Axe:機械学習コンパイラのためのシンプルで統一されたレイアウト抽象化
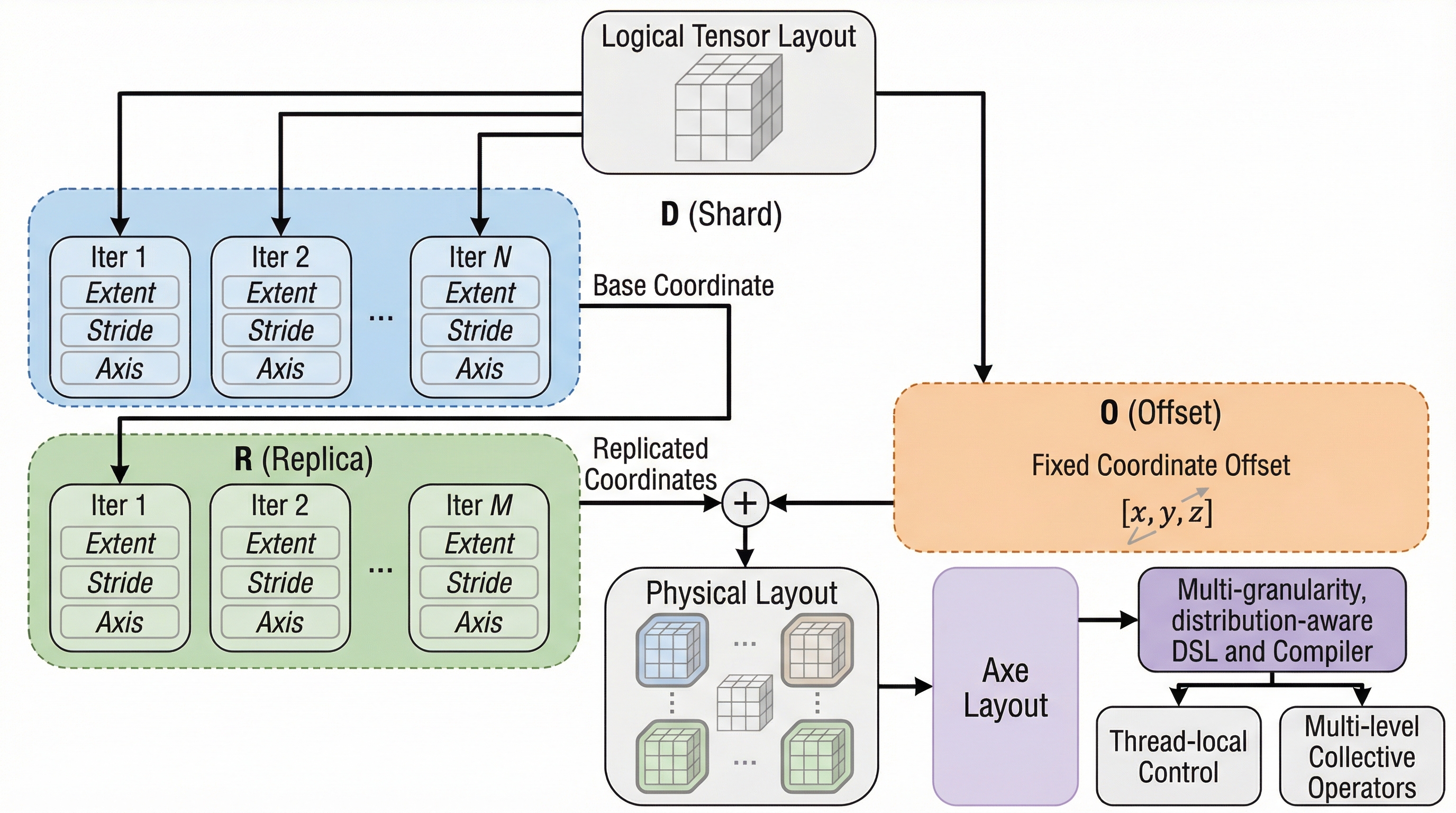
Axeは、論理的なテンソル座標をデバイス、メモリ、スレッドなどのハードウェア軸にマッピングする、ハードウェアを意識した新しい抽象化手法である。 この手法は、デバイス間のデータ分散(シャーディング、複製)とデバイス内のメモリレイアウト(タイリング、オフセット)を単一の形式で統一し、一貫した記述を可能にする。
TL;DR(結論)
Axeは、論理的なテンソル座標をデバイス、メモリ、スレッドなどのハードウェア軸にマッピングする、ハードウェアを意識した新しい抽象化手法である。 この手法は、デバイス間のデータ分散(シャーディング、複製)とデバイス内のメモリレイアウト(タイリング、オフセット)を単一の形式で統一し、一貫した記述を可能にする。 Axeを基盤としたDSLとコンパイラにより、手動で最適化されたカーネルに匹敵する性能を、GPUやAIアクセラレータなどの多様な環境において、より低い開発コストで実現できる。
なぜこの問題か
現代の深層学習ワークロード、特に大規模言語モデル(LLM)のスケールアップに伴い、実行時の最適化はシステム上の中心的な課題となっている。モデルやデータ、推論フリートが拡大する中で、トレーニングや推論のパフォーマンスを最大限に引き出すためには、ソフトウェアとハードウェアのスタックにおける複数の層で複雑な課題を解決しなければならない。第一の課題は分散実行である。大規模なモデルは複数のデバイスやマシンにまたがって実行される必要があり、深層学習フレームワークやコンパイラは、デバイスメッシュ間でのデータのシャーディングや複製の選択を明示的に行い、通信と計算のオーバーラップを最適化しなければならない。 第二の課題は、デバイスレベルにおけるメモリとスレッドの階層構造である。GPUやAIアクセラレータは、グリッド、ブロック、ワープ、レーンといった入れ子状の並列構造と、複雑なメモリ階層を持っている。カーネルライブラリは、これらのメモリ範囲にわたってデータがどのようにタイリングされるかを慎重に調整する必要がある。…
核心:何を提案したのか
本論文では、分散デバイス階層と異種ハードウェア設定の両方において、計算とデータのマッピングを統一するシンプルかつ効果的な抽象化である「Axeレイアウト」を提案している。Axeレイアウトの最大の特徴は、「名前付き軸(named axes)」を導入したことである。これにより、スレッド軸、アクセラレータ内のメモリバンク、分散ワーカーといったハードウェア構成要素を明示的に表現することが可能になる。この名前付き軸に基づき、Axeレイアウトは論理的なタイルの座標を、GPUデバイス、スレッド、メモリにわたる多軸の物理空間にどのようにマッピングするかを定義する。 Axeは、デバイス間の分散(シャーディング、複製)とデバイス上のメモリレイアウト(タイリング、オフセット)を、一つの形式的な表現の中に統合する。これにより、デバイスメッシュから個別のスレッドに至るまで、集合的なプリミティブを一貫して表現できるようになる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related