エンドユーザーのクエリをエンタープライズデータベースへルーティングする
大規模な企業環境において、ユーザーの自然言語による質問を分散した多数のデータベースの中から最も適切なものへ自動的に振り分ける「クエリルーティング」の精度を向上させるため、既存のベンチマークを大幅に拡張した「Spider-Route」と「Bird-Route」を構築し、評価の妥当性を高めました。
TL;DR(結論)
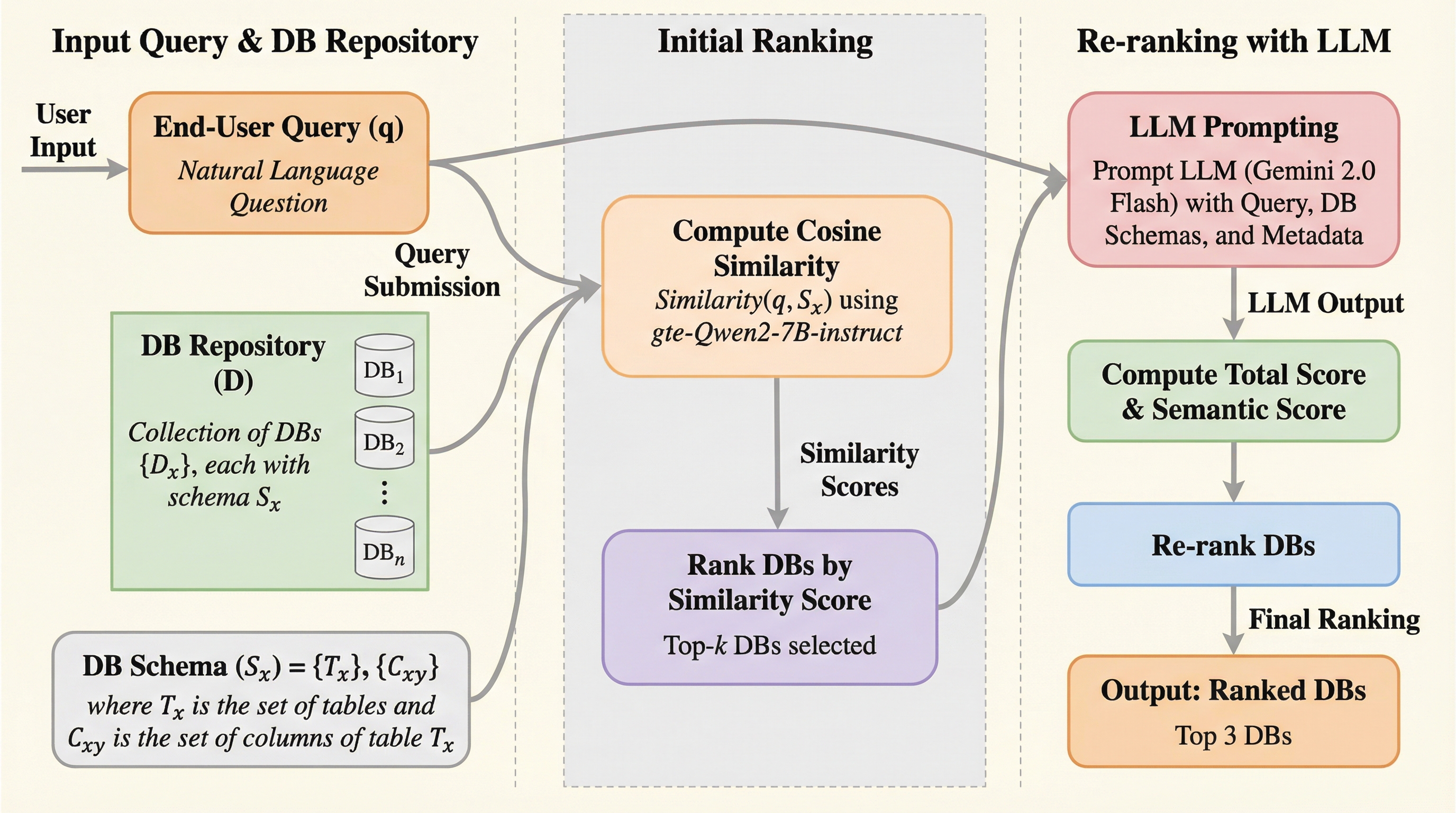
大規模な企業環境において、ユーザーの自然言語による質問を分散した多数のデータベースの中から最も適切なものへ自動的に振り分ける「クエリルーティング」の精度を向上させるため、既存のベンチマークを大幅に拡張した「Spider-Route」と「Bird-Route」を構築し、評価の妥当性を高めました。 提案された「モジュール式推論再ランキング戦略」は、大規模言語モデル(LLM)による意味的な整合性確認と、スキーマの被覆率やテーブル間の接続性を検証するアルゴリズムを組み合わせることで、従来の埋め込みベースの手法や直接的なLLMプロンプティングを大幅に上回るルーティング精度を達成しています。 この手法は、データベースのスキーマが頻繁に変更される実環境を考慮した「トレーニングフリー」な設計であり、ドメインが重複する複数のデータベースが存在する複雑な状況下でも、クエリの意図を正確に解釈して適切なデータソースを特定できることが検証されました。
なぜこの問題か
現代の大企業におけるデータ管理は、ナレッジグラフ、リレーショナルデータベース、ドキュメントリポジトリなど、多種多様で異質なソースに分散して行われています。ユーザーが自然言語で質問を投げかけた際、その回答を正確かつ包括的に提供できる適切なデータソースへクエリを導く「ルーティング」は、エンタープライズ検索の基盤となる極めて重要な課題です。しかし、先行研究で提案されたルーティング用のベンチマークには、現実の運用環境とは乖離した重大な制限が存在していました。まず、既存のベンチマークはリポジトリの規模が非常に小さく、データベースの分布が極端に偏っていました。その結果、未知のデータベースを扱う「クロスドメイン」設定の方が、既知のデータベースを扱う「インドメイン」設定よりも高い精度が出るという、直感に反する不自然な評価結果を招いていました。これは、既存の評価指標が現実のデータ分布を公平に反映できていないことを示唆しています。 また、実際の企業環境では、複数のデータベースが類似したドメイン(例えば「書籍管理」と「書籍レビュー」など)を扱っていることが多く、テーブル名やカラム名、さらには格納されている値が重複することが頻繁にあります。…
核心:何を提案したのか
本研究の主要な提案は、大規模言語モデル(LLM)の高度な推論能力を特定の小さなタスクに限定して活用し、構造的な整合性の検証をアルゴリズムで行う「モジュール式推論駆動型再ランキング戦略」です。この手法の最大の特徴は、データベースのスキーマが動的に変化する実環境を想定し、追加の学習を一切必要としない「トレーニングフリー」な設計である点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related