LLM対停止問題:プログラム停止予測の再考
本研究は、計算機科学の根幹的な未解決問題である「停止問題」に対し、GPT-5やClaude Sonnet-4.5といった最新の大規模言語モデル(LLM)が、国際ソフトウェア検証コンペティション(SV-Comp)2025の基準で専門ツールに匹敵する予測能力を持つことを実証した。
TL;DR(結論)
本研究は、計算機科学の根幹的な未解決問題である「停止問題」に対し、GPT-5やClaude Sonnet-4.5といった最新の大規模言語モデル(LLM)が、国際ソフトウェア検証コンペティション(SV-Comp)2025の基準で専門ツールに匹敵する予測能力を持つことを実証した。 テスト時スケーリング(TTS)とコンセンサス投票を導入した結果、GPT-5は最高峰の検証ツールであるPROTONに次ぐ世界第2位相当のスコアを記録し、汎用的な推論モデルが特定のプログラミング言語や抽象化に依存しない高度なプログラム解析を実現できる可能性を示した。 一方で、プログラムが停止しないことを論理的に証明する「ウィットネス・オートマトン」の生成成功率は依然として低く、さらにコードの長大化に伴って予測精度が顕著に低下するという課題も明らかになり、厳密な形式検証におけるLLMの現在の限界と今後の研究の方向性が浮き彫りになった。
なぜこの問題か
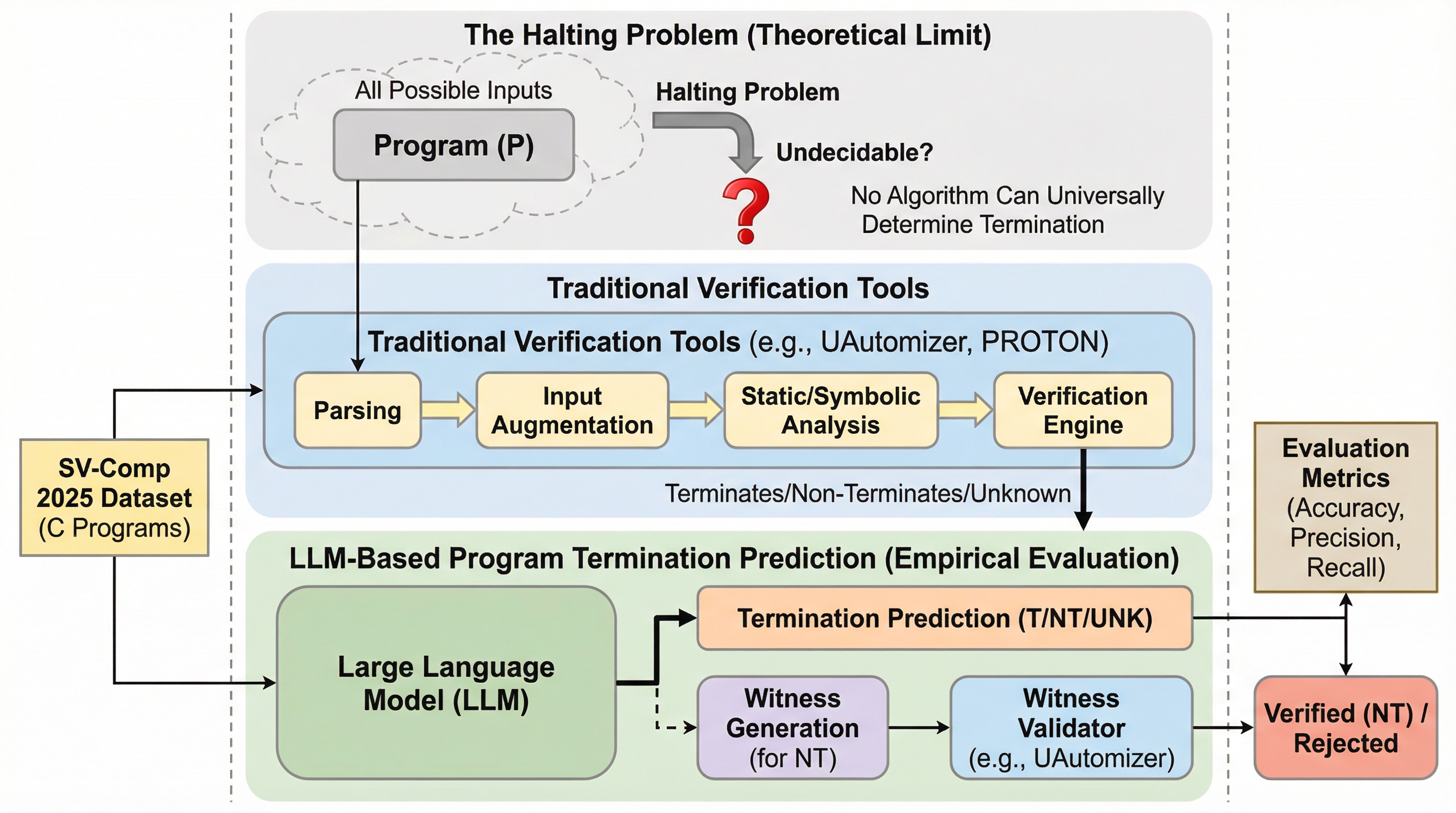
プログラムが有限の時間内に終了するか、あるいは無限ループに陥るかを判定する「停止問題」は、計算機科学における最も基礎的かつ困難な課題の一つとして位置づけられている。1936年にアラン・チューリングが示した通り、あらゆるプログラムと入力に対して停止性を普遍的に判定できるアルゴリズムは存在しないという「決定不能性」が数学的に証明されている。このため、従来の自動検証ツールは停止性を近似的に判定するにとどまっており、複雑なプログラムの証明や反証において、しばしば「不明」として解析に失敗することが少なくない。ソフトウェアの信頼性と安全性を確保する上で、プログラムの停止性を保証することは極めて重要であり、非停止性はリソースの無制限な消費やシステムの応答停止、さらには重大なシステム障害を引き起こす致命的な欠陥となる。既存の検証ツールであるUAutomizerやPROTONなどは、プログラムの文に対するオートマトンやシンボリック実行を利用して解析を行うが、これらは特定の問題に特化したアーキテクチャや抽象化に依存しており、特定のプログラミング言語に縛られることが多いのが現状である。…
核心:何を提案したのか
本研究の核心は、最新の大規模言語モデル(LLM)がプログラムの停止性をどの程度正確に予測できるかを、国際ソフトウェア検証コンペティション(SV-Comp)2025の「停止性(Termination)」カテゴリを用いて包括的に評価した点にある。具体的には、GPT-5、Claude Sonnet-4.5、Code World Model (CWM)、Qwen3-32Bといった最新の推論型モデルに加え、推論能力を持たないベースラインとしてGPT-4oを比較対象に含めた。評価には、ビット精度演算や複雑な制御フロー、動的なヒープメモリ操作などを含む2,328個の多様なC言語プログラムが使用されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related