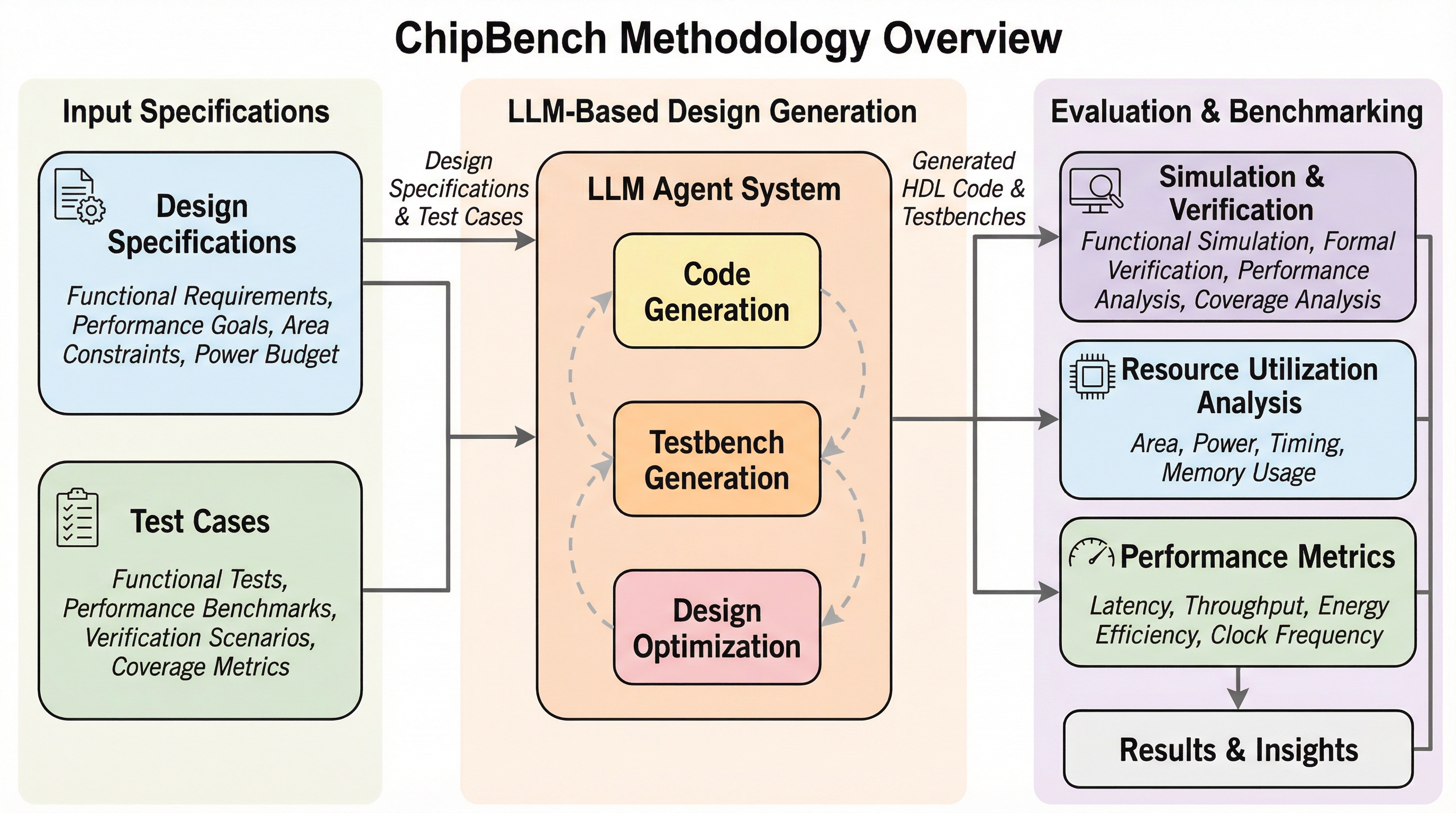
ChipBench: AIチップ設計支援におけるLLM性能評価のための次世代ベンチマーク
既存のAIチップ設計ベンチマークは単純なモジュールに限定され、最新の大規模言語モデル(LLM)が95%以上の成功率を達成するなど飽和状態にあり、実務の複雑な階層構造や設計の機微を評価できていない。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
既存のAIチップ設計ベンチマークは単純なモジュールに限定され、最新の大規模言語モデル(LLM)が95%以上の成功率を達成するなど飽和状態にあり、実務の複雑な階層構造や設計の機微を評価できていない。
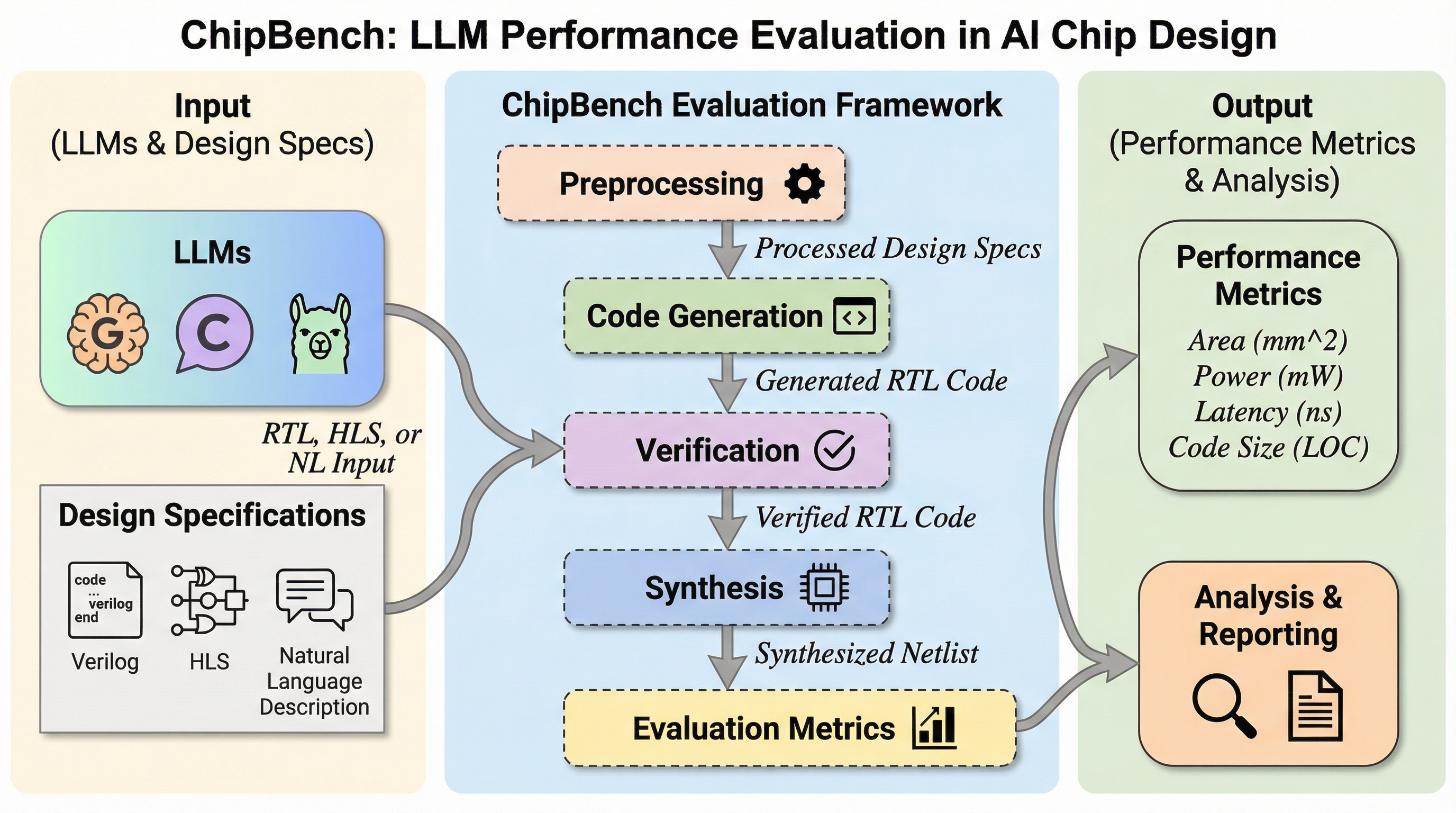
従来のVerilog評価ベンチマークが飽和し、最新のLLMが95%以上の合格率を達成する中で、産業レベルの複雑なチップ設計に対応するため、Verilog生成、デバッグ、リファレンスモデル生成の3つの重要タスクを網羅した「ChipBench」が提案されました。 本ベンチマークは、従来の3.8倍のコード長と13.
