A2RAG:コストを意識した信頼性の高い推論のための適応的エージェント型グラフ検索
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。
TL;DR(結論)
A2RAGは、従来のグラフRAGが抱えていた「一律の検索によるコストの浪費」と「グラフ化の際の細かな情報の欠落(抽出ロス)」という2つの課題を解決するために提案された、適応型かつエージェント型の新しい検索フレームワークである。 このシステムは、証拠の十分性を検証して必要に応じてクエリを書き直す「適応型コントロールループ」と、安価なローカル検索から段階的に検索範囲を広げる「エージェント型リトリーバー」を組み合わせることで、効率的かつ正確なマルチホップ推論を実現している。 検証の結果、HotpotQAなどのベンチマークにおいて、従来の反復的な手法と比較してトークン消費量と遅延を約50%削減しながら、検索精度(Recall@2)を最大11.8ポイント向上させるという、コストパフォーマンスと信頼性の両立を実証した。
なぜこの問題か
大規模言語モデル(LLM)は多様な分野で革新的な能力を示しているが、金融、医療、法律といった重要な部門においては、根拠の欠如による「ハルシネーション(もっともらしい嘘)」が実用上の大きな障壁となっている。特に、すべての決定に追跡可能性と監査可能性が求められる金融リスク監視や法令遵守の現場では、根拠のない発言は許容できない運用リスクを招く。これを解決するために、外部のコーパスから証拠を検索して回答を生成するRAG(検索拡張生成)が標準的な手法となっているが、従来のRAGは孤立したテキスト断片を検索する傾向があり、複数の文書にまたがる情報の合成(マルチホップ推論)が困難であった。 グラフRAG(GraphRAG)は、エンティティとその関係を知識グラフとしてモデル化することで、構造的な依存関係に基づいた検索を可能にし、この問題を改善しようとしている。しかし、実際の運用においては2つの大きなボトルネックが存在する。第一に、クエリの難易度が混在しているという問題である。…
核心:何を提案したのか
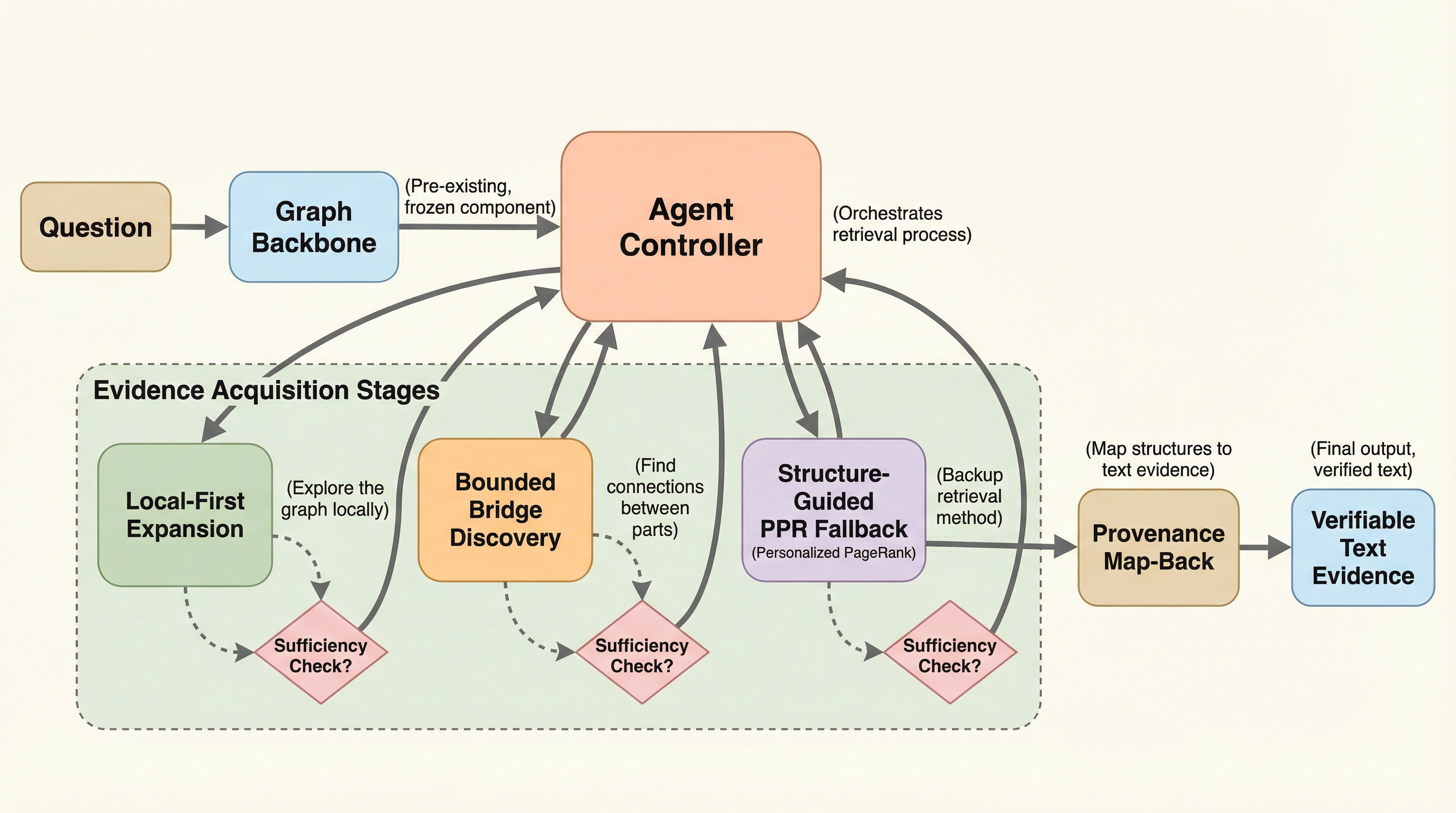
本論文では、回答レベルの信頼性制御と、検索レベルの段階的な証拠取得を切り離した統合フレームワーク「A2RAG(Adaptive Agentic Graph Retrieval-Augmented Generation)」を提案している。このフレームワークの核心は、検索を「予算の範囲内で実行される動的でコスト意識の高いプロセス」として再定義した点にある。具体的には、2つの主要なレイヤーで構成されている。 一つ目は「適応型コントロールループ(Adaptive Control Loop)」である。これは、最終的な回答が取得された証拠と照らし合わせて信頼できるかどうかを検証するクローズドループ機構である。このループは、単に検索を繰り返すのではなく、証拠の関連性、回答の根拠、クエリの解決度という3つの観点(Triple-Check)から失敗のモードを診断する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related