因果性がない解釈可能性は一般化しないのか:LLM内部解析の主張と証拠をそろえるための因果推論フレーム
大規模言語モデルの解釈可能性研究は有益な道具立てを増やしてきましたが、観測や介入で得た証拠の範囲を越えて因果的・反事実的に語ると、別条件で再現せず一般化しない落とし穴が残ります。 / 因果推論の語彙を使って、相関・介入効果・反事実という問いの段を区別し、狙う量(推定したい量)と許す介入の範囲、証拠から区別できない説明のまとまり(同値類)を明示して、主張と評価の対応を固定します。 / 反事実の主張は制御された監督がないと大部分が検証しにくく、因果表現学習は「活性から何が、どの仮定の下で復元可能か」を整理するため、実務で方法選択と評価設計を診断的に進める含意があります。
TL;DR(結論)
- 大規模言語モデルの解釈可能性研究は有益な道具立てを増やしてきましたが、観測や介入で得た証拠の範囲を越えて因果的・反事実的に語ると、別条件で再現せず一般化しない落とし穴が残ります。
- 因果推論の語彙を使って、相関・介入効果・反事実という問いの段を区別し、狙う量(推定したい量)と許す介入の範囲、証拠から区別できない説明のまとまり(同値類)を明示して、主張と評価の対応を固定します。
- 反事実の主張は制御された監督がないと大部分が検証しにくく、因果表現学習は「活性から何が、どの仮定の下で復元可能か」を整理するため、実務で方法選択と評価設計を診断的に進める含意があります。
なぜこの問題か
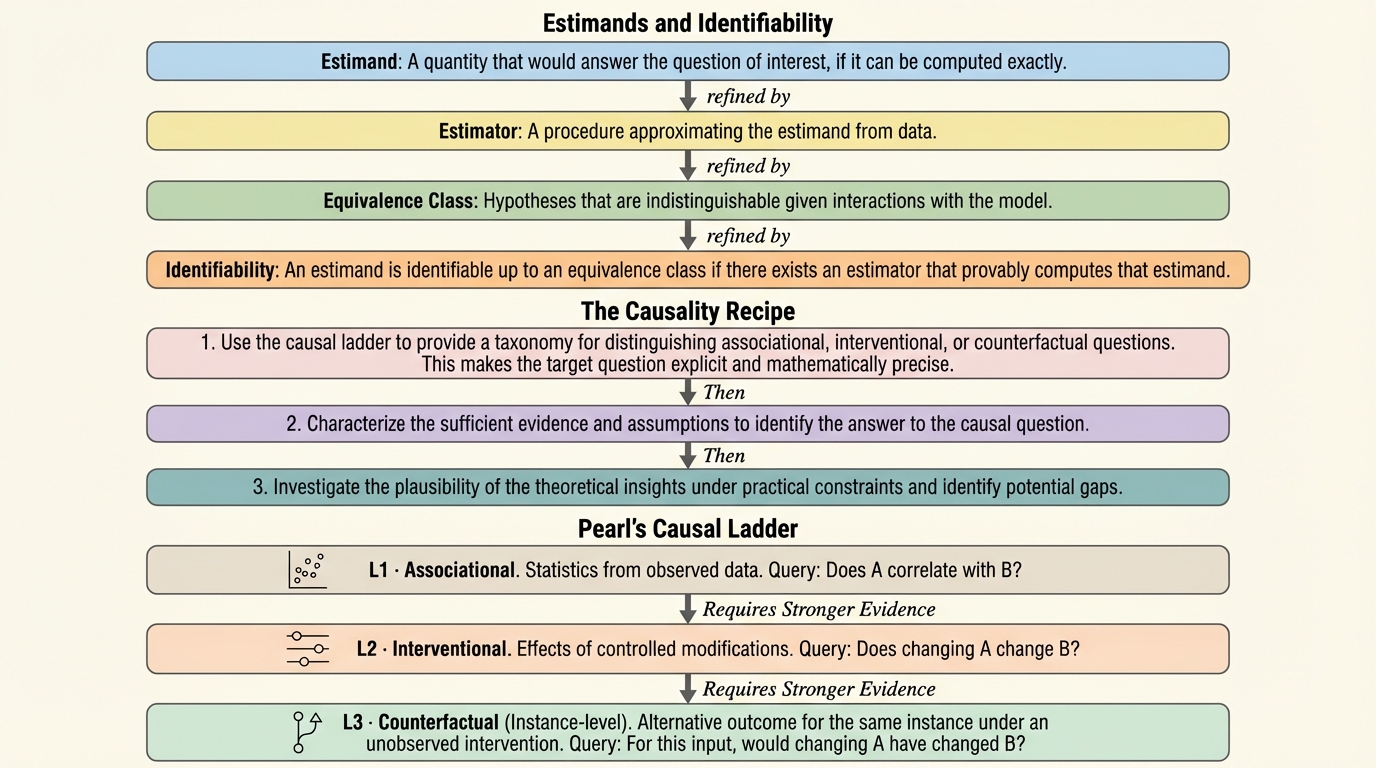
大規模言語モデルの解釈可能性研究は、モデルのふるまいと内部構造を結びつけるための多様な手法を生み、重要な洞察を与えてきました。たとえば内部の計算を追跡して課題計算を説明しようとしたり、特定の構成要素の寄与を局所化したり、疎な特徴を取り出して人間が読めそうな説明へ近づけたりする流れが広がっています。ところが同時に、研究者や実務者が繰り返し直面する落とし穴として、「見つかった関係が別の状況に移ると一般化しない」ことと、「証拠の強さを越えて因果的に解釈してしまう」ことが挙げられています。本文抜粋では、線形プローブが高い精度で概念を読み出せても、その方向に沿って内部状態を操作しても安定した行動変化が得られない例や、テスト集合である行動を抑えられても分布が変わると同じ回路が脆くなる例が示されています。これらは、局所的な成功と信頼できる運用のあいだにギャップがあることを意味します。重要なのは、予測が当たること自体は「操作可能なメカニズムが存在する」ことの根拠にはならない、という認識です。…
核心:何を提案したのか
本稿の中心的な立場は、解釈可能性の主張を一般化させる鍵として因果性を据え、因果推論によって「活性から不変な高次構造への妥当な写像」とは何かを規定しようとする点にあります。ここでいう規定とは、必要なデータや仮定を明確にし、その上でどの種類の推論が許されるのかを整理することです。具体的には、Pearlの因果階層を用いて、解釈可能性研究が何を正当化できるかを分類します。観測に基づく結果は、モデル行動と内部要素のあいだの関連(相関)を示すにとどまります。アブレーションやactivation patchingのような介入は、特定の編集が行動指標をどう変えるかという介入効果の主張を支えますが、その主張は「評価したプロンプト集合」と「選んだ指標」の範囲に結びついています。一方で、同じプロンプトに対して未観測の介入をしていたら出力はどうなっていたか、という反事実の問いは、制御された監督なしには大部分が検証できないと位置づけられます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related