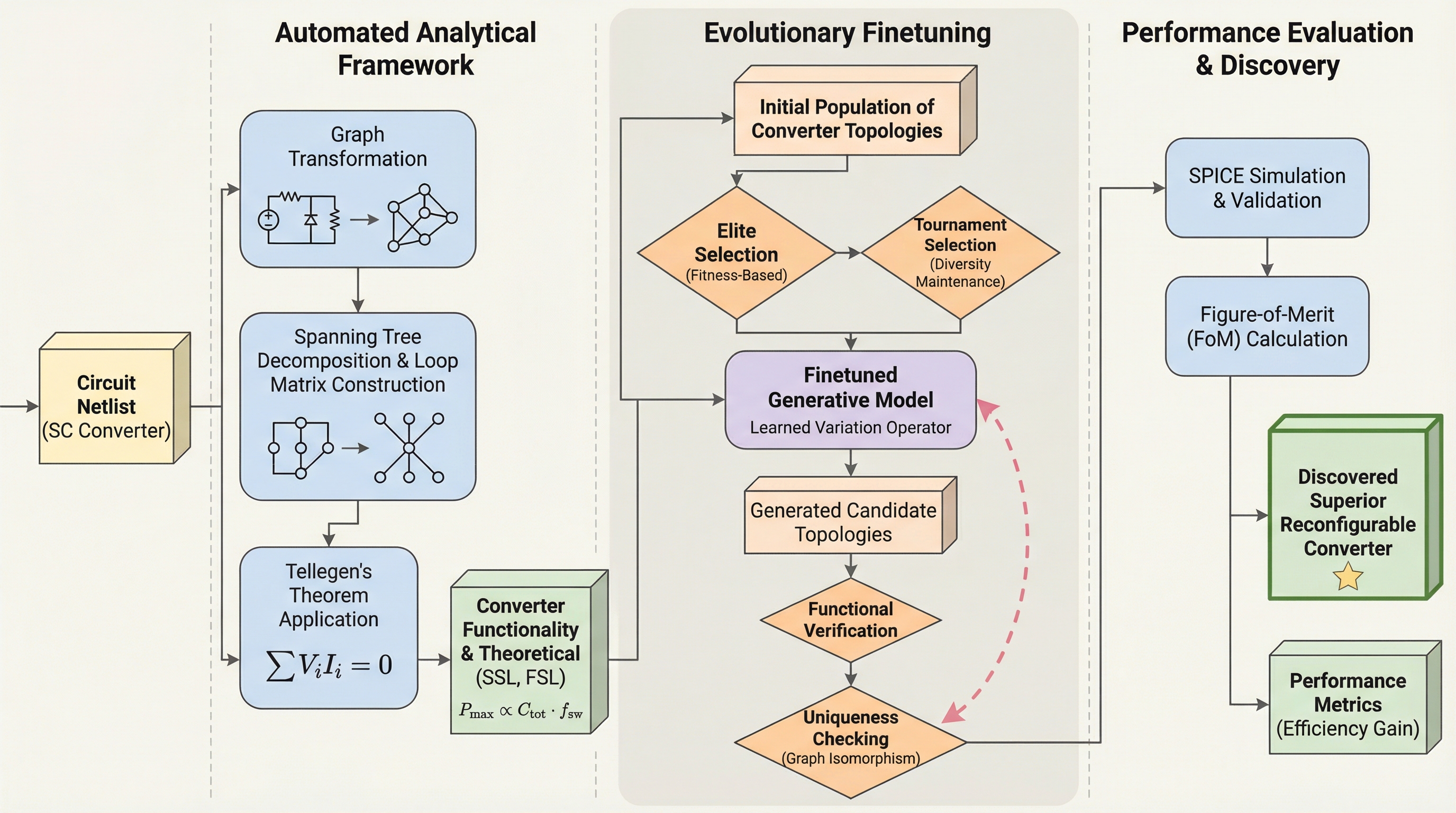
PowerGenieは、膨大な設計空間から高性能な再構成可能電力コンバータを自動発見するために開発された、解析的ガイド付きの新しいAIフレームワークである。 この手法は、グラフ理論とテリガンの定理に基づき、時間のかかるSPICEシミュレーションを介さずに回路の機能と理論的性能限界を数秒で特定する自動解析手法と、生成モデルと学習データを共に洗練させる進化的微調整を導入している。 結果として、従来の最高性能を23%上回る性能指数を持つ未知の8モード電力コンバータの発見に成功し、実機シミュレーションにおいて全モード平均で10%、最大で17%の効率向上を達成するという画期的な成果を収めた。
