タスク認識はLLMの生成と不確実性を改善する
大規模言語モデル(LLM)の出力は、自然言語の形式をとりながらも、その背後にはラベル、数値、グラフといった特定のタスク構造が潜在していますが、従来のデコーディング手法は言語空間のみで動作し、この構造的情報を十分に活用できていないという課題がありました。
TL;DR(結論)
大規模言語モデル(LLM)の出力は、自然言語の形式をとりながらも、その背後にはラベル、数値、グラフといった特定のタスク構造が潜在していますが、従来のデコーディング手法は言語空間のみで動作し、この構造的情報を十分に活用できていないという課題がありました。本研究は、LLMの出力をタスク依存の潜在構造として直接モデリングし、潜在空間内での不一致尺度を用いることで、サンプリングされた複数の回答を統合して新たに合成する「ベイズ最適回答」を算出する汎用的なフレームワークを提案しました。検証の結果、提案手法はビームサーチや自己整合性などの標準的な手法を一貫して上回る性能を示し、さらに誘導されたベイズリスクを通じて、出力の品質や正解性とより密接に整合する、原理に基づいた不確実性の定量化が可能になることが実証されました。
なぜこの問題か
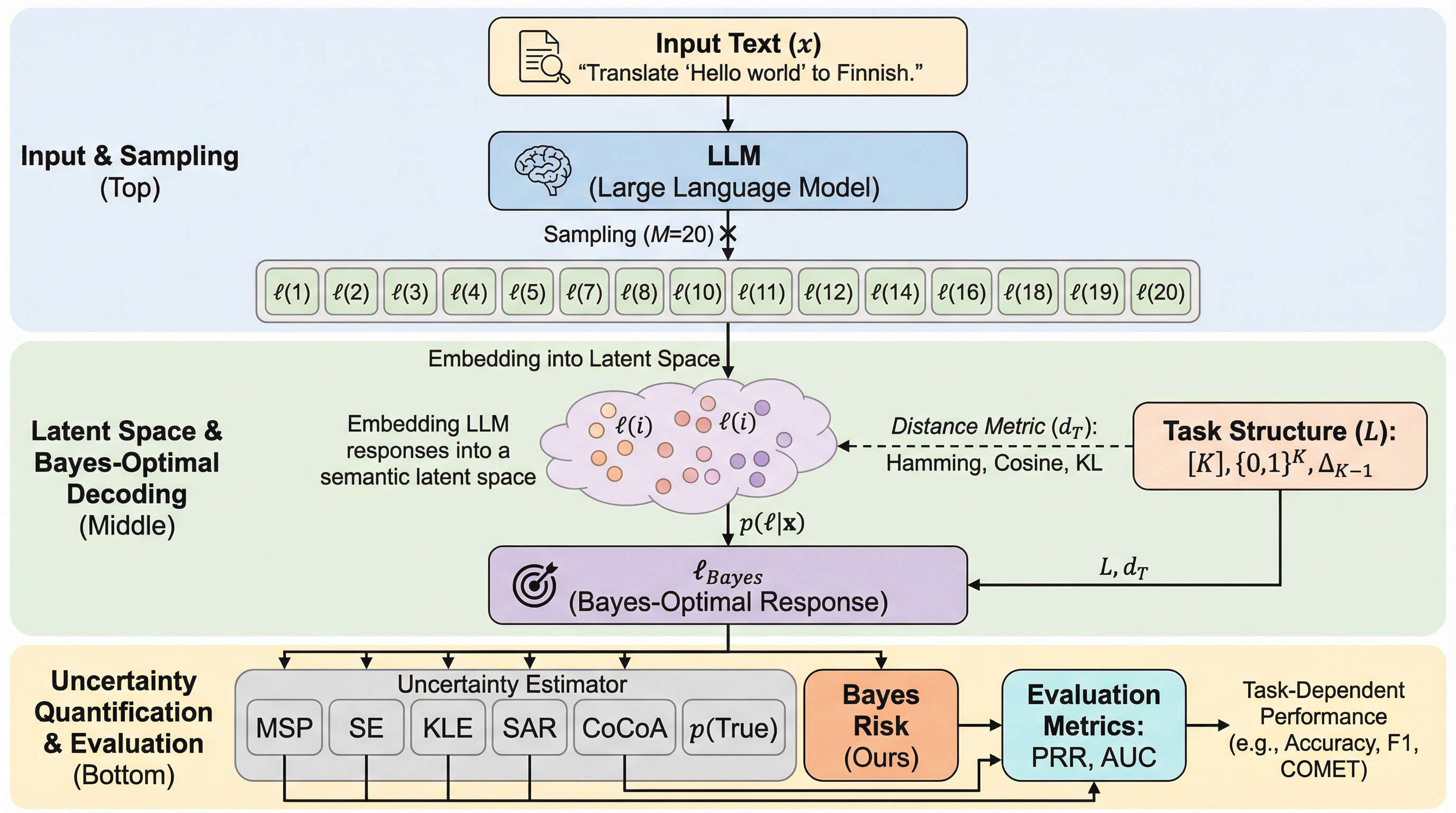
大規模言語モデル(LLM)は、事実に関する質問回答から機械翻訳、要約、推論まで、極めて多岐にわたるタスクで高い汎用性を示すシステムとして普及しています。しかし、LLMをプロンプトで運用する際、その回答の具体的なセマンティクス(意味論)は事前には不明であるものの、期待される出力のドメインや形式は暗黙的に与えられていることが一般的です。例えば、「ナミビアの首都は?」という質問に対しては都市名が期待され、エッセイの評価を求める場合には特定の範囲の数値スコアが期待されます。LLMは自然言語のトークン列を生成するように訓練されていますが、実際のタスクそのものは、明確なタスク固有の潜在構造に関連付けられていることが多いのが実情です。 自由形式の自然言語と比較して、これらの潜在構造は、下流のアプリケーションにおいてLLMの予測を解釈したり、複数の予測を比較したりするのに適しています。多くの自動化されたワークフローにおいて、最終的な意思決定は言語的な表現の微細な違いよりも、タスクレベルの意味論的な正解性に依存しています。…
核心:何を提案したのか
本研究では、タスク固有の潜在構造を認めるあらゆる問題に適用可能な、高度に一般的な意思決定理論的フレームワークを提案しました。このフレームワークの核心は、LLMの回答を直接、タスク依存の潜在構造 $L$ の中でモデリングすることにあります。具体的には、自然言語の文字列からタスク固有の潜在表現へのマッピング関数 $gT$ を定義することで、潜在空間におけるLLMの予測分布を誘導します。これにより、言語の表面的な差異を排除し、タスクの本質的な意味内容に基づいた処理が可能になります。 この潜在構造に不一致尺度(非類似度) $dT$ を備えさせることで、ベイズリスクを最小化する「ベイズ最適回答」を計算することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related