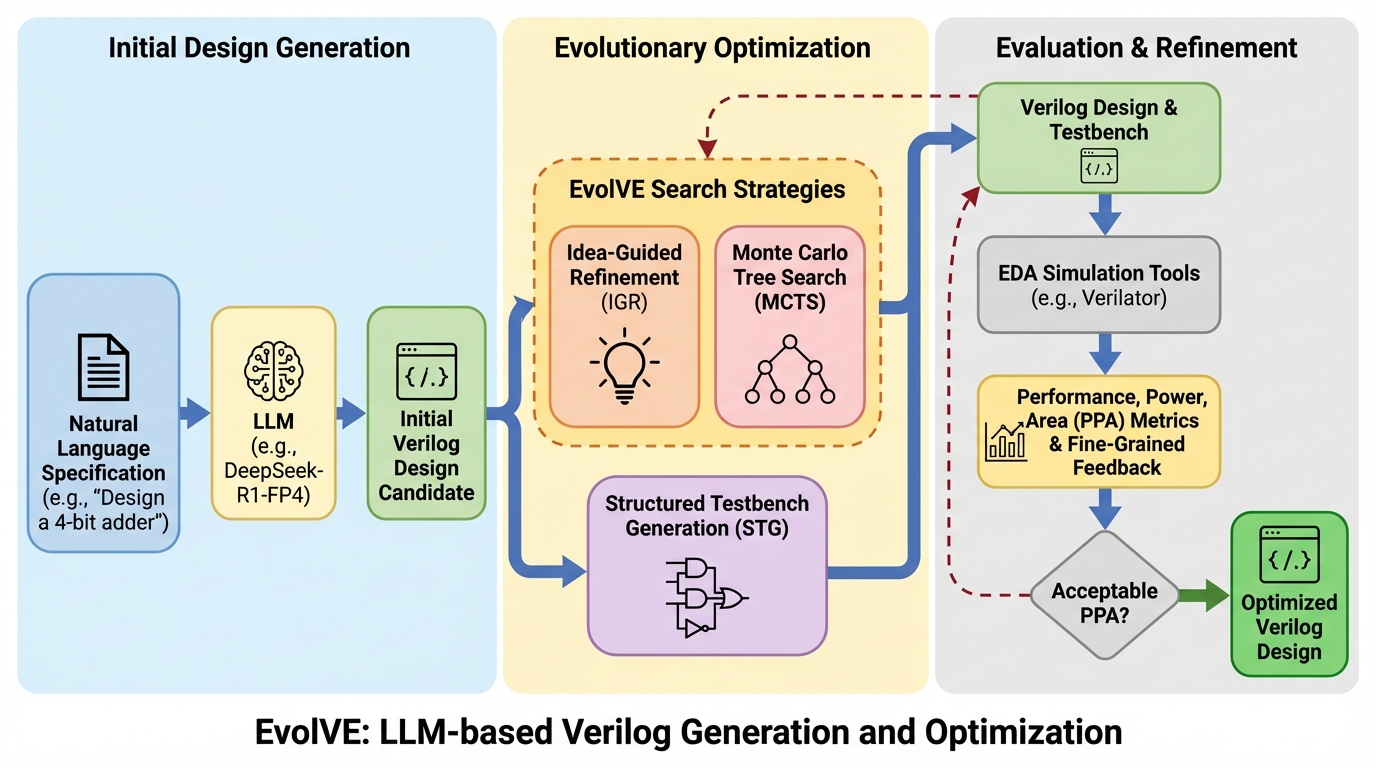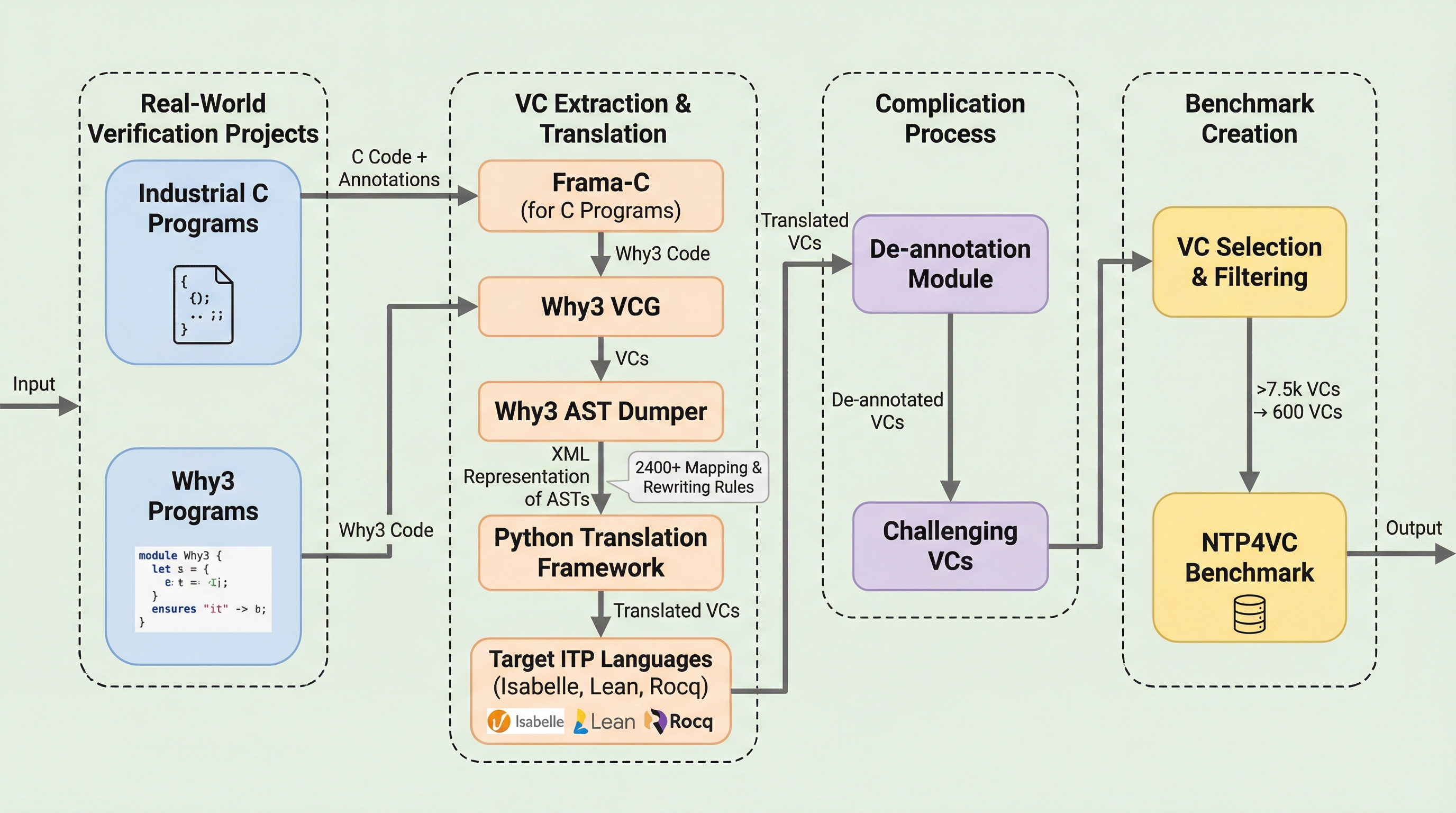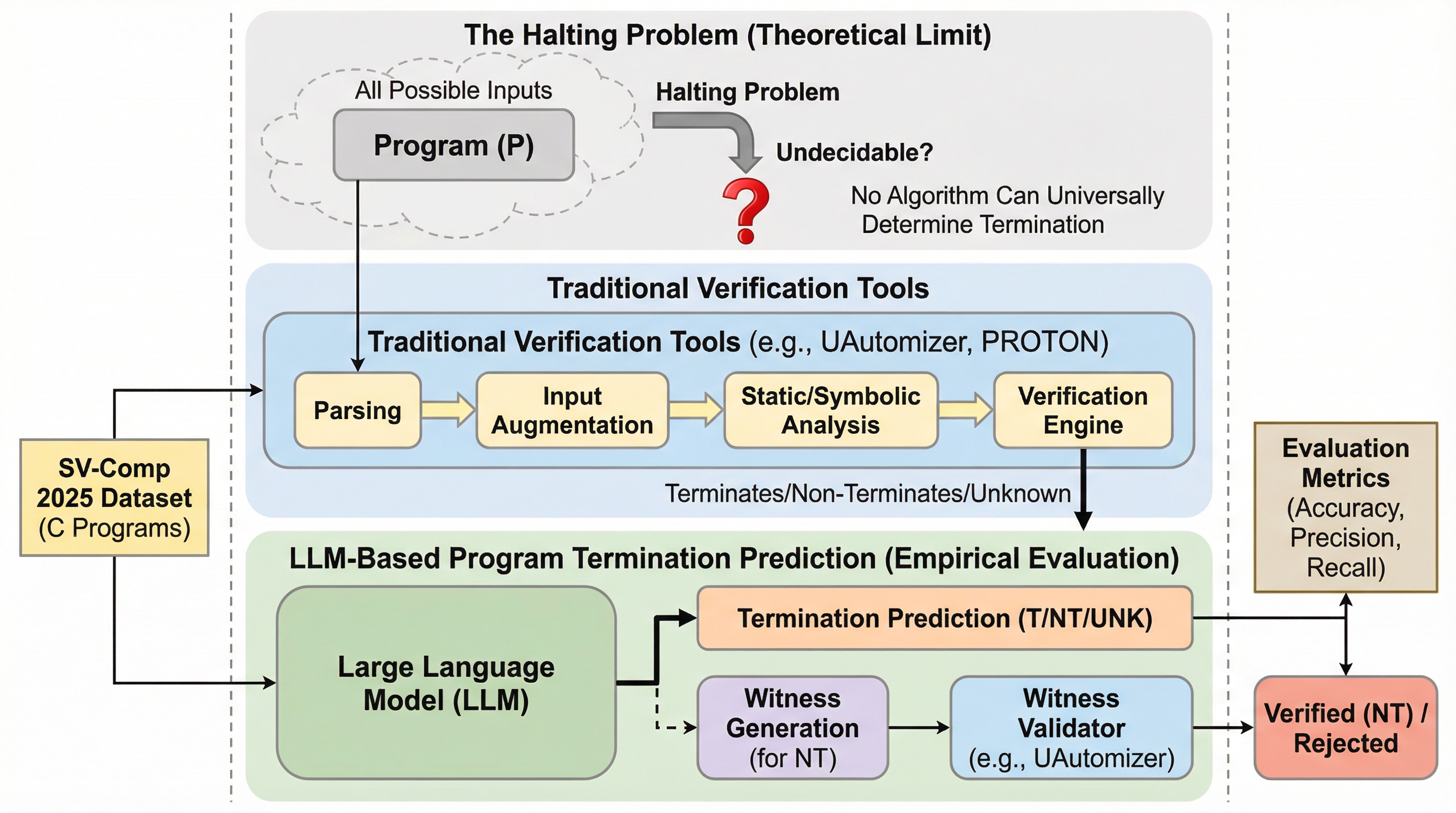