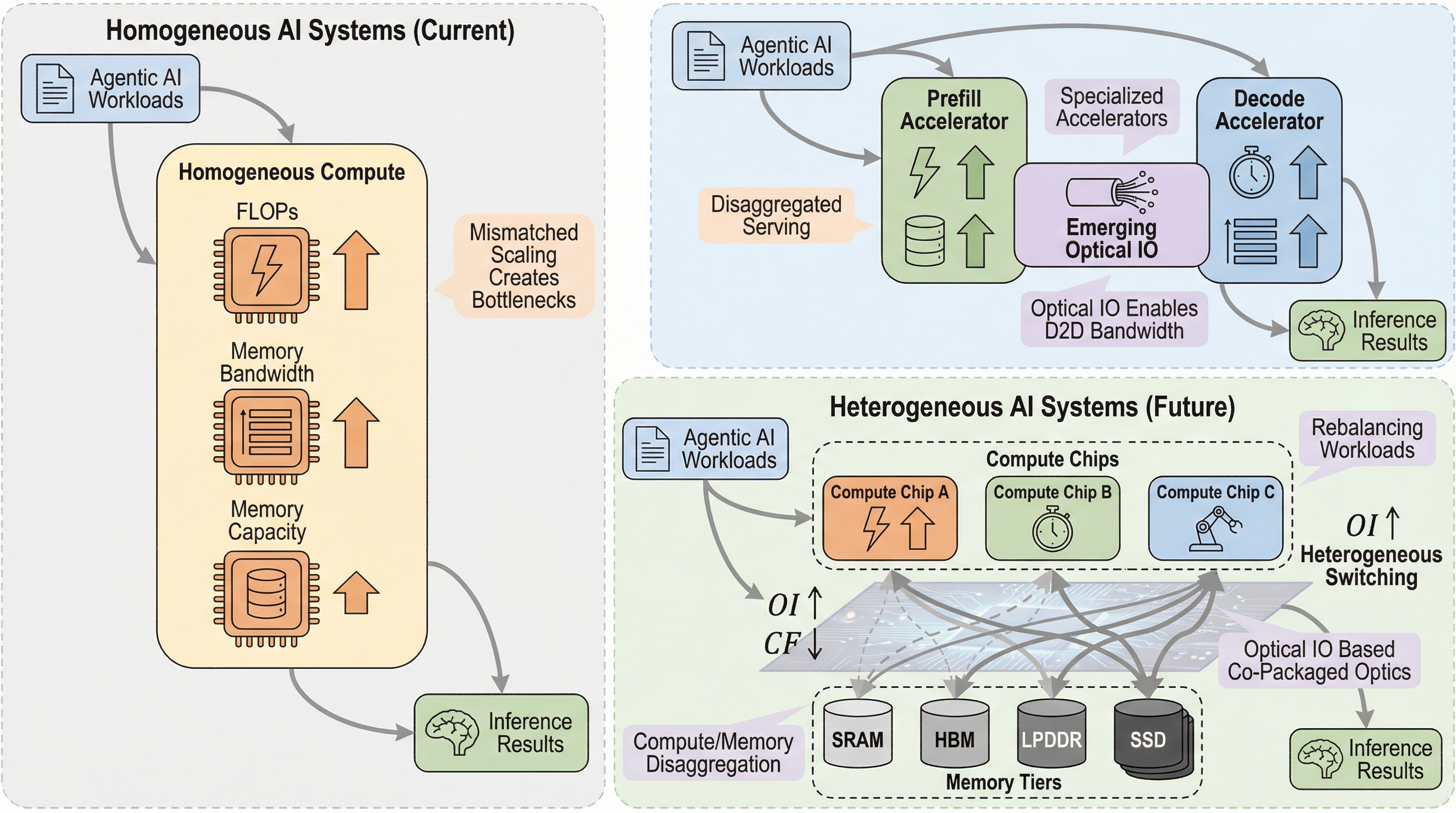
AIエージェントの普及により推論負荷が急増しており、従来のGPU中心の均一なインフラではメモリ帯域幅と容量の限界(メモリの壁)に直面するため、計算・ネットワーク・メモリの全域にわたるシステムレベルの異種(ヘテロジニアス)構成への移行が不可欠である。
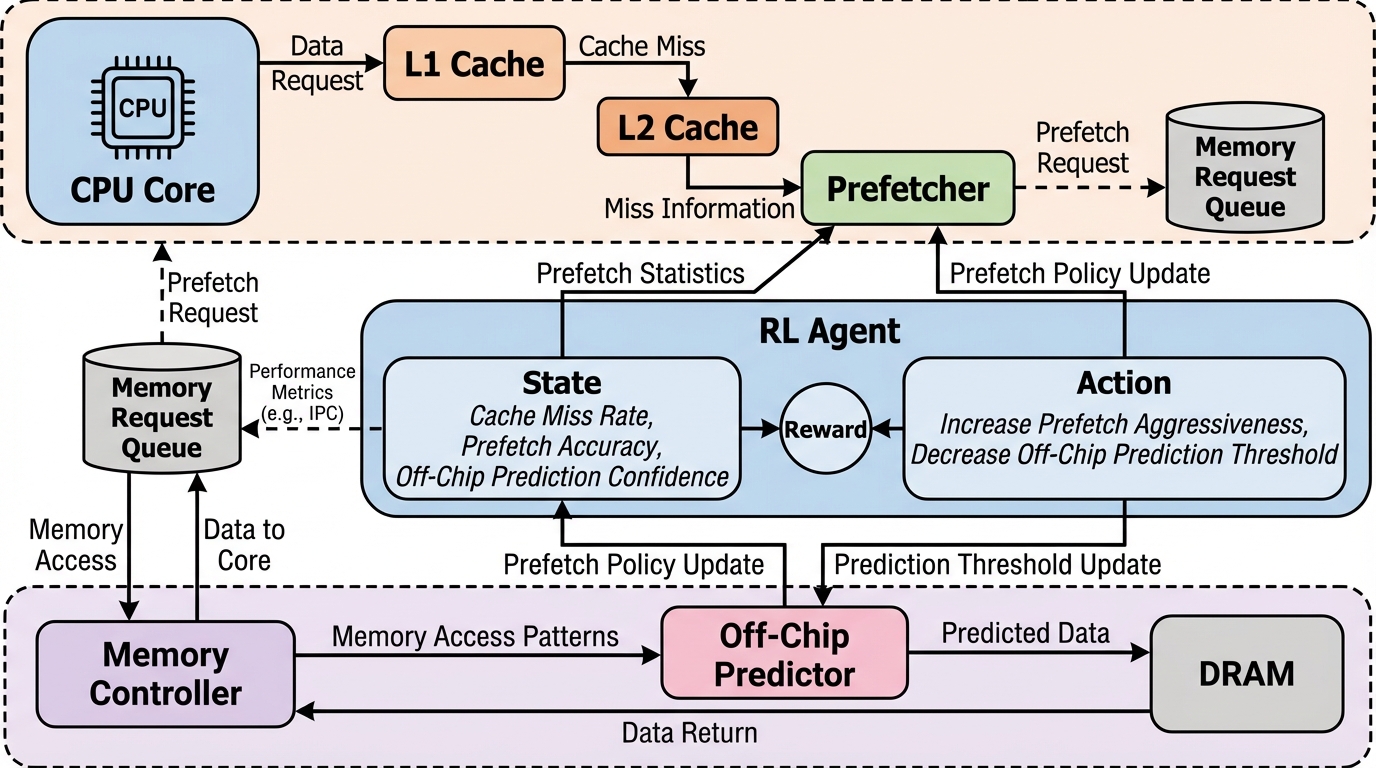
Athena(アテナ)は、プロセッサのメモリ遅延を隠蔽するためのデータプリフェッチとオフチップ予測(OCP)を、オンライン強化学習を用いて自律的に調整する革新的なフレームワークである。 