連合U字型スプリット学習の中間表現を守るKD-UFSL:マイクロアグリゲーションと差分プライバシーの併用
UFSLはデータとラベルをクライアントに残しつつ計算の一部をサーバへオフロードできますが、クライアントが送る中間表現(smashed data)から生データが再構成され得るため、サーバが「正直だが好奇心旺盛」な場合でも漏えい経路になり得ます。
TL;DR(結論)
- UFSLはデータとラベルをクライアントに残しつつ計算の一部をサーバへオフロードできますが、クライアントが送る中間表現(smashed data)から生データが再構成され得るため、サーバが「正直だが好奇心旺盛」な場合でも漏えい経路になり得ます。
- KD-UFSLは、入力データ側にガウス雑音を加える差分プライバシーと、サーバへ送る中間表現を少なくともkクライアントのグループで平均化するk匿名性(マイクロアグリゲーション)を同時に適用し、単独の対策に寄せず二段で中間表現の露出を下げます。
- 4つのベンチマークデータセットで再構成攻撃に対する指標(MSEとSSIM)を評価した結果、実画像と再構成画像の差を大きくし(場合によってMSEを最大50%増、SSIMを最大40%減)、同時にグローバルモデルの有用性も保てる可能性を示しています。
なぜこの問題か
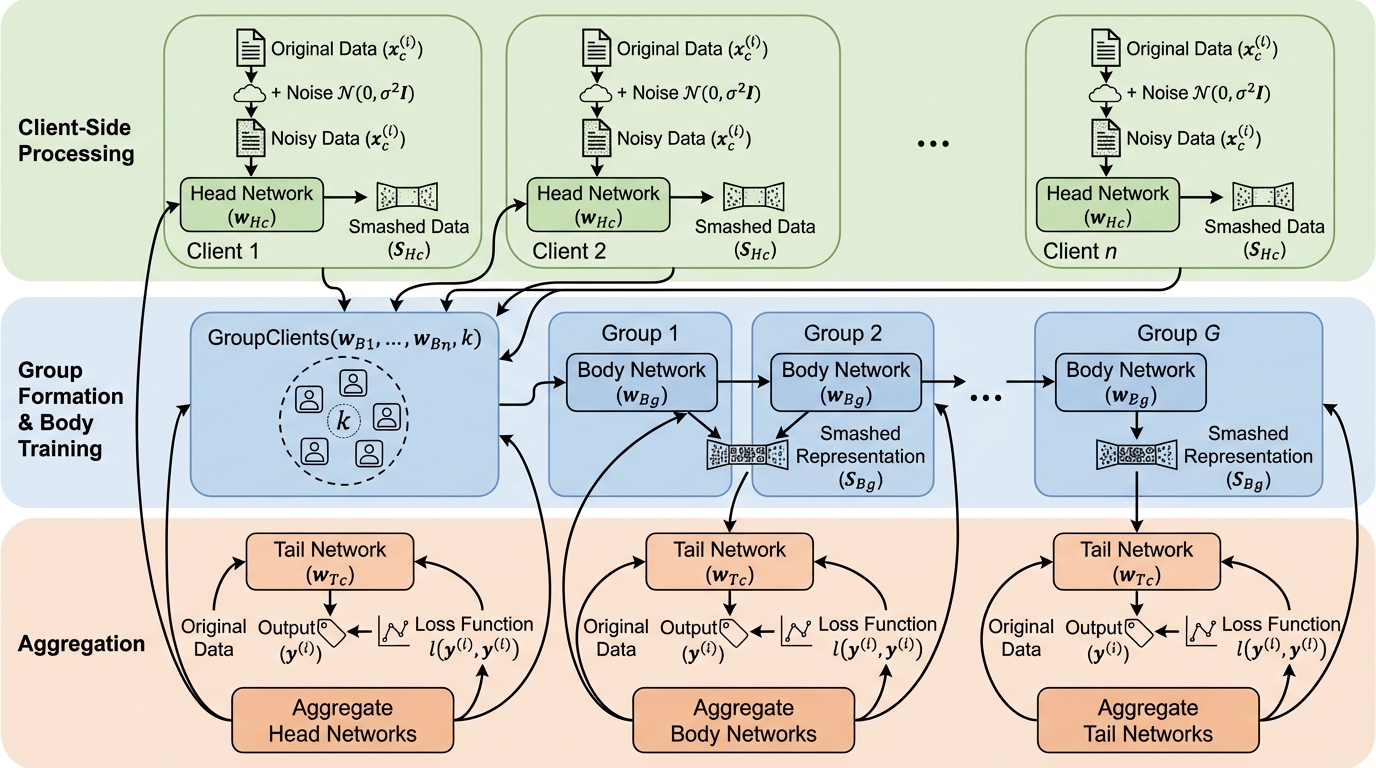
ビッグデータの現場では、巨大かつ異種混在のデータが多数のクライアントに分散して存在し、しかも規制や運用上の理由でデータを一箇所に集めにくい状況が増えています。この前提で機械学習を回すため、データをローカルに保持したまま協調学習する連合学習(FL)が有力になりますが、分散学習はクライアント機器側の計算負担が課題になりやすいです。そこで、モデルを分割し、途中の計算をサーバへ渡すスプリット学習(SL)や、FLとSLを組み合わせてクライアントの負荷を軽くしようとする連合スプリット学習(FSL)が注目されます。 しかし、モデル分割によって「中間表現」をサーバへ送る設計は、新しいプライバシー上の論点を作ります。本文抜粋では、クライアントが送る smashed data(中間特徴)から、サーバ側がクライアントの生データを再構成し得ることが問題として提示されています。特に、二者分割のTFSLではラベル共有が必要になり得て厳格なデータ所有の要件と衝突しますが、UFSLはモデルを三分割してラベルをクライアントに残すことでその点を回避します。…
核心:何を提案したのか
本論文が提案するのは、k匿名性と差分プライバシーを組み合わせた「k-anonymous differentially private UFSL(KD-UFSL)」です。目的は、UFSLにおいてクライアントからサーバへ転送される smashed data を通じて、クライアントの私的データが露出するリスクを下げることです。ポイントは、防御を一箇所に集約せず「データ段」と「特徴段(中間表現段)」の二段で効かせる設計にあります。 具体的には、差分プライバシーは入力の生データ(各ミニバッチ)に対してガウス機構として雑音を加えます。一方で、k匿名性はサーバへ送る smashed data に対して、複数クライアントをグループ化して平均化するマイクロアグリゲーションとして適用します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related