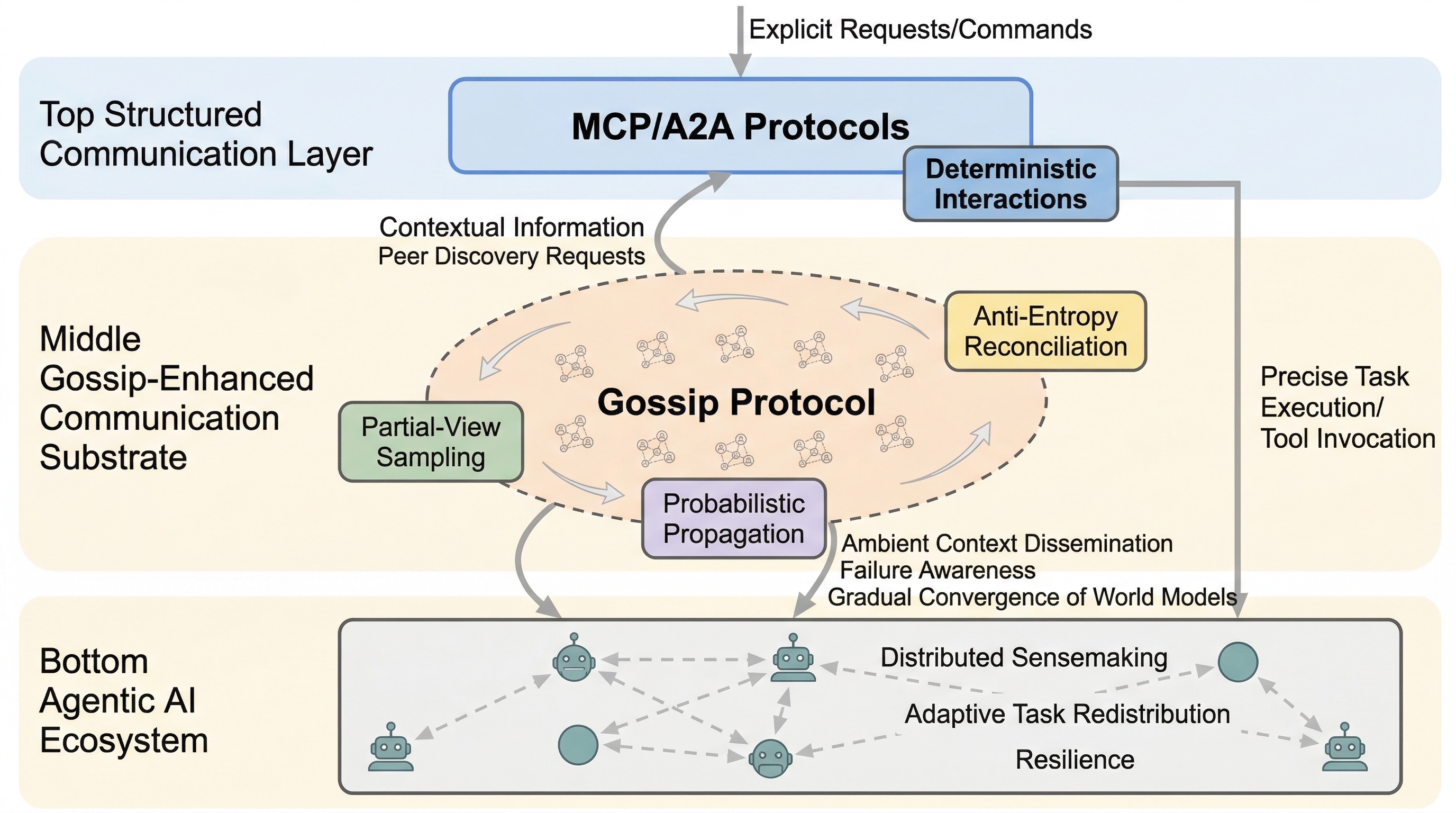
Gossip を Agent 通信の土台にする発想は成り立つか:GEACL が描く分散協調の設計図
2512.03285 は、MCP や A2A のような構造化プロトコルだけでは大規模エージェント集団の分散協調を支えきれないとして、その下に gossip ベースの通信基盤 GEACL を置く設計論文です。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