ワークロードのフェーズ変化によるノイズと自身の行動による真の成果を分離する独自の「複合報酬フレームワーク」を導入したことで、学習の安定性を飛躍的に高め、多様なシステム構成において既存手法を最大10.3%上回る性能向上を達成した。 特定のアルゴリズムに依存しない汎用性を持ちながら、1コアあたりわずか3KBという極めて小さなハードウェアコストで実装可能であり、現代の高性能プロセッサにおけるメモリシステムの最適化に新たな道を示している。
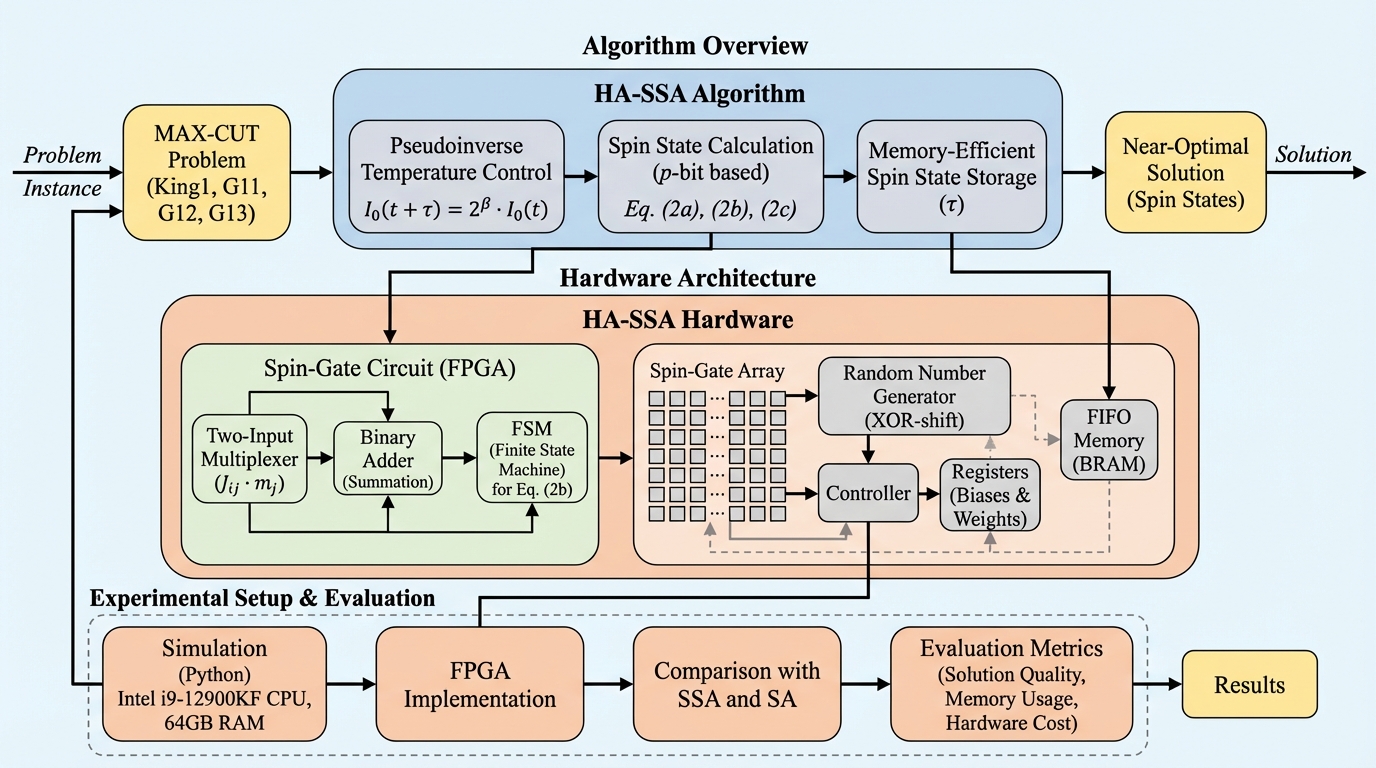
