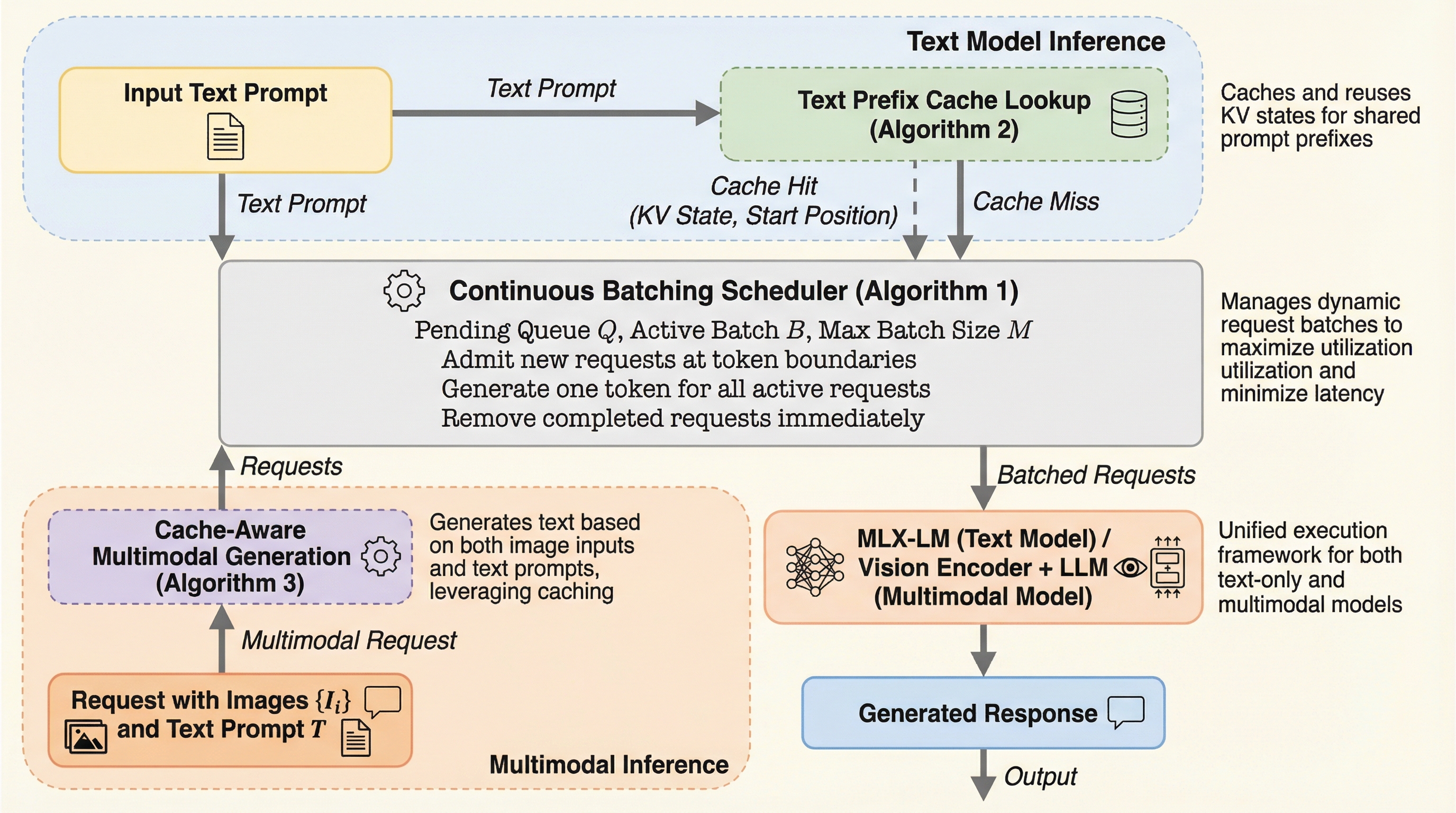
UPipe(Untied Ulysses):注意ヘッド単位の段階実行で長文脈学習の活性化メモリを抑える文脈並列
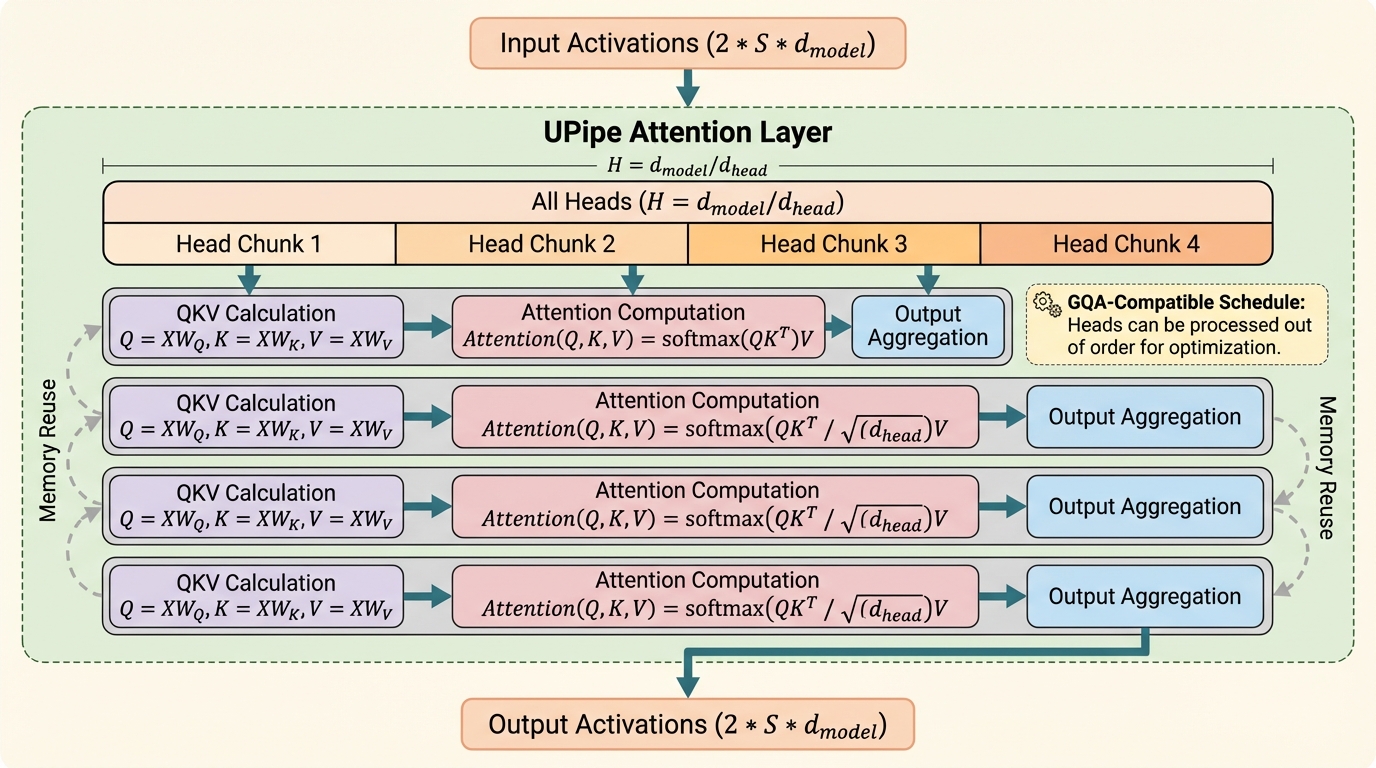
Transformerで超長い系列を学習するとき、文脈並列は系列長方向に計算を分割できますが、自己注意に必要な活性化と通信バッファが積み上がり、非常に長い系列ではメモリが先に限界になります。 / UPipeは注意ヘッドを小さな塊に分け、注意層を複数ステージで順に実行しつつ、各ステージで同じバッファを使い回すことで、自己注意の中間テンソルとオールトゥオール用バッファのピークを下げます。 / 32BのTransformerで注意層の中間テンソルメモリを最大87.5%削減し、学習速度は既存の文脈並列と同程度で、Llama3-8Bを単一の8×H100ノードで最大5Mトークンまで扱えると報告されています。