UPipe(Untied Ulysses):注意ヘッド単位の段階実行で長文脈学習の活性化メモリを抑える文脈並列
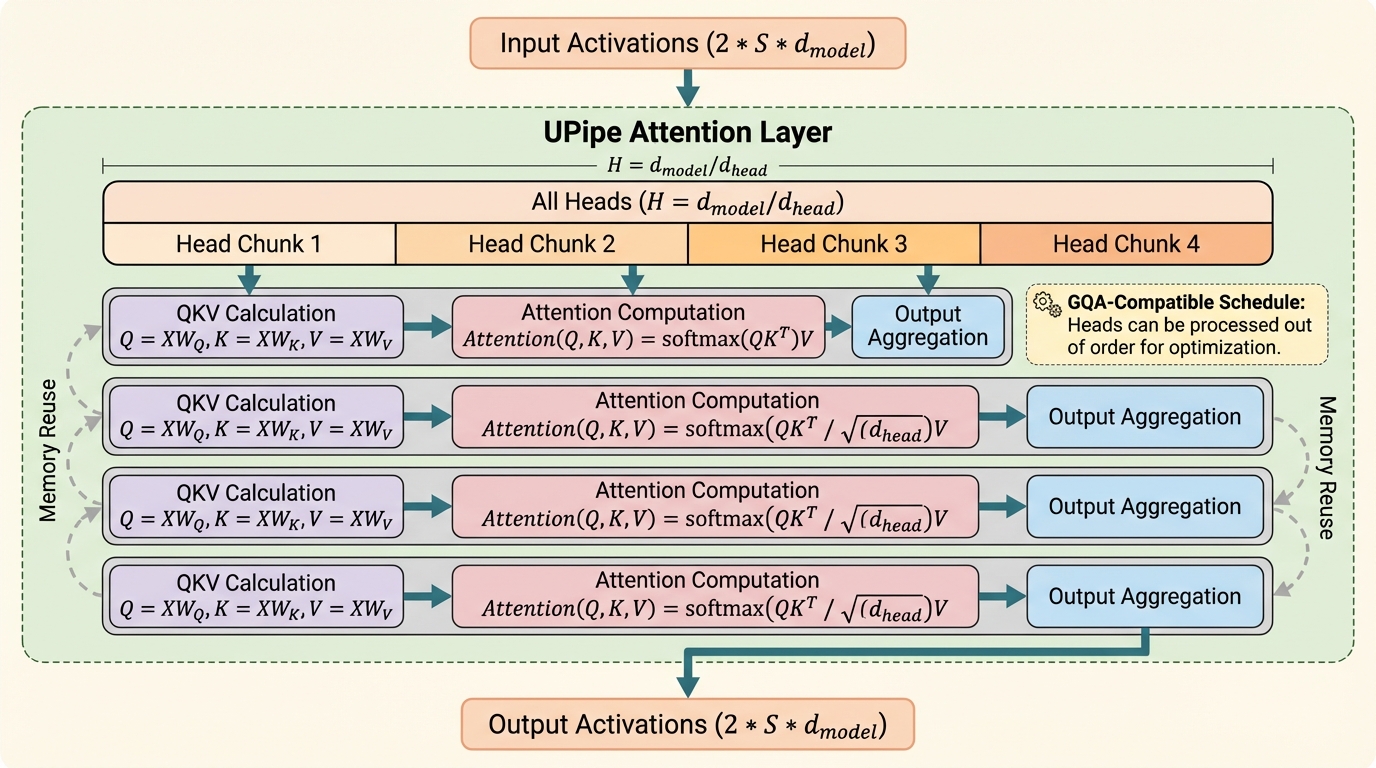
Transformerで超長い系列を学習するとき、文脈並列は系列長方向に計算を分割できますが、自己注意に必要な活性化と通信バッファが積み上がり、非常に長い系列ではメモリが先に限界になります。 / UPipeは注意ヘッドを小さな塊に分け、注意層を複数ステージで順に実行しつつ、各ステージで同じバッファを使い回すことで、自己注意の中間テンソルとオールトゥオール用バッファのピークを下げます。 / 32BのTransformerで注意層の中間テンソルメモリを最大87.5%削減し、学習速度は既存の文脈並列と同程度で、Llama3-8Bを単一の8×H100ノードで最大5Mトークンまで扱えると報告されています。
TL;DR(結論)
- Transformerで超長い系列を学習するとき、文脈並列は系列長方向に計算を分割できますが、自己注意に必要な活性化と通信バッファが積み上がり、非常に長い系列ではメモリが先に限界になります。
- UPipeは注意ヘッドを小さな塊に分け、注意層を複数ステージで順に実行しつつ、各ステージで同じバッファを使い回すことで、自己注意の中間テンソルとオールトゥオール用バッファのピークを下げます。
- 32BのTransformerで注意層の中間テンソルメモリを最大87.5%削減し、学習速度は既存の文脈並列と同程度で、Llama3-8Bを単一の8×H100ノードで最大5Mトークンまで扱えると報告されています。
なぜこの問題か
長い系列をTransformerで扱う需要は、コード生成、長文書の理解、音声処理、動画生成などの用途により拡大していますが、学習時にはハードウェア制約が先に表面化します。特に自己注意は、系列が長くなるほど保持すべき活性化が大きくなり、一定の長さを超えると「活性化を置く場所」がボトルネックになります。本文抜粋では、文脈並列(別名として系列並列)により系列長方向へ分割しても、デバイスあたりの活性化メモリが系列長に対して線形に増えるため、非常に長い系列(>2M)では学習容量が制約されると説明されています。 この文脈並列の代表例として、Ring AttentionやDeepSpeed Ulyssesが挙げられていますが、これらは文脈次元へスケールさせる枠組みとして強力である一方、メモリ効率そのものを主目的に設計していない、という問題意識が示されています。さらに長文脈を狙う発展的な手段として、Fully Pipelined Distributed Transformer(FPDT)や活性化のオフロードにも触れられていますが、こちらはスループット低下を伴い得る点が論点になります。…
核心:何を提案したのか
本論文は、UPipeという文脈並列手法を提案しています。要点は、注意層を「全ヘッドを一度に処理する」のではなく、注意ヘッドを細粒度にチャンク化し、複数ステージに分けて順次処理する点にあります。これにより、自己注意で支配的になりやすい中間テンソル(Q、K、Vや、それに付随するオールトゥオール通信のバッファ)を、全ヘッド分まとめて抱える必要がなくなり、ピーク活性化メモリを下げられます。 Abstractでは、32BのTransformerにおいて注意層の中間テンソルメモリを最大87.5%削減しつつ、学習速度は従来の文脈並列と同程度であると述べられています。また、Llama3-8Bの学習で単一の8×H100ノード上において最大5Mトークンの文脈長をサポートでき、従来手法より25%を超えて最大文脈長を伸ばしたと報告されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related