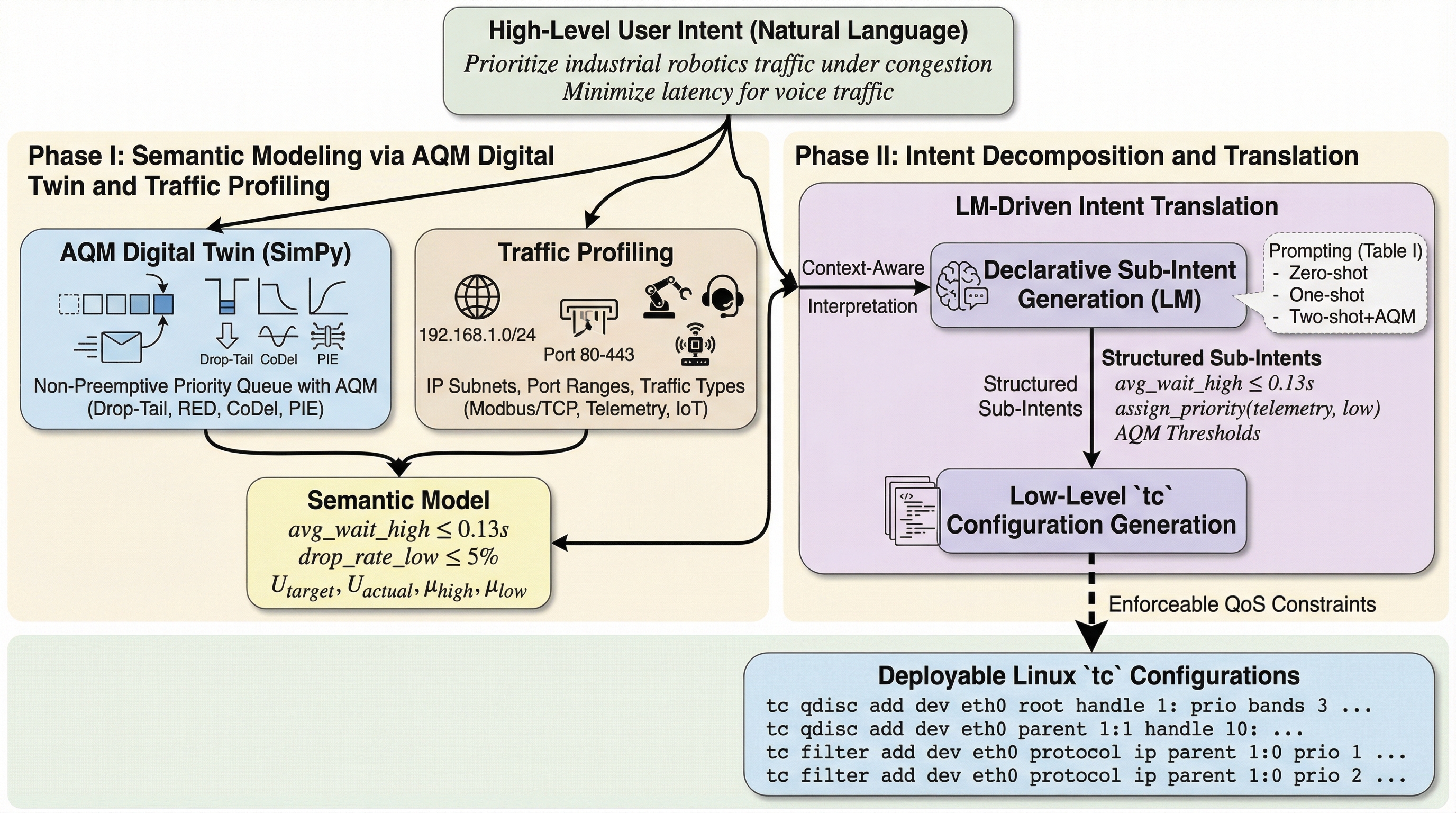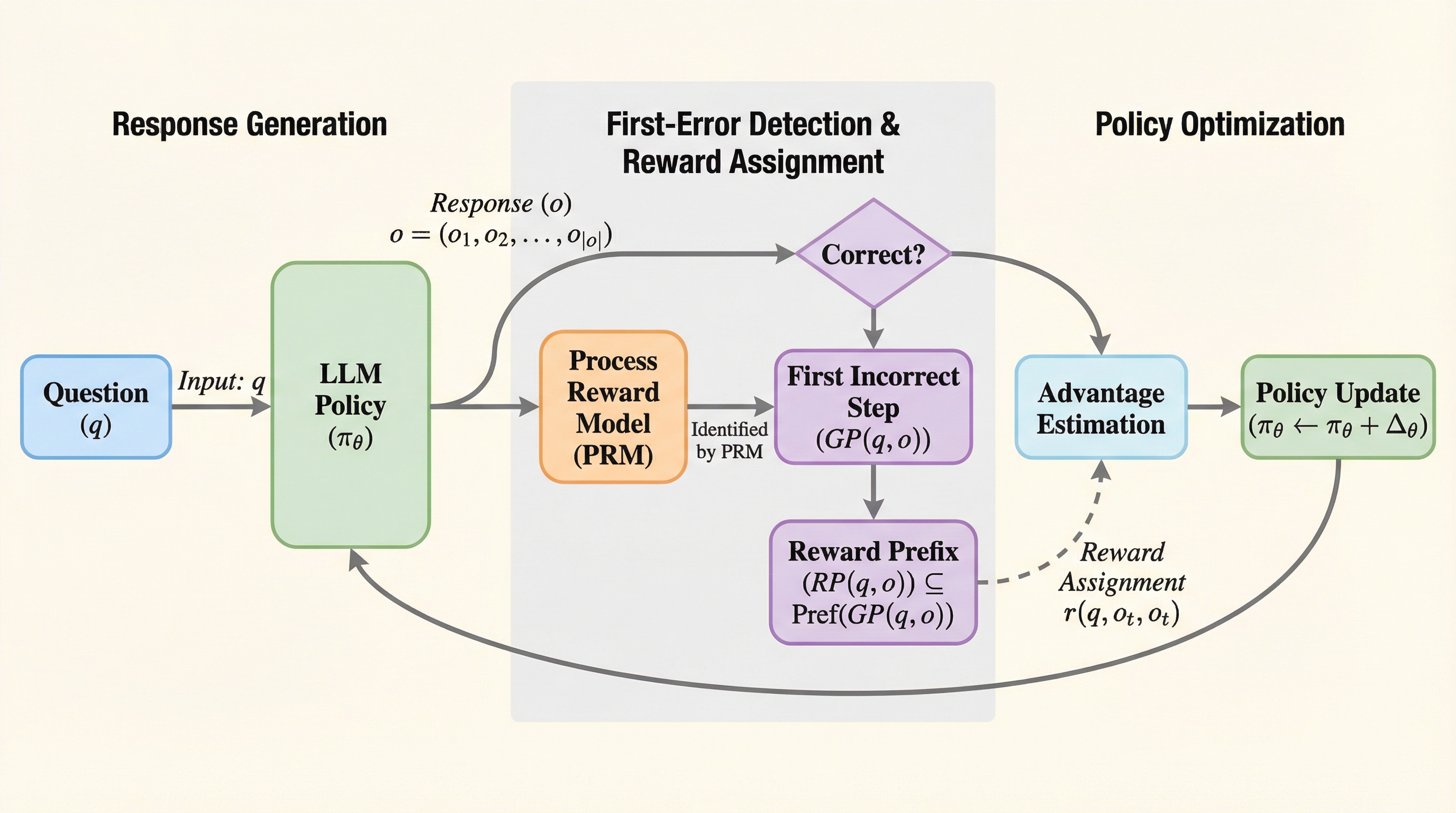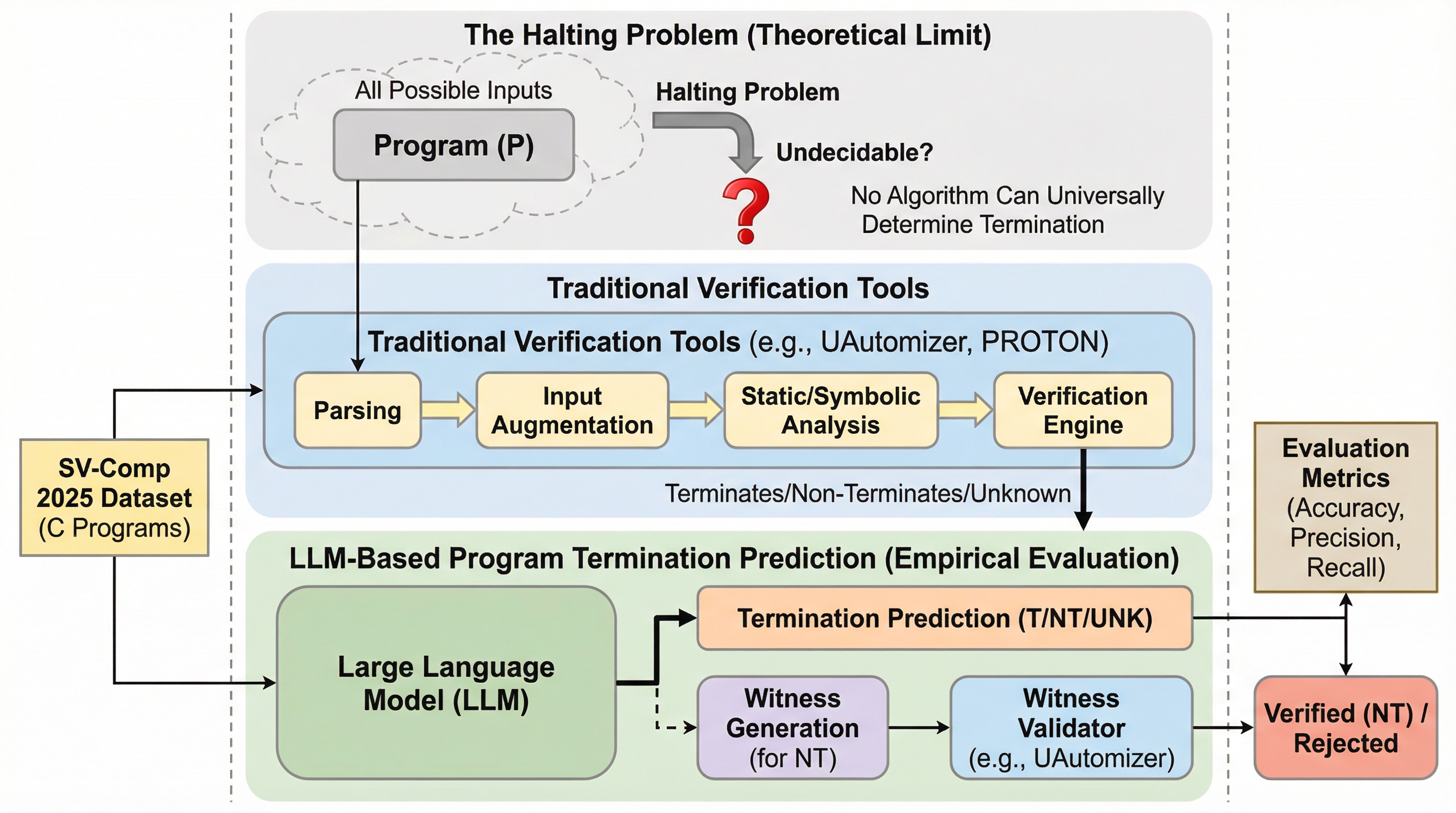