組合せ最適化問題を高速に解く手法として期待される確率的シミュレーテッドアニーリング(SSA)において、ハードウェア実装時の課題であった膨大なメモリ使用量を削減するため、中間状態の保存タイミングを最適化したHA-SSAアルゴリズムが提案されました。
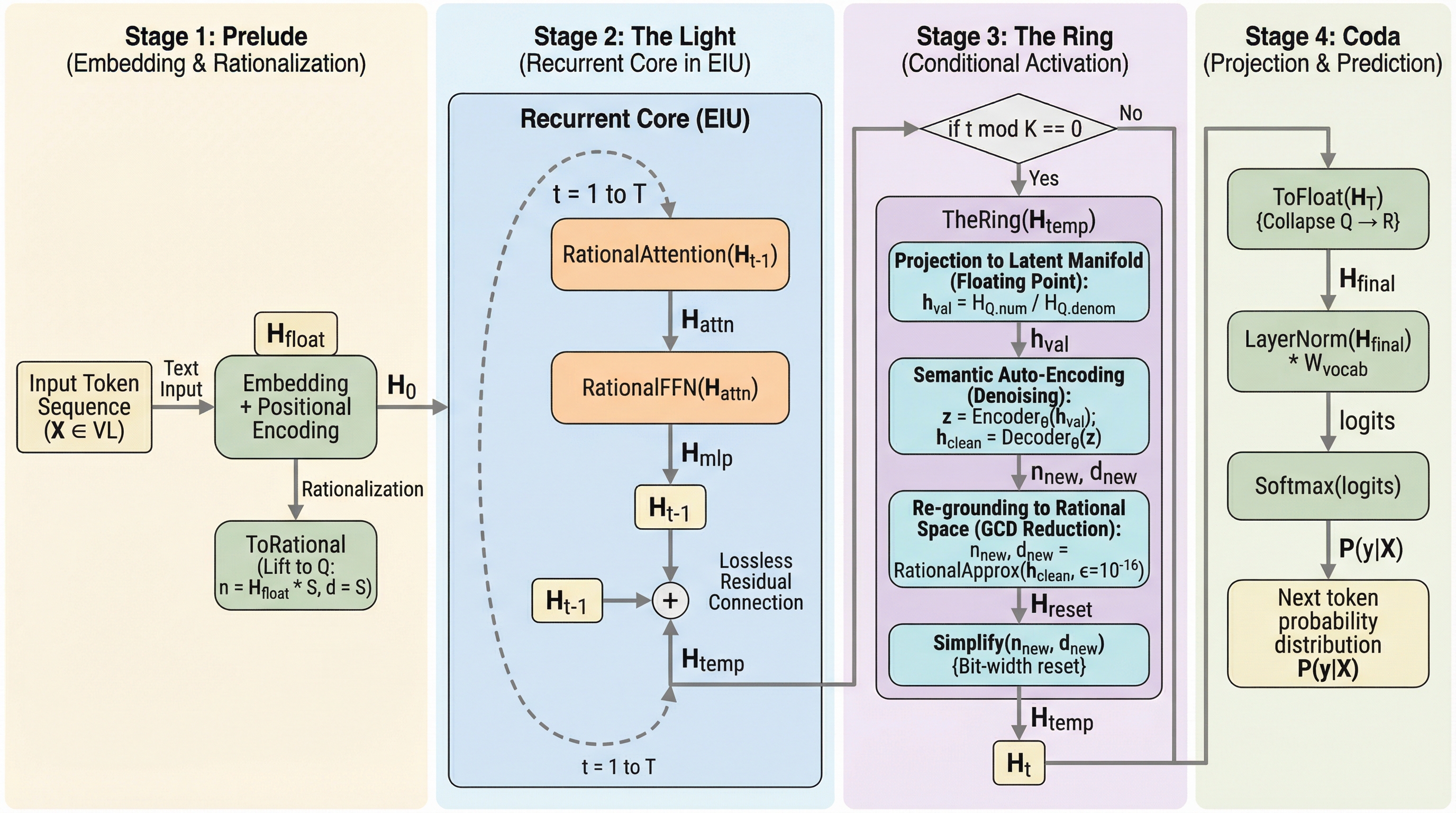
現在の深層学習が依存する浮動小数点演算の近似誤差が、深い推論における「論理的な幻覚」や「セマンティック・ドリフト」の根本原因であると特定し、これを排除するための新しい計算パラダイムを提案した。 