゲット抽出」という、計算特性の異なる2つのフェーズに分解した点にあります。第一のフェーズであるインデックス構築では、すべてのソースファイルを一度だけ完全にスキャンし、各分子識別子からファイル内の正確なバイト位置への永続的なマッピングを作成します。この処理は一度実行すれば、作成されたインデックスをディスク上に保存してその後の抽出作業で無制限に再利用することが可能です。 第二のフェーズであるターゲット抽出では、構築済みのインデックスを活用して、ターゲット分子への直接的なルックアップを実行します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related