より細かければ良いのか? 大規模言語モデルにおけるマイクロ・スケーリング形式の限界
大規模言語モデルの圧縮において、量子化ブロックのサイズを小さくするほど精度が向上するという従来の定説に反し、特定の閾値を下回ると逆に誤差が増大する「パープレキシティ反転」という現象が発見されました。
TL;DR(結論)
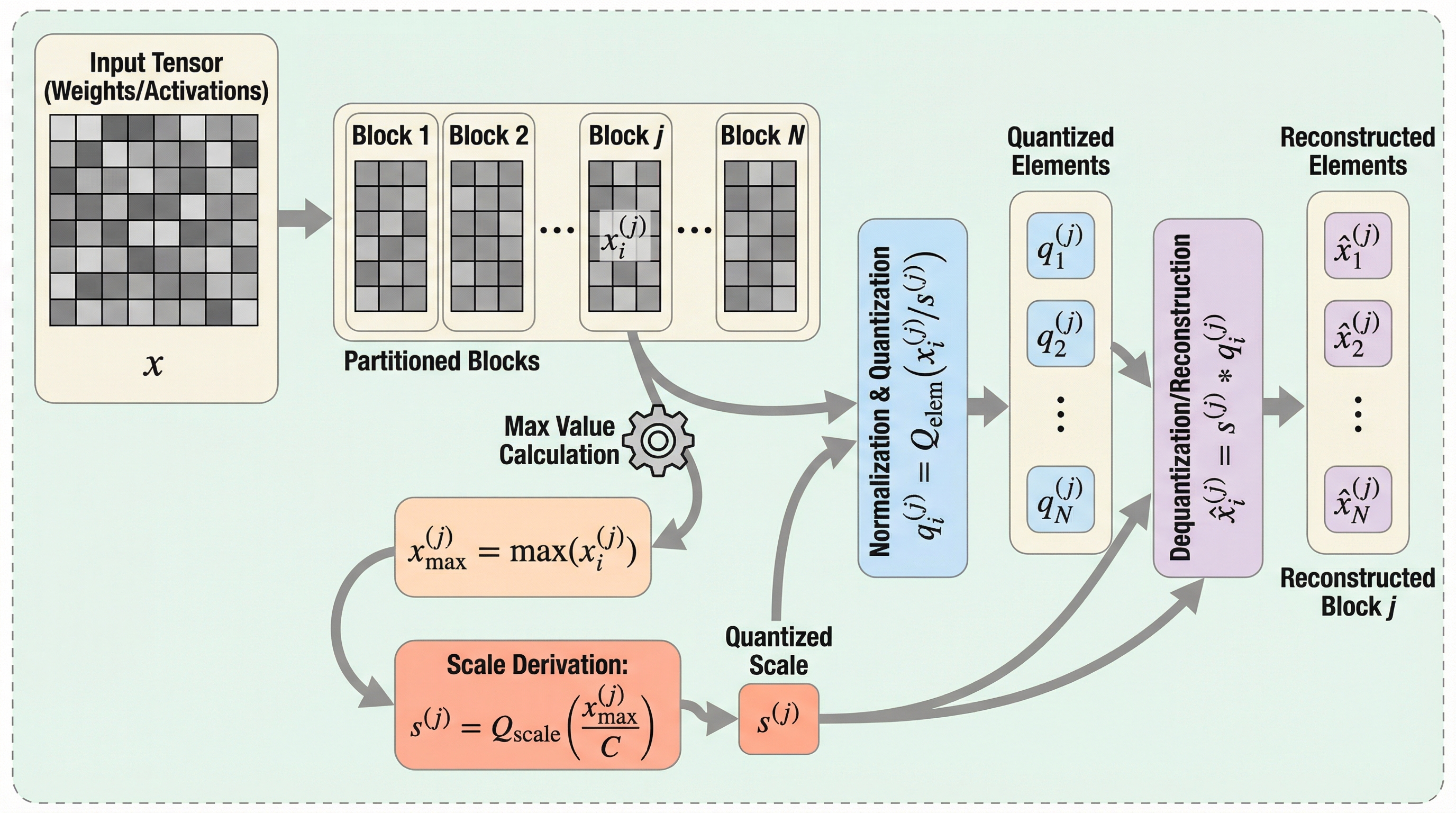
大規模言語モデルの圧縮において、量子化ブロックのサイズを小さくするほど精度が向上するという従来の定説に反し、特定の閾値を下回ると逆に誤差が増大する「パープレキシティ反転」という現象が発見されました。 この異常な挙動は、テンソルの分布が狭い(標準偏差が小さい)場合に、量子化されたスケール因子のダイナミックレンジが不足し、低振幅のブロックを正確に表現できなくなることで発生することが理論と実験の両面で証明されました。 対策として、従来のFP8 UE4M3形式のスケールに代わり、符号なしのFP8 UE5M3(UE5M3)形式をハードウェアに採用することで、グローバルなスケーリング操作を不要にしつつ、極小ブロックサイズでも精度を維持できることが提案されています。
なぜこの問題か
大規模言語モデル(LLM)の急速な発展は、自然言語処理に劇的な進歩をもたらしましたが、同時に計算資源、メモリ、エネルギーに対する需要を爆発的に増大させています。モデルのパラメータ数は数千億に達し、コンテキストウィンドウも数十万トークンへと拡大しているため、効率的な学習と推論を実現するためには、数値精度を下げることが不可欠な戦略となっています。ハードウェアベンダーは、スループットとエネルギー効率を高めるために、FP16からFP8、さらにはFP4へと精度を段階的に移行させてきました。しかし、精度を8ビット未満に押し下げると、特に重みと活性化の両方を量子化する場合に、モデルの精度が大幅に低下するという課題に直面します。 この制限に対処するため、量子化技術は精度と効率のバランスを取るために、よりきめ細かな制御へと進化してきました。初期の手法ではテンソル全体に単一のスケール因子を割り当てるテンソル単位の量子化が主流でしたが、これはダイナミックレンジが広い領域で大きな量子化誤差を招く原因となりました。その後、出力チャネルやトークンごとに独立したスケールを割り当てる手法が登場し、わずかなコストで精度を向上させました。…
核心:何を提案したのか
本研究の核心は、マイクロ・スケーリング形式においてブロックサイズを小さくすることが、直感に反して量子化誤差を増大させる可能性があるという「量子化の異常(アノマリー)」を発見し、そのメカニズムを解明したことにあります。通常、量子化の解像度を高めるためにブロックサイズを縮小すれば、各要素をより適切に表現できるため、誤差は単調に減少すると期待されます。しかし、特定の条件下ではこの期待が裏切られ、モデルの性能指標であるパープレキシティが悪化する「パープレキシティ反転」が発生することを突き止めました。 この現象を理解するために、研究チームは量子化誤差の発生源を分離して分析できる理論的枠組みを構築しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related