有理数演算(Q)を基盤とする「Haloアーキテクチャ」と専用ハードウェア「Exact Inference Unit(EIU)」を導入することで、誤差の蓄積をゼロに抑え、理論上無限の深さを持つ論理推論を可能にする。 600Bパラメータ規模のモデルを用いた検証では、従来の浮動小数点形式がカオス的な系で崩壊する一方で、本提案手法は無限に精度を維持し、大規模モデルほど数値的に不安定になるという「次元の呪い」を克服した。
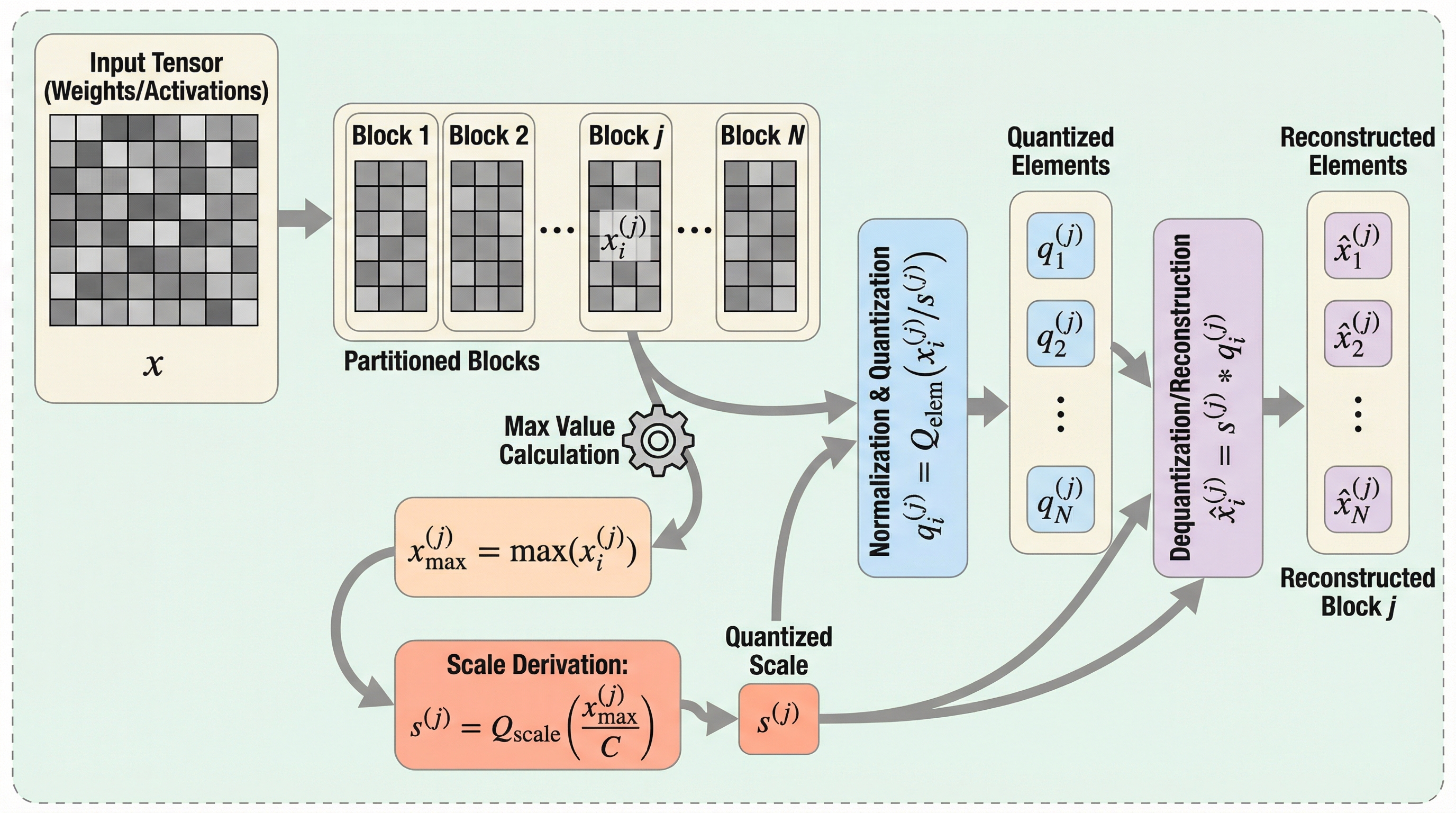
大規模言語モデルの圧縮において、量子化ブロックのサイズを小さくするほど精度が向上するという従来の定説に反し、特定の閾値を下回ると逆に誤差が増大する「パープレキシティ反転」という現象が発見されました。
