最小抵抗の経路:接頭辞の合意によるLLM推論軌道の誘導
大規模言語モデル(LLM)の推論精度を向上させる自己整合性(Self-Consistency)は、全推論経路を最後まで生成するため計算コストが極めて高いという課題がありますが、本研究は推論の初期段階である「接頭辞」に正解を予測する強力な信号が含まれるという「接頭辞の合意」現象に着目した新手法PoLR(Path of Least Resistance)を提案しました。 PoLRは、まず複数の短い接頭辞を生成してクラスタリングを行い、最も支配的な推論グループのみを最後まで拡張することで、精度を維持または向上させながらトークン使用量を最大60パーセント、実行時間を最大50パーセント削減することに成功しており、モデルの微調整を必要としない推論時のプラグインとして機能します。 数学(GSM8K、MATH500、AIME24/25)や科学(GPQA-DIAMOND)などの難解な推論タスクにおいて、既存の適応型推論手法(Adaptive Consistencyなど)と組み合わせることでさらなる効率化が可能であり、1.5Bから32Bまでの多様なモデル規模でその有効性と実用性が実証されました。
TL;DR(結論)
大規模言語モデル(LLM)の推論精度を向上させる自己整合性(Self-Consistency)は、全推論経路を最後まで生成するため計算コストが極めて高いという課題がありますが、本研究は推論の初期段階である「接頭辞」に正解を予測する強力な信号が含まれるという「接頭辞の合意」現象に着目した新手法PoLR(Path of Least Resistance)を提案しました。 PoLRは、まず複数の短い接頭辞を生成してクラスタリングを行い、最も支配的な推論グループのみを最後まで拡張することで、精度を維持または向上させながらトークン使用量を最大60パーセント、実行時間を最大50パーセント削減することに成功しており、モデルの微調整を必要としない推論時のプラグインとして機能します。 数学(GSM8K、MATH500、AIME24/25)や科学(GPQA-DIAMOND)などの難解な推論タスクにおいて、既存の適応型推論手法(Adaptive Consistencyなど)と組み合わせることでさらなる効率化が可能であり、1.5Bから32Bまでの多様なモデル規模でその有効性と実用性が実証されました。
なぜこの問題か
大規模言語モデル(LLM)は、数学の問題解決や高度な科学的推論において優れた能力を示していますが、その性能を最大限に引き出すためには、推論時の戦略が不可欠です。現在、最も標準的かつ効果的な手法の一つとして知られているのが自己整合性(Self-Consistency, SC)です。この手法は、同じ問題に対して複数の異なる推論経路(Chain-of-Thought)をサンプリングし、最終的な回答の多数決をとることで、単一の生成よりも大幅に精度を向上させます。しかし、自己整合性には致命的な欠点があります。それは、すべての推論経路を最後まで完全に生成しなければならないため、計算コスト、トークン消費量、および実行待ち時間(レイテンシ)が膨大になるという点です。 この計算コストの問題を解決するために、適応型整合性(Adaptive Consistency, AC)や早期停止自己整合性(Early-Stopping SC, ESC)といった手法が提案されてきました。これらの手法は、推論経路を逐次的に生成し、十分な合意が得られた時点で生成を停止することで効率化を図ります。しかし、これらの既存手法には共通の限界があります。…
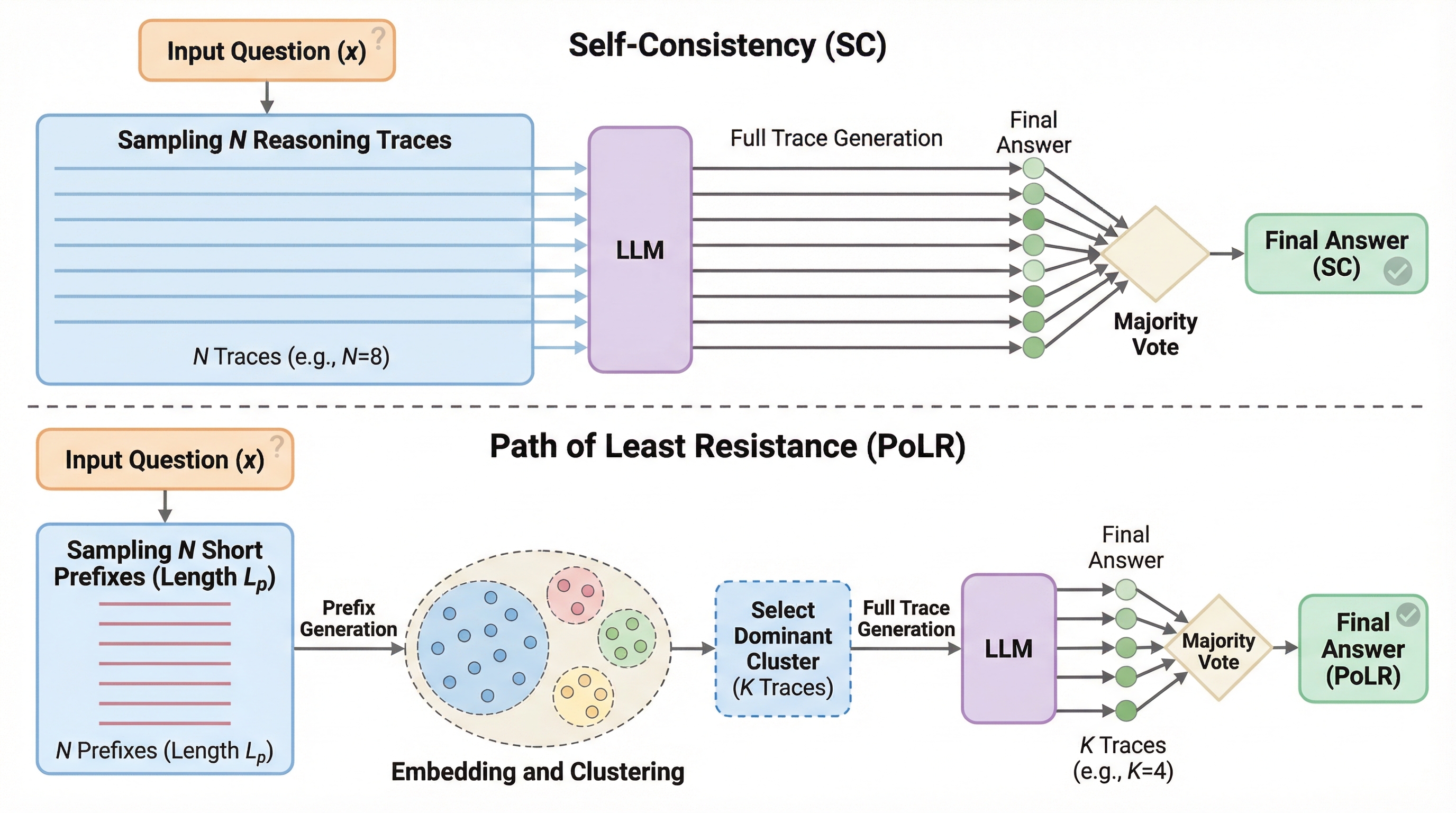
核心:何を提案したのか
本研究は、推論時の自己整合性を効率化するための新しい手法として「PoLR(Path of Least Resistance:最小抵抗の経路)」を提案しました。この名称は、システムは不必要な回り道を避け、エネルギーを節約しながら最も抵抗の少ない経路をたどるという自然界の原理に由来しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related