2512.03285 は、MCP や A2A のような構造化プロトコルだけでは大規模エージェント集団の分散協調を支えきれないとして、その下に gossip ベースの通信基盤 GEACL を置く設計論文です。
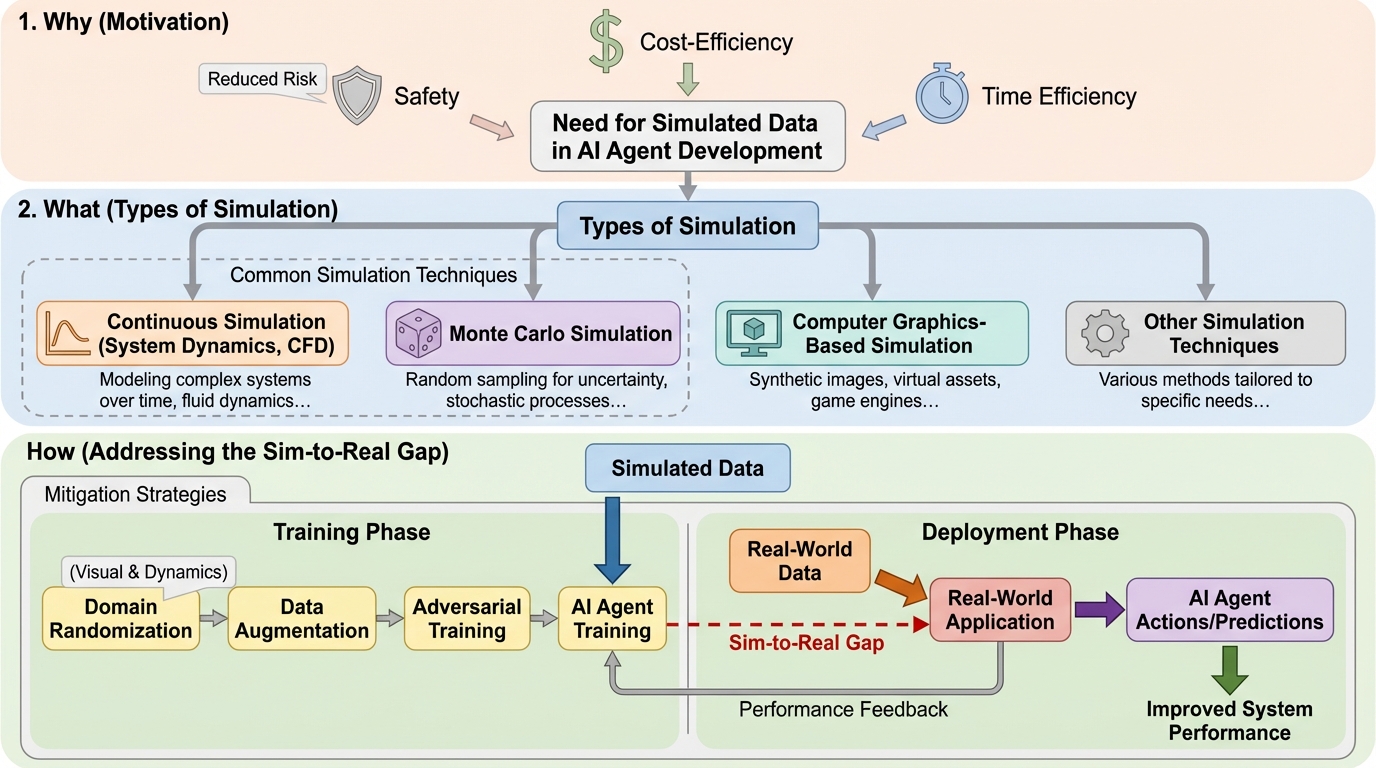
現代のサブシンボリックAIは大量かつ高品質な学習データに支えられますが、実世界データは取得コスト、プライバシー、安全性、組織内サイロなどの制約で集めにくく、さらに欠損や重複やノイズが使い勝手を下げるため、合成データ生成の需要が高まります。
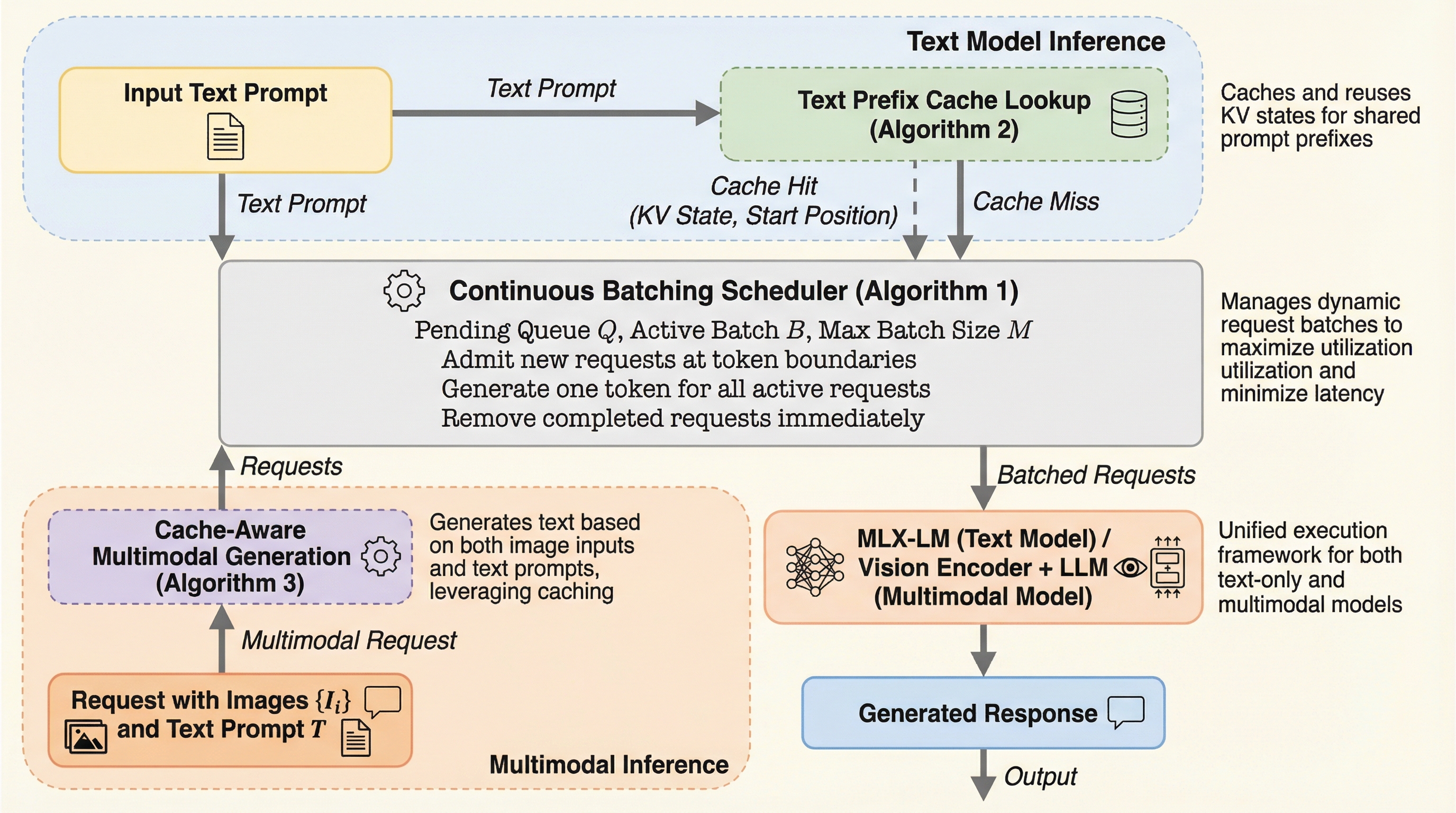
vllm-mlxは、Apple Siliconのユニファイドメモリ構造を最大限に活用するためにMLX上でネイティブに構築された、LLMおよびマルチモーダルLLM(MLLM)のための高効率な推論フレームワークである。継続的バッチ処理の導入により、従来のllama.