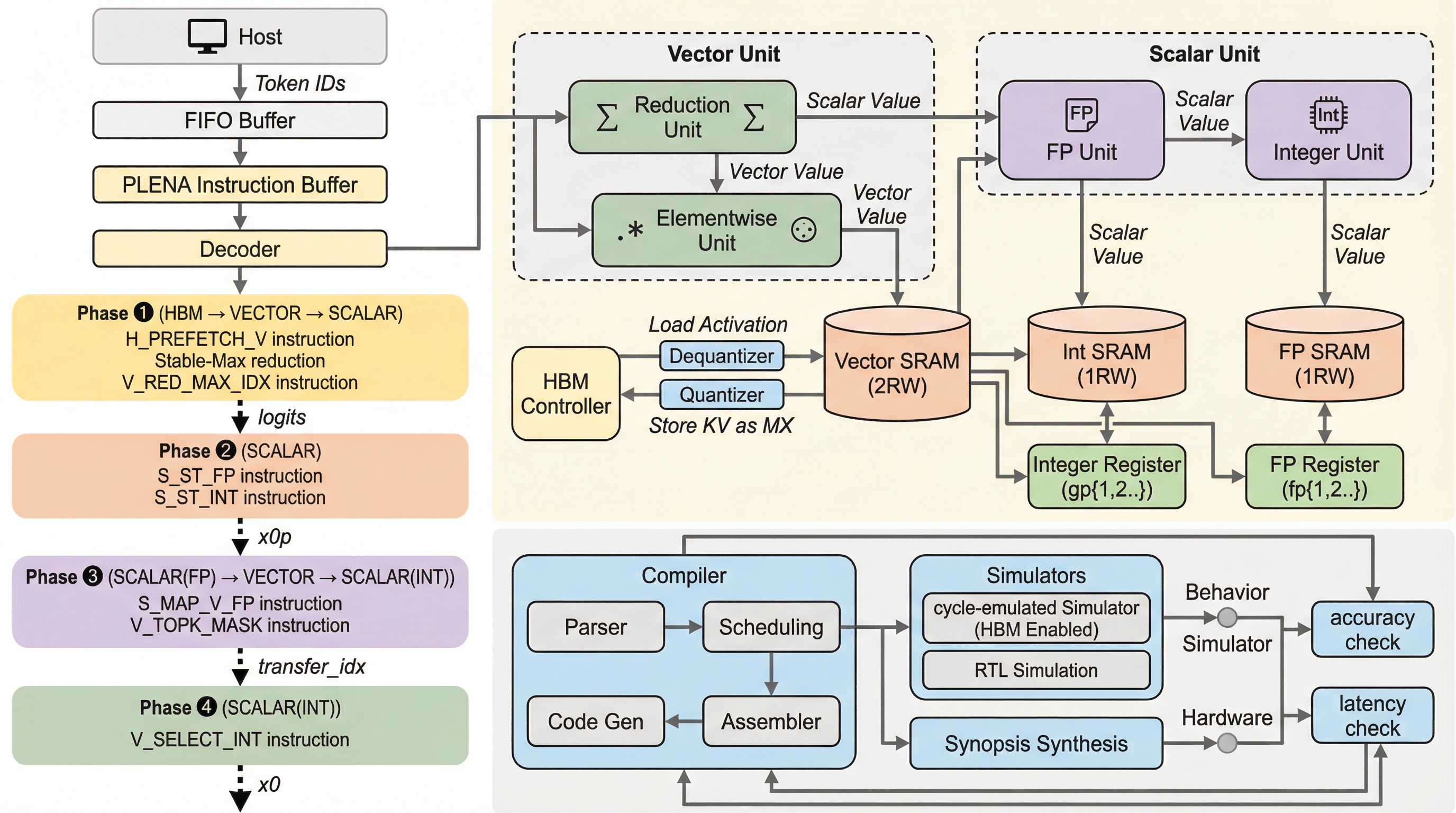
拡散型大規模言語モデル(dLLM)は並列的なトークン生成を可能にするが、語彙全体にわたるロジット処理やトークン選択を行うサンプリング工程が、推論全体の遅延の最大71%を占める深刻なボトルネックとなっている。

大規模言語モデルが抱える事実誤認や推論能力の欠如を解決するため、ニューラルネットワークの知覚能力と記号的・確率的な論理推論を統合した「ニューロシンボリックAI」が注目されていますが、従来のGPUやCPUでは記号推論や確率推論の処理効率が極めて低いという課題がありました。