ETS: 強化学習アライメントを学習なしで実現するエネルギー誘導型テスト時スケーリング
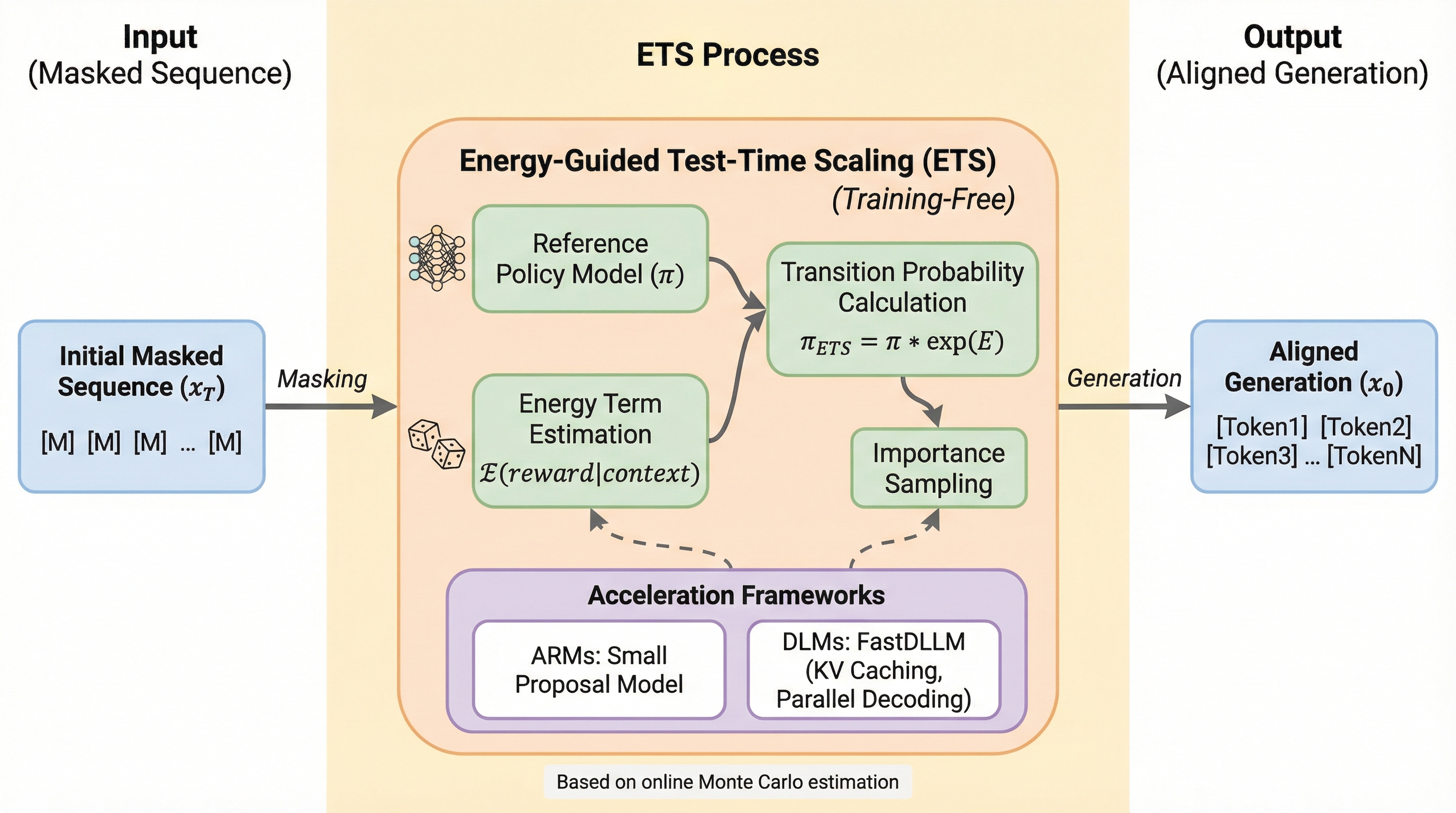
言語モデルの強化学習(RL)による事後学習アライメントは、複雑なトレーニングプロセスや高コストな報酬モデリング、不安定な学習動態といった課題を抱えていますが、本研究では追加の学習を一切行わずに推論時に最適なRLポリシーから直接サンプリングを行う手法「Energy-Guided Test-Time Scaling(ETS)」を提案しています。 ETSは、マスク言語モデリング(MLM)の枠組みにおいて遷移確率をリファレンスポリシーとエネルギー項に分解し、オンラインモンテカルロ法を用いてこのエネルギー項を推定することで、学習なしでのアライメントを実現し、推論時の計算量を増やすことで生成品質を向上させる新しいテスト時スケーリングの形態を提示しています。 実用的な効率を確保するために、重点サンプリングと軽量なプロポーザルモデルを組み合わせた加速戦略を導入しており、理論的な収束性を保証しながら推論の遅延を大幅に削減し、推論やコーディングなどのベンチマークにおいて従来の学習ベースのRL手法を凌駕する性能を一貫して達成していることが確認されました。
TL;DR(結論)
言語モデルの強化学習(RL)による事後学習アライメントは、複雑なトレーニングプロセスや高コストな報酬モデリング、不安定な学習動態といった課題を抱えていますが、本研究では追加の学習を一切行わずに推論時に最適なRLポリシーから直接サンプリングを行う手法「Energy-Guided Test-Time Scaling(ETS)」を提案しています。 ETSは、マスク言語モデリング(MLM)の枠組みにおいて遷移確率をリファレンスポリシーとエネルギー項に分解し、オンラインモンテカルロ法を用いてこのエネルギー項を推定することで、学習なしでのアライメントを実現し、推論時の計算量を増やすことで生成品質を向上させる新しいテスト時スケーリングの形態を提示しています。 実用的な効率を確保するために、重点サンプリングと軽量なプロポーザルモデルを組み合わせた加速戦略を導入しており、理論的な収束性を保証しながら推論の遅延を大幅に削減し、推論やコーディングなどのベンチマークにおいて従来の学習ベースのRL手法を凌駕する性能を一貫して達成していることが確認されました。
なぜこの問題か
大規模言語モデル(LLM)を人間の意図や好みに適合させるための主要な手法として、強化学習(RL)を用いた事後学習アライメントが広く採用されています。しかし、このパラダイムには実用上の根本的な制限が数多く存在することが指摘されています。まず、報酬モデルの構築には膨大なコストがかかり、大規模な人間の好みのデータセットを必要とします。また、学習プロセス自体が非常に不安定であり、ハイパーパラメータの設定に対して極めて敏感であるという性質を持っています。さらに、報酬の設計や基準が変更されるたびに、モデルのトレーニングを最初からやり直す必要があり、これには多大な計算資源と人的コストが費やされることになります。 理論的には、KL正則化を伴うRLの目的関数には閉形式の最適解が存在することが数学的に証明されています。しかし、既存の学習ベースの手法(PPOやDPOなど)は、この最適解の構造を直接利用するのではなく、勾配ベースの反復的な最適化によって近似しようとしています。このアプローチは、計算効率や安定性の面で非効率である可能性があります。…
核心:何を提案したのか
本研究が提案する「Energy-Guided Test-Time Scaling(ETS)」は、学習を必要としない推論時のサンプリング手法であり、最適なRLポリシーからの直接的な出力を可能にします。この手法の核心は、自己回帰モデル(ARM)や拡散言語モデル(DLM)を包含する一般的なマスク言語モデリング(MLM)の枠組みにおいて、最適な遷移カーネルが二つの要素に分解できることを理論的に示した点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related