LLMの感情制御におけるスタイルベクトルの有効性:人間による評価
本研究は、大規模言語モデル(LLM)の内部活性化を直接操作する「アクティベーション・ステアリング」を用い、出力の感情トーンを制御する手法の有効性を、190人の参加者による7,000件以上の評価を通じて初めて人間中心の視点から検証した。 実験の結果、ステアリング強度を適切な値($\lambda \approx 0.
TL;DR(結論)
本研究は、大規模言語モデル(LLM)の内部活性化を直接操作する「アクティベーション・ステアリング」を用い、出力の感情トーンを制御する手法の有効性を、190人の参加者による7,000件以上の評価を通じて初めて人間中心の視点から検証した。 実験の結果、ステアリング強度を適切な値($\lambda \approx 0.15$)に設定することで、テキストの品質や理解しやすさを維持しながら、特定の感情(特に嫌悪や恐怖)を効果的に強調できることが明らかになり、自動評価指標と人間の知覚の間にも高い相関(r=0.776)が確認された。 Llama-3-8Bなどの最新モデルにおいて、スタイルベクトルはプロンプトエンジニアリングよりも微細な感情制御を可能にするスケーラブルな手法であり、航空宇宙や医療などの安全性が重視される分野における人間とAIの円滑なコミュニケーションを促進する可能性を示している。
なぜこの問題か
大規模言語モデル(LLM)は、人間と見間違うような高度な対話能力を獲得しているが、その内部プロセスは依然としてブラックボックスな部分が多く、出力の感情やトーンを正確に制御することは困難な課題である。教育、カスタマーサポート、医療、さらには航空宇宙のような安全性が極めて重要なドメインにおいて、AIエージェントが単に正しい情報を伝えるだけでなく、人間の感情的要因を考慮し、状況に適応したコミュニケーションを行うことは、ユーザーの信頼や受容性を高めるために不可欠な要素となっている。これまでの研究では、プロンプトエンジニアリングやファインチューニングといった手法が主に用いられてきた。しかし、プロンプトによる制御は指示の与え方によって結果が不安定になりやすく、強度の微調整が難しいという欠点がある。一方で、ファインチューニングはモデル全体を再学習させる必要があり、膨大な計算リソースと時間を消費するため、大規模なモデルに適用するには非効率的である。…
核心:何を提案したのか
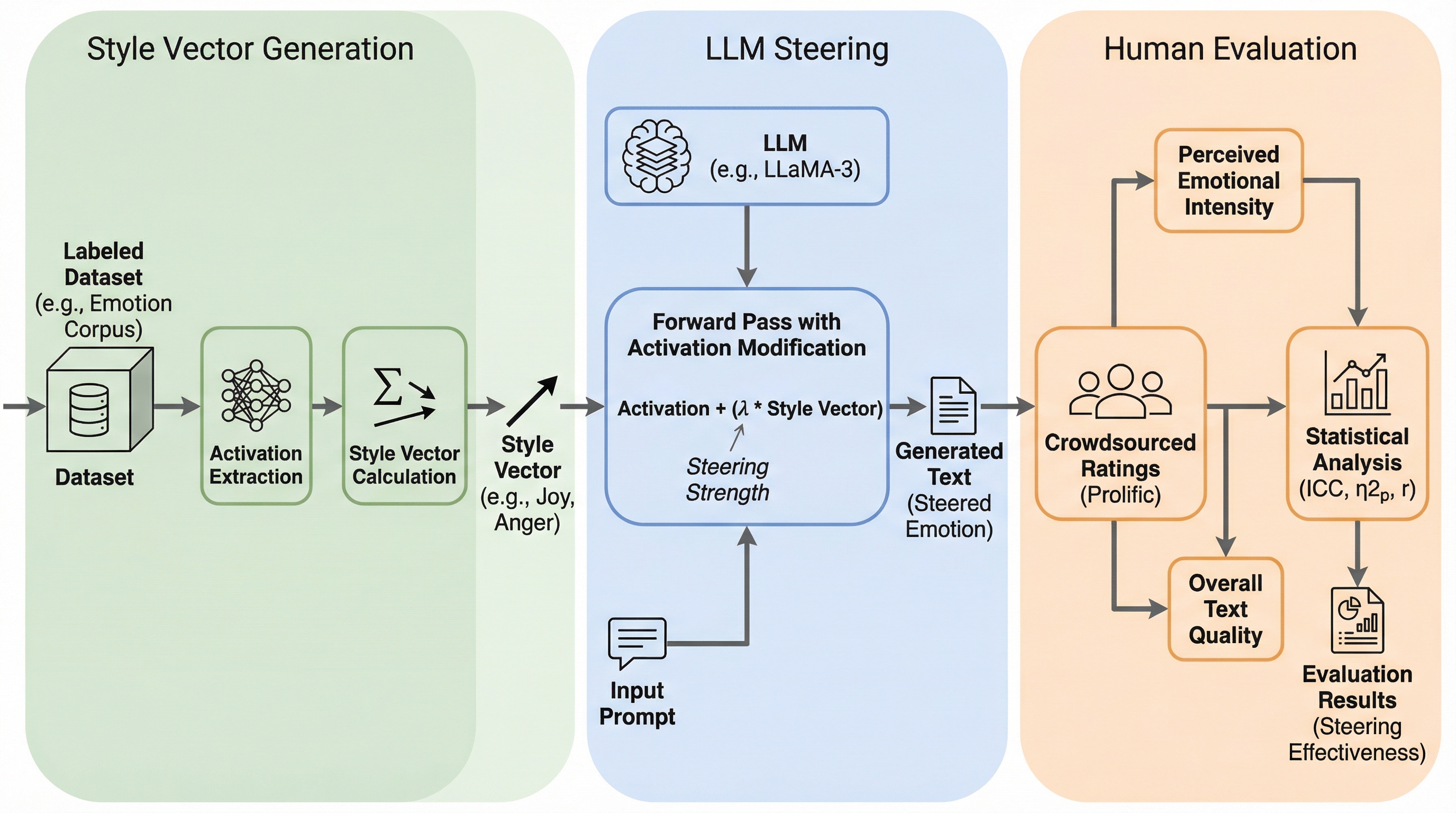
本研究では、LLMの推論時に内部の活性化ベクトルを直接修正することで、出力のスタイルや感情を制御する「アクティベーション・ステアリング」の有効性を提案し、その人間による評価を包括的に実施した。具体的には、特定の感情(ターゲットスタイル)を持つデータセットから抽出された活性化パターンの平均と、それ以外の感情(対照スタイル)の平均との差分を「スタイルベクトル」として定義し、これを推論時の各レイヤーに加算する手法を採用している。このアプローチの核心は、モデルを再学習させることなく、単一のパラメータであるステアリング強度($\lambda$)を調整するだけで、ラジオのボリュームを操作するように感情の強弱を直感的に制御できる点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related