LLM対停止性問題:プログラム停止予測の再考
大規模言語モデル(LLM)は、計算機科学の難問である「停止問題」の予測において、専門的な検証ツールに匹敵する極めて高い性能を示した。特にGPT-5やClaude Sonnet-4.5は、国際的なソフトウェア検証コンペティション(SV-Comp 2025)のトップクラスのツールに次ぐスコアを記録し、その推論能力の高さが証明された。 一方で、プログラムが終了しないことの数学的な証明となる「証拠(ウィットネス)」の生成には依然として課題があり、コードの長さや複雑さが増すにつれて予測精度が低下する傾向も確認された。 信頼性を高めるために導入された「テストタイム・スケーリング(TTS)」による合意形成アルゴリズムは、モデルの不確実性を適切に管理し、誤判定によるペナルティを回避してスコアを劇的に向上させる有効な手段であることが明らかになった。
TL;DR(結論)
大規模言語モデル(LLM)は、計算機科学の難問である「停止問題」の予測において、専門的な検証ツールに匹敵する極めて高い性能を示した。特にGPT-5やClaude Sonnet-4.5は、国際的なソフトウェア検証コンペティション(SV-Comp 2025)のトップクラスのツールに次ぐスコアを記録し、その推論能力の高さが証明された。 一方で、プログラムが終了しないことの数学的な証明となる「証拠(ウィットネス)」の生成には依然として課題があり、コードの長さや複雑さが増すにつれて予測精度が低下する傾向も確認された。 信頼性を高めるために導入された「テストタイム・スケーリング(TTS)」による合意形成アルゴリズムは、モデルの不確実性を適切に管理し、誤判定によるペナルティを回避してスコアを劇的に向上させる有効な手段であることが明らかになった。
なぜこの問題か
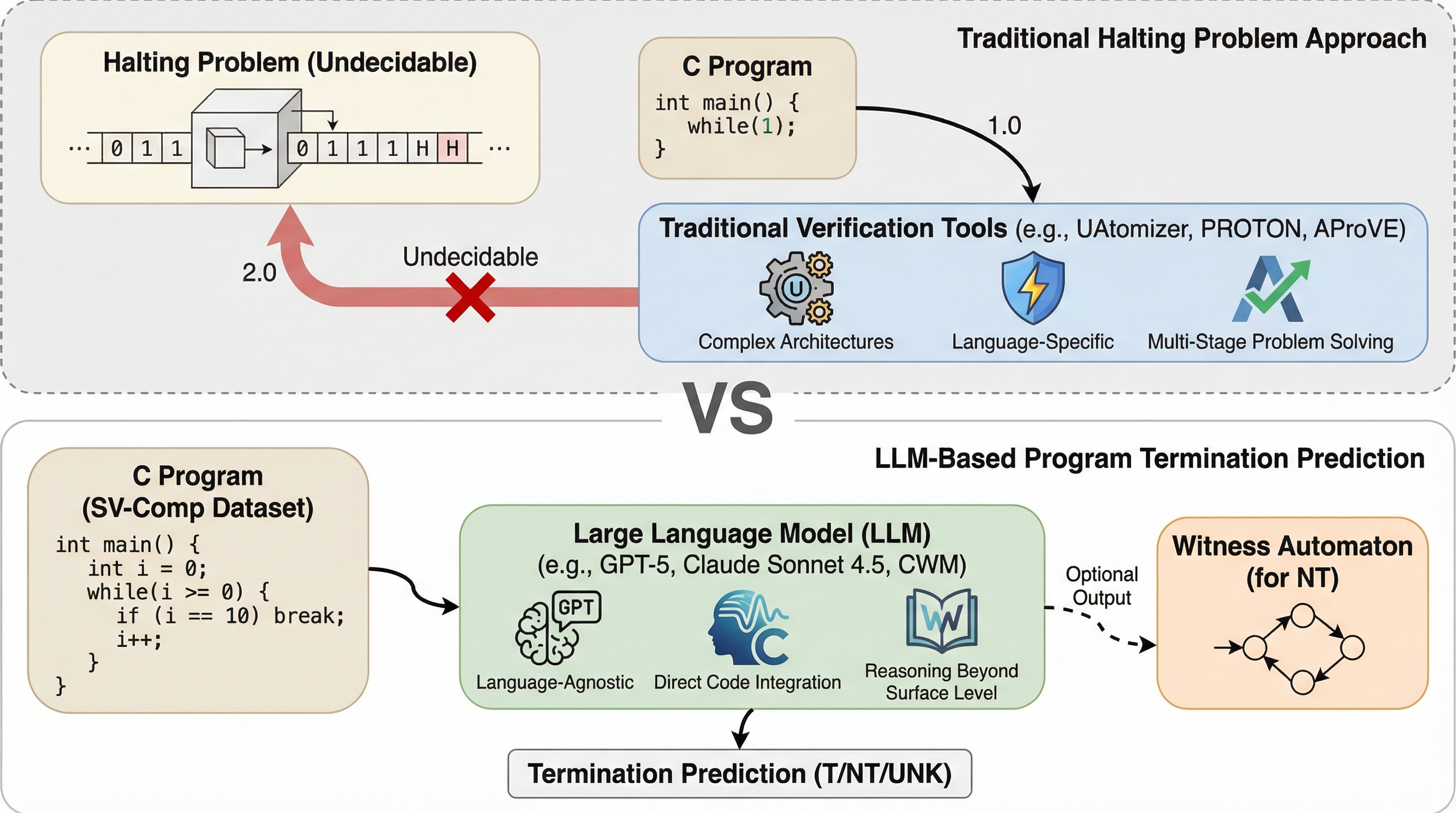
プログラムが与えられた入力に対して最終的に停止するか、あるいは無限ループに陥るかを判定する「停止問題」は、計算機科学における最も基本的かつ重要な課題の一つである。アラン・チューリングによる基礎的な研究によって、この問題は「決定不能」であることが証明されており、あらゆるプログラムと入力に対して停止性を普遍的に判定できるアルゴリズムは存在しない。しかし、実世界のソフトウェア開発において、プログラムの停止性を保証することは、システムの信頼性と安全性を確保するために不可欠である。プログラムが停止しない場合、リソースの無制限な消費やシステムの応答停止、深刻な障害を引き起こす可能性があるため、この問題の解決は極めて重要である。 従来の自動検証ツールは、この決定不能な問題に対して近似的なアプローチをとってきた。これらのツールは、特定のプログラミング言語や問題に特化したアーキテクチャ、抽象化手法に依存しており、多くの場合、複雑な多段階の処理を必要とする。例えば、オートマトンを用いた手法やシンボリック実行を利用した手法などが提案されているが、これらは言語依存性が高く、汎用性に欠ける側面がある。…
核心:何を提案したのか
本研究では、LLMがプログラムの停止性をどの程度正確に予測できるかを評価するため、国際的なソフトウェア検証コンペティションである「SV-Comp 2025」の停止性(Termination)カテゴリのデータセットを用いた大規模な評価を実施した。評価の対象となったモデルには、推論能力を持つ最新のモデルであるGPT-5、Claude Sonnet-4.5、Code World Model (CWM)、Qwen3-32Bが含まれる。また、推論機能を持たないベースラインとしてGPT-4oも比較対象に加えられた。これにより、モデルの規模や推論特化型の設計が停止問題の解決にどのように寄与するかを多角的に分析した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related