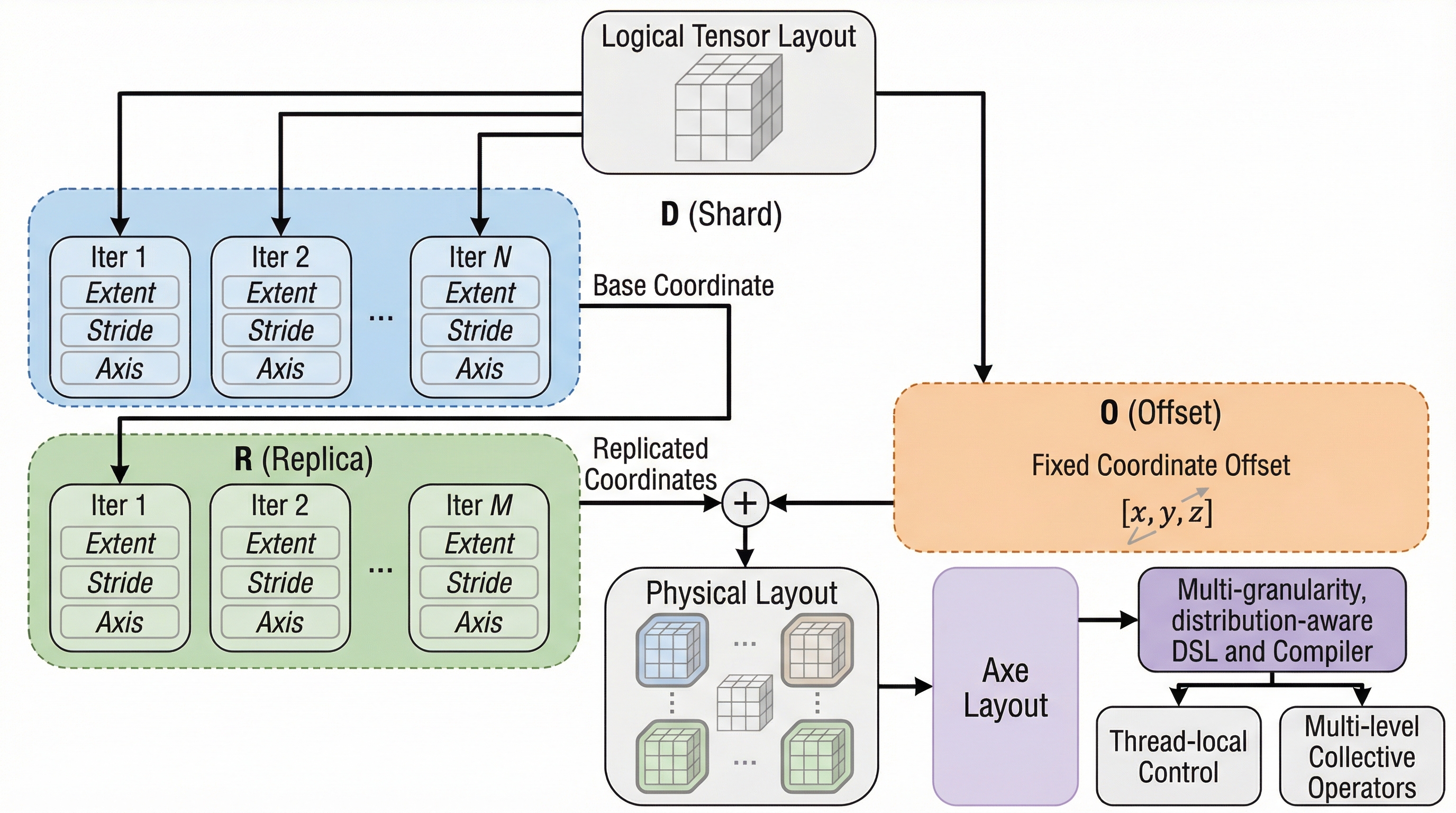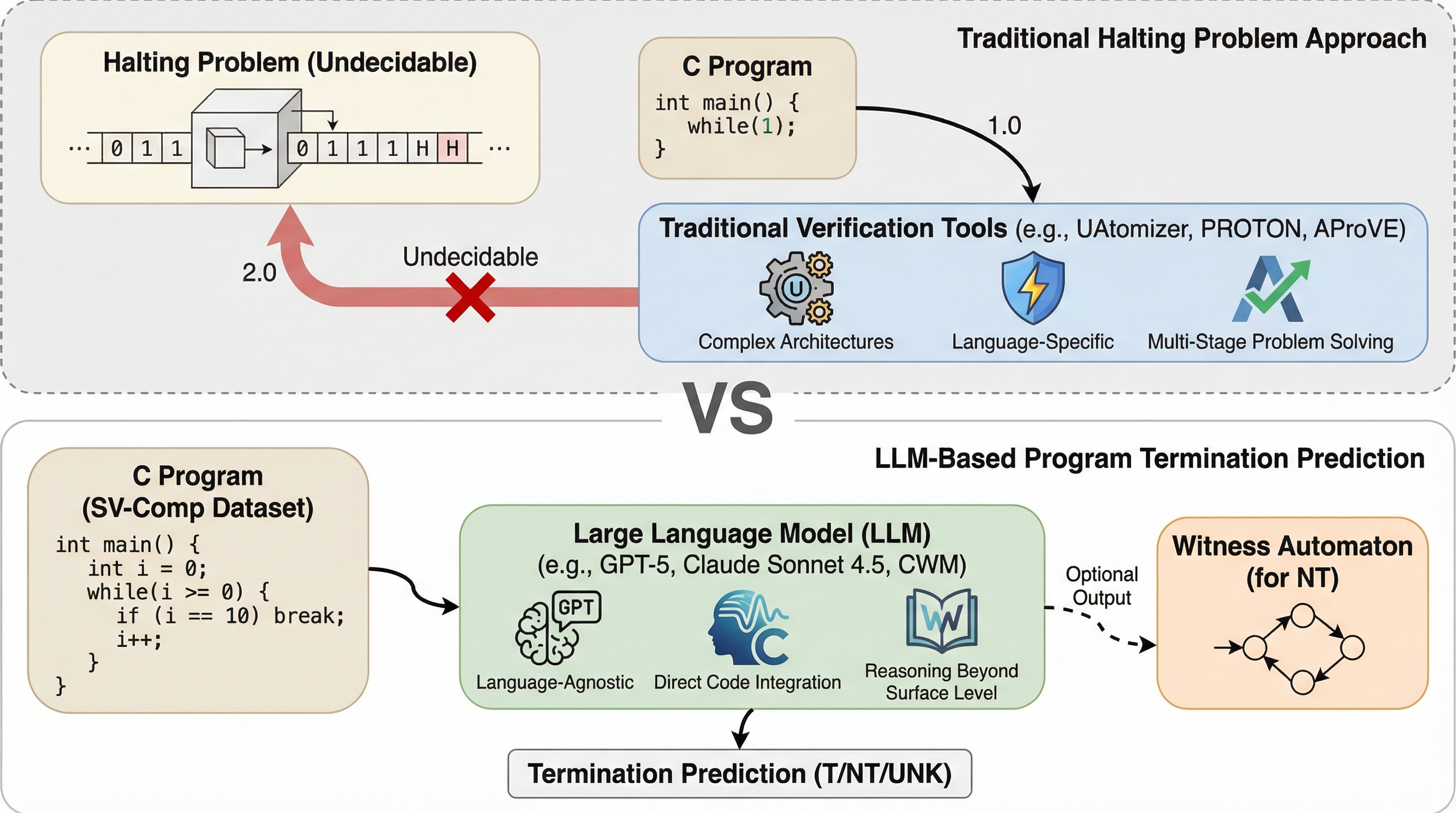
LLM対停止性問題:プログラム停止予測の再考
大規模言語モデル(LLM)は、計算機科学の難問である「停止問題」の予測において、専門的な検証ツールに匹敵する極めて高い性能を示した。特にGPT-5やClaude Sonnet-4.5は、国際的なソフトウェア検証コンペティション(SV-Comp 2025)のトップクラスのツールに次ぐスコアを記録し、その推論能力の高さが証明された。 一方で、プログラムが終了しないことの数学的な証明となる「証拠(ウィットネス)」の生成には依然として課題があり、コードの長さや複雑さが増すにつれて予測精度が低下する傾向も確認された。 信頼性を高めるために導入された「テストタイム・スケーリング(TTS)」による合意形成アルゴリズムは、モデルの不確実性を適切に管理し、誤判定によるペナルティを回避してスコアを劇的に向上させる有効な手段であることが明らかになった。