MURAD: 大規模な多領域統合型アラビア語逆引き辞書データセット
1. MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。 2.
TL;DR(結論)
- MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。
- 本データセットは、言語学やイスラム学といった伝統的な分野から、数学、物理学、心理学、工学、さらには機械学習や人工知能といった現代的な科学技術分野まで、13の専門領域を幅広く網羅しているのが特徴である。
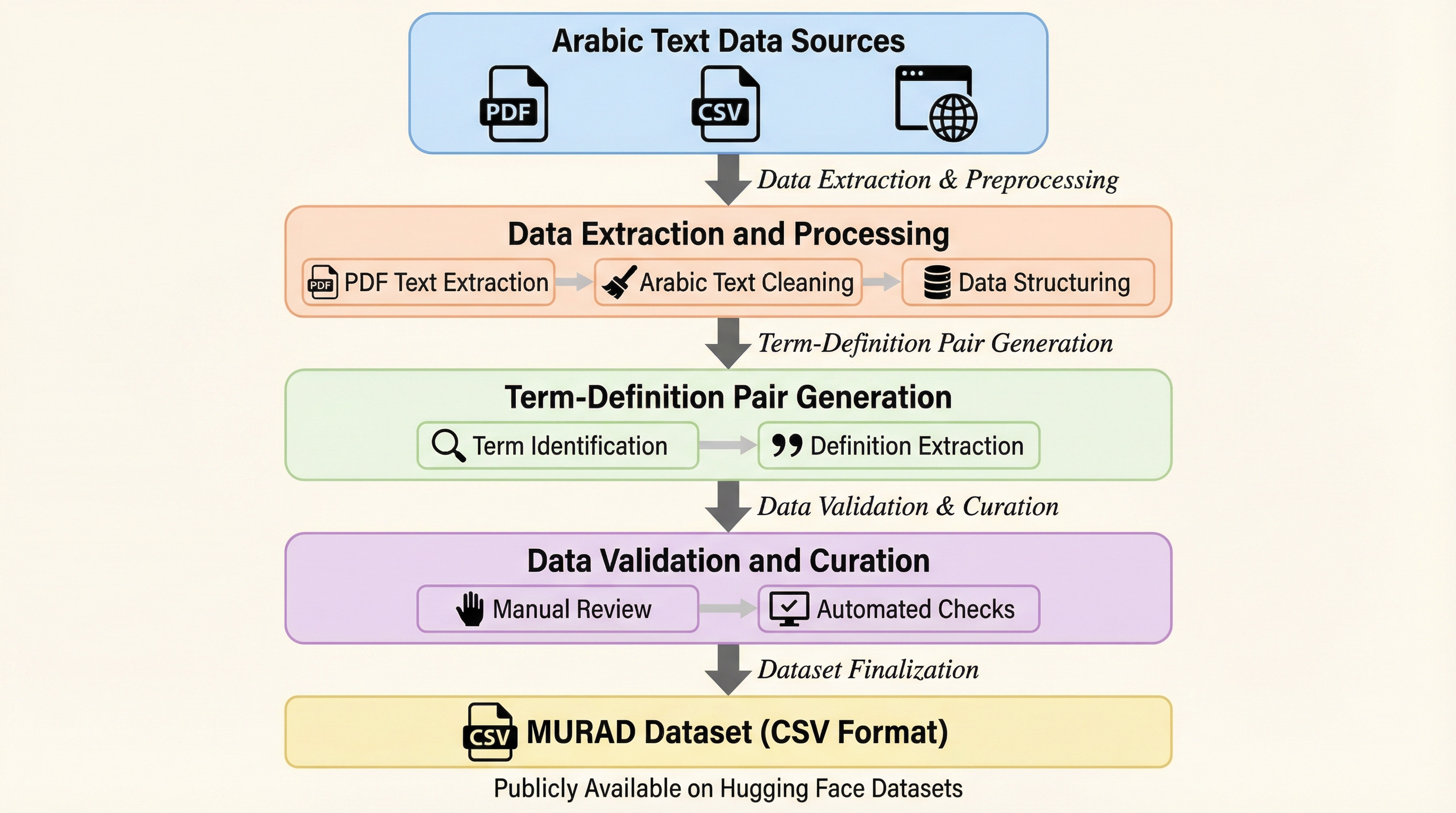
- 開発にはOCR技術やGPT-4oを活用したハイブリッドな抽出パイプラインが採用されており、意味論的検索や定義生成、単語の埋め込み評価など、アラビア語の自然言語処理研究を大きく進展させるオープンなリソースとして提供されている。
なぜこの問題か
アラビア語は言語的、文化的に非常に豊かな背景を持ち、科学、宗教、文学などの多岐にわたる分野で膨大な語彙を有している。しかし、特定の単語とその正確な定義を結びつけた大規模な語彙データセットは、これまで極めて限定的であった。特に「喉まで出かかっている(Tip of the Tongue: TOT)」現象、すなわち概念や意味は思い出せるが正確な単語が思い出せないというもどかしい状態を解消するための逆引き辞書(Reverse Dictionary: RD)システムの開発において、この欠如は大きな課題となっていた。逆引き辞書システムは、ユーザーが意味から単語を検索することを可能にし、執筆、学術研究、技術的なコミュニケーションにおいて、より正確な言語表現や適切な用語の選択を支援する役割を果たす。特に法律や工学のような専門分野では、自然言語による説明を意味的に適切な用語にマッピングすることが、明快さと正確さを高めるために不可欠である。アラビア語の法律分野では、古典的な法学用語と現代の法制化された言語が混在しており、同じ概念が国や法学派によって異なる用語で表現されることがあるため、契約や規制において曖昧さや誤解が生じるリスクが高い。…
核心:何を提案したのか
本研究では、アラビア語で「意図」や「求められるもの」を意味する言葉にちなんで名付けられたMURAD(Multi-domain Unified Reverse Arabic Dictionary)というデータセットを提案した。このデータセットは、現代のアラビア語辞書から慎重に精選された96,243組の「定義、単語、出典」のトリプレットで構成されている。各定義は、明快さ、一貫性、および意味の正確さを確保するために、8つの正式な辞書編集基準に基づいて洗練されている。MURADは、人間による解釈可能性と計算機によるモデリングの両方をサポートするように設計されており、アラビア語の意味技術のための信頼できる言語的基盤を提供する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related