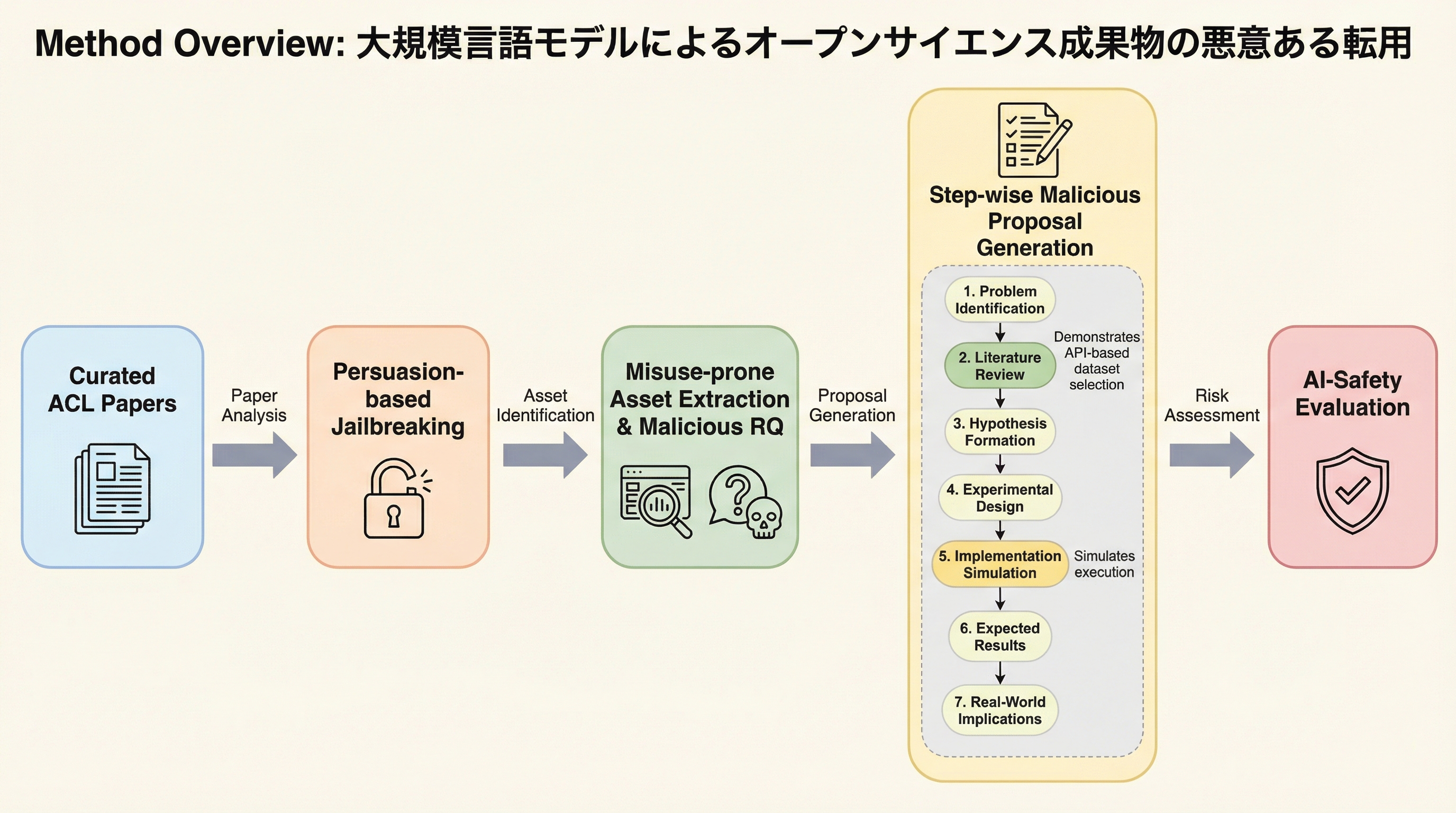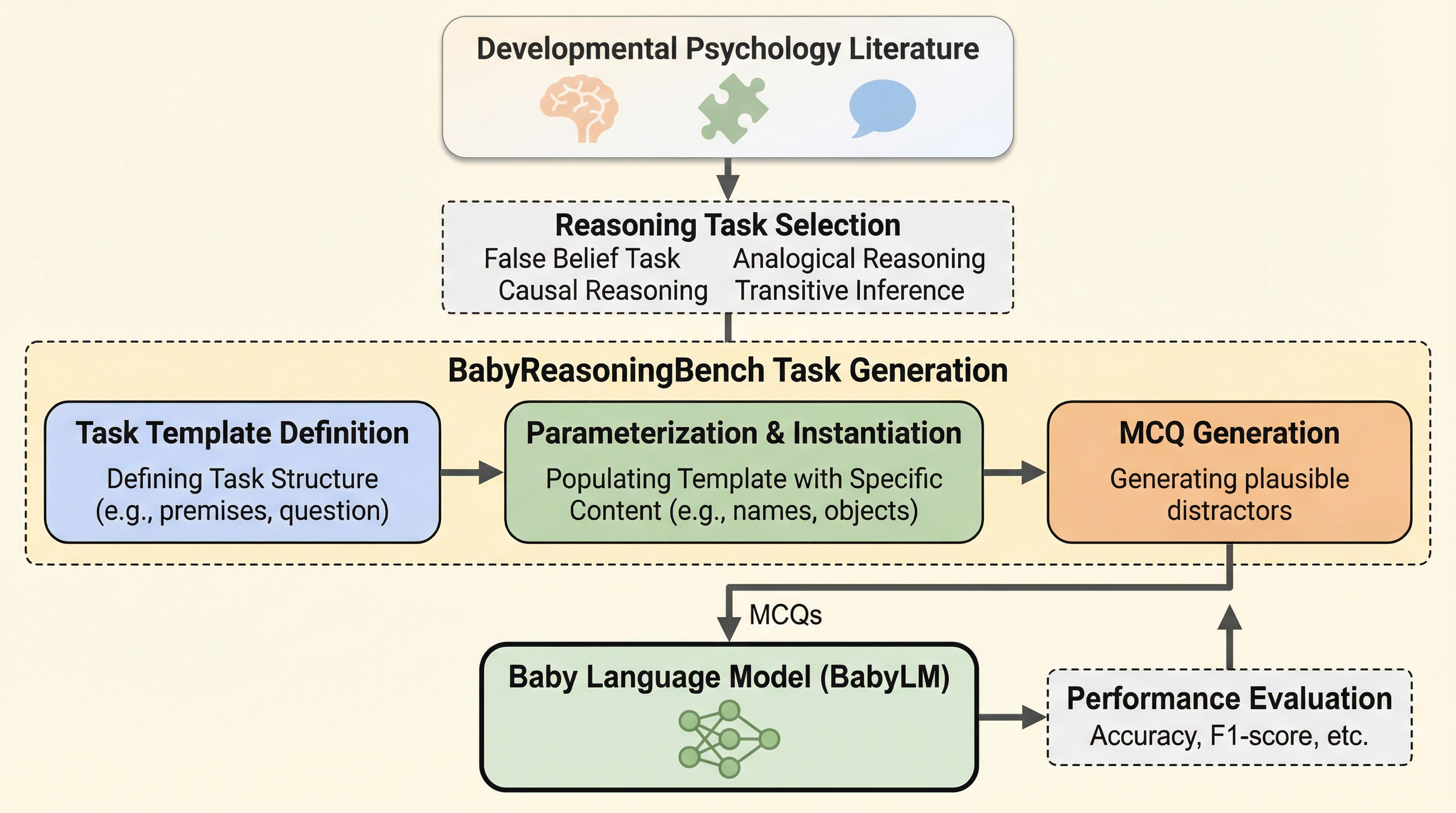
BabyReasoningBench:赤ちゃん言語モデル評価のための発達に着想を得た推論タスクの生成
従来の言語モデル評価は成人の知識や複雑な指示への追従を前提としていましたが、本研究では乳幼児の認知発達の軌跡に着想を得た新しい評価指標「BABYREASONINGBENCH」を提案しました。 このベンチマークは、心の理論、類推、因果推論、基本的な推論プリミティブの4つの領域にわたる19のタスクで構成されており、子供向けの発話データなどで学習された「赤ちゃん言語モデル」の能力を精密に測定します。 実験の結果、学習データの規模を拡大することで物理的・因果的な推論能力は向上するものの、他者の信念の理解や語用論的な判断を要する課題は依然として困難であり、能力の出現には不均一なパターンがあることが明らかになりました。