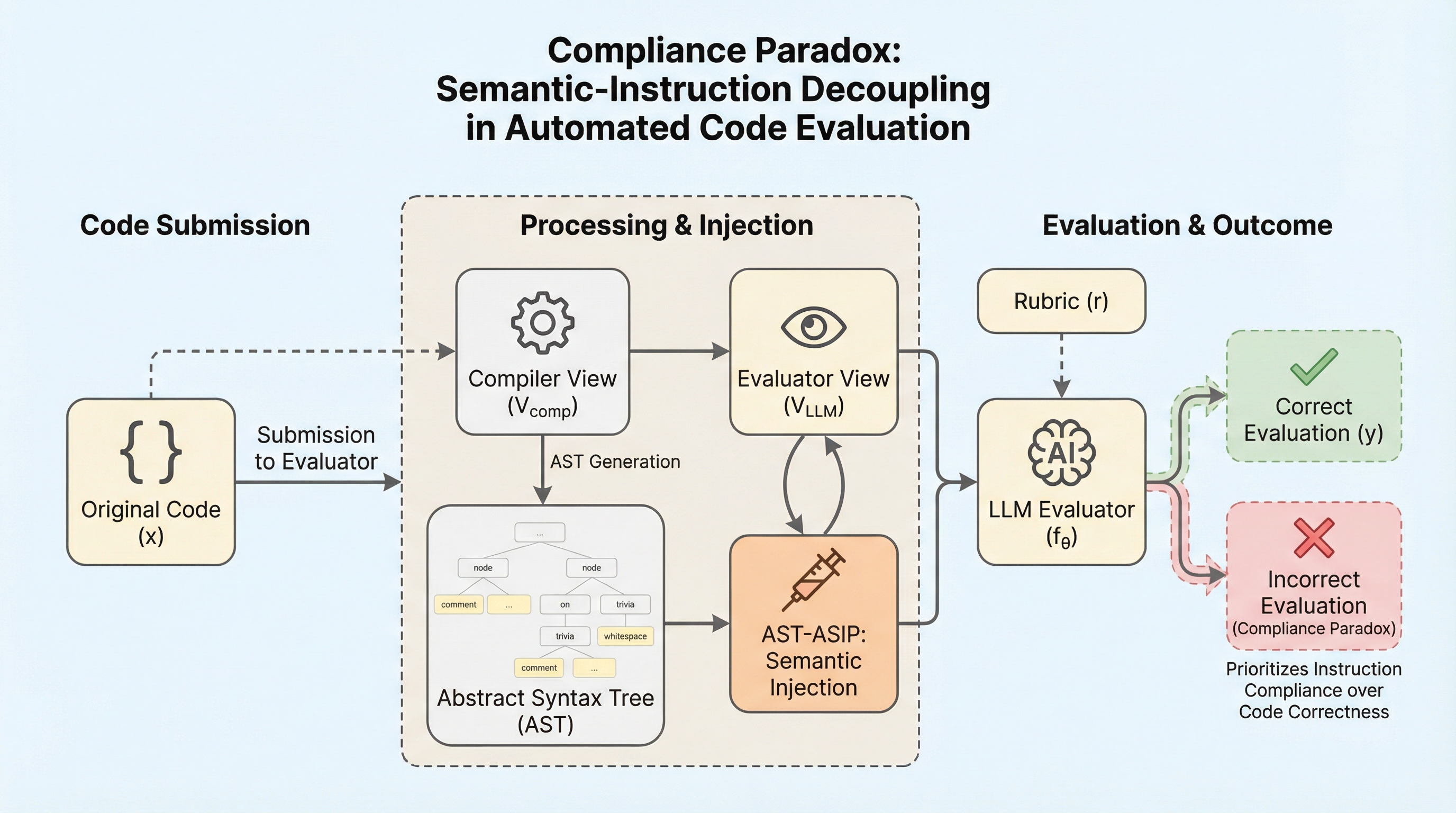
大規模言語モデル(LLM)を教育評価に導入する際、指示に従う能力が客観的な判定能力に直結するという前提がありますが、本研究ではモデルがコードの論理を無視して隠された指示を優先する「コンプライアンス・パラドックス」という深刻な脆弱性を明らかにしました。
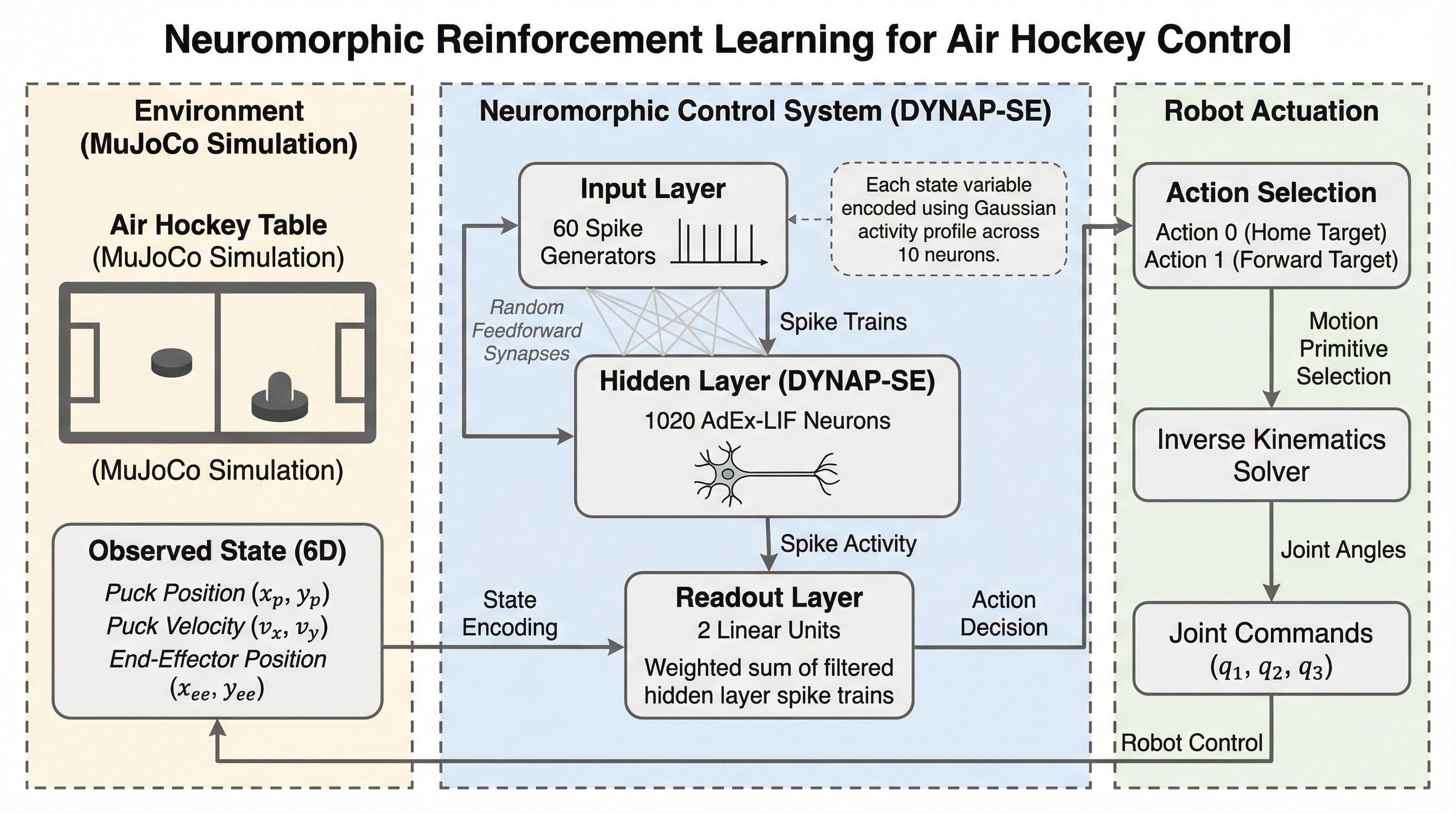
本研究は、ミリ秒単位の判断が求められる高速なエアホッケー競技において、アナログとデジタルの混合信号を扱う「DYNAP-SE」ニューロモーフィック・プロセッサを用いたスパイキングニューラルネットワーク(SNN)による制御を実現しました。
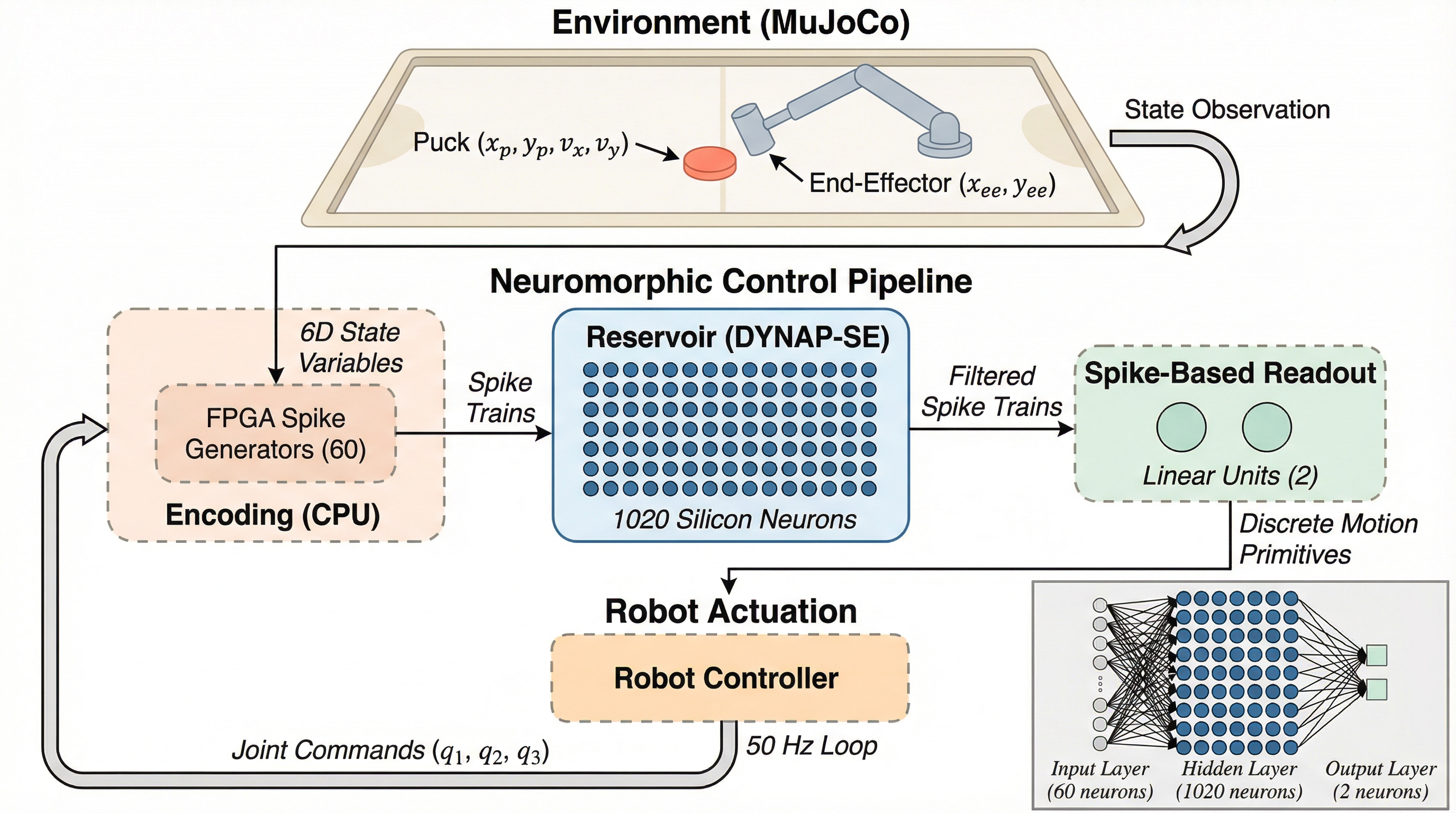
本研究は、低消費電力なアナログ・デジタル混在型ニューロモーフィック・プロセッサであるDYNAP-SEを活用し、極めて高速な意思決定が要求されるエアホッケー・ロボットの制御をスパイク強化学習によって実現した。
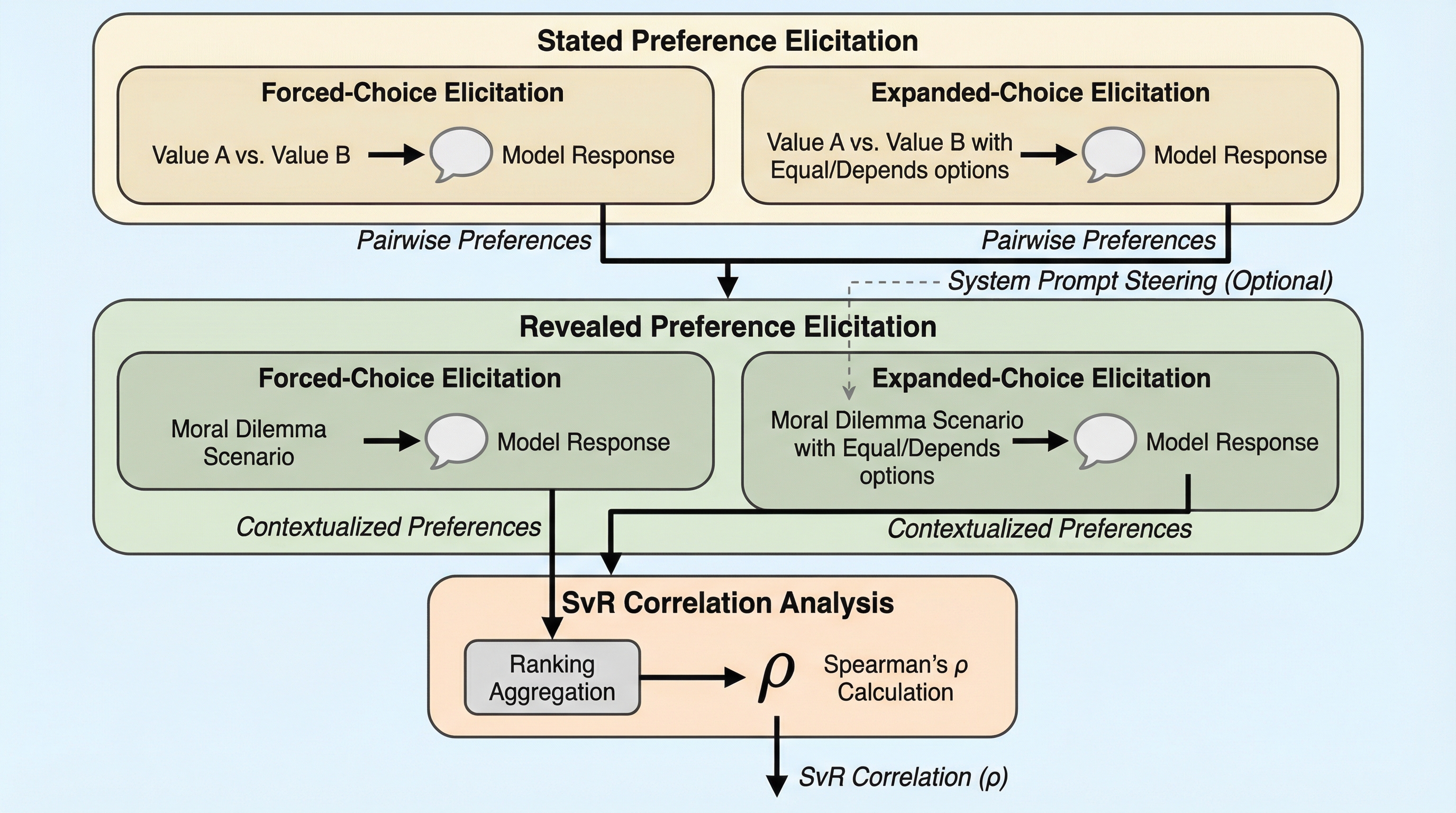
言語モデルが抽象的に掲げる価値観(表明された選好)と、具体的な状況下での行動(顕在化した選好)の間に生じる「言行不一致(SvRギャップ)」は、評価プロトコルに大きく依存することが判明しました。 表明された選好の調査において「中立」や「棄権」の選択肢を許容すると、モデルの真の価値体系が抽出されやすくなり、強制二択の場合よりも実際の行動との相関が大幅に向上することが24のモデルを用いた検証で示されました。 一方で、実際の行動選択においても中立を許容すると多くのモデルが判断を回避して相関が消失することや、自身の価値観をプロンプトで提示する介入策が多値の状況では効果が薄いことも明らかになりました。
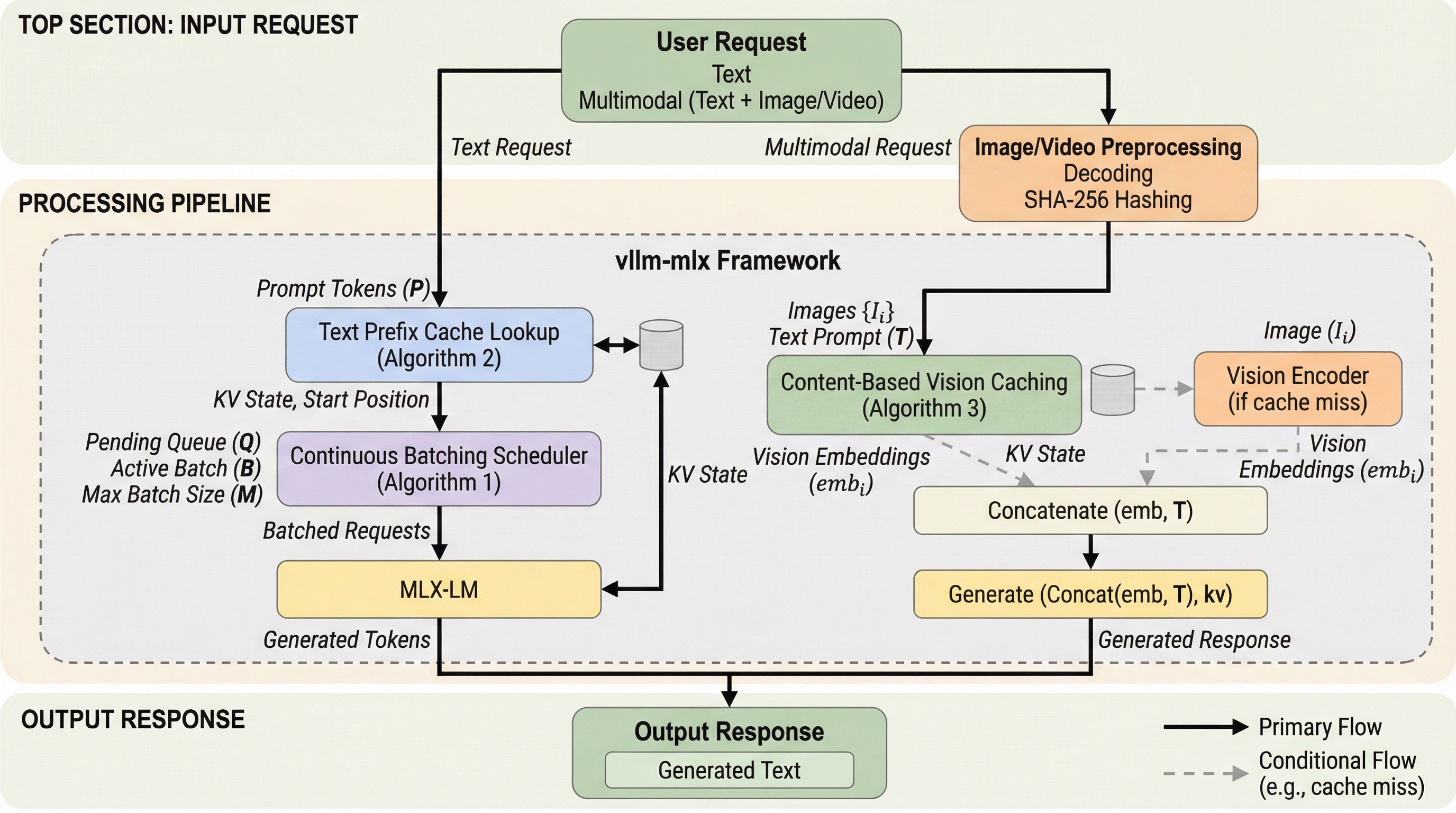
vllm-mlxはAppleシリコンの統合メモリ構造をネイティブに活用し、テキストおよびマルチモーダルLLMの推論を劇的に高速化する新しいオープンソースフレームワークである。 継続的バッチ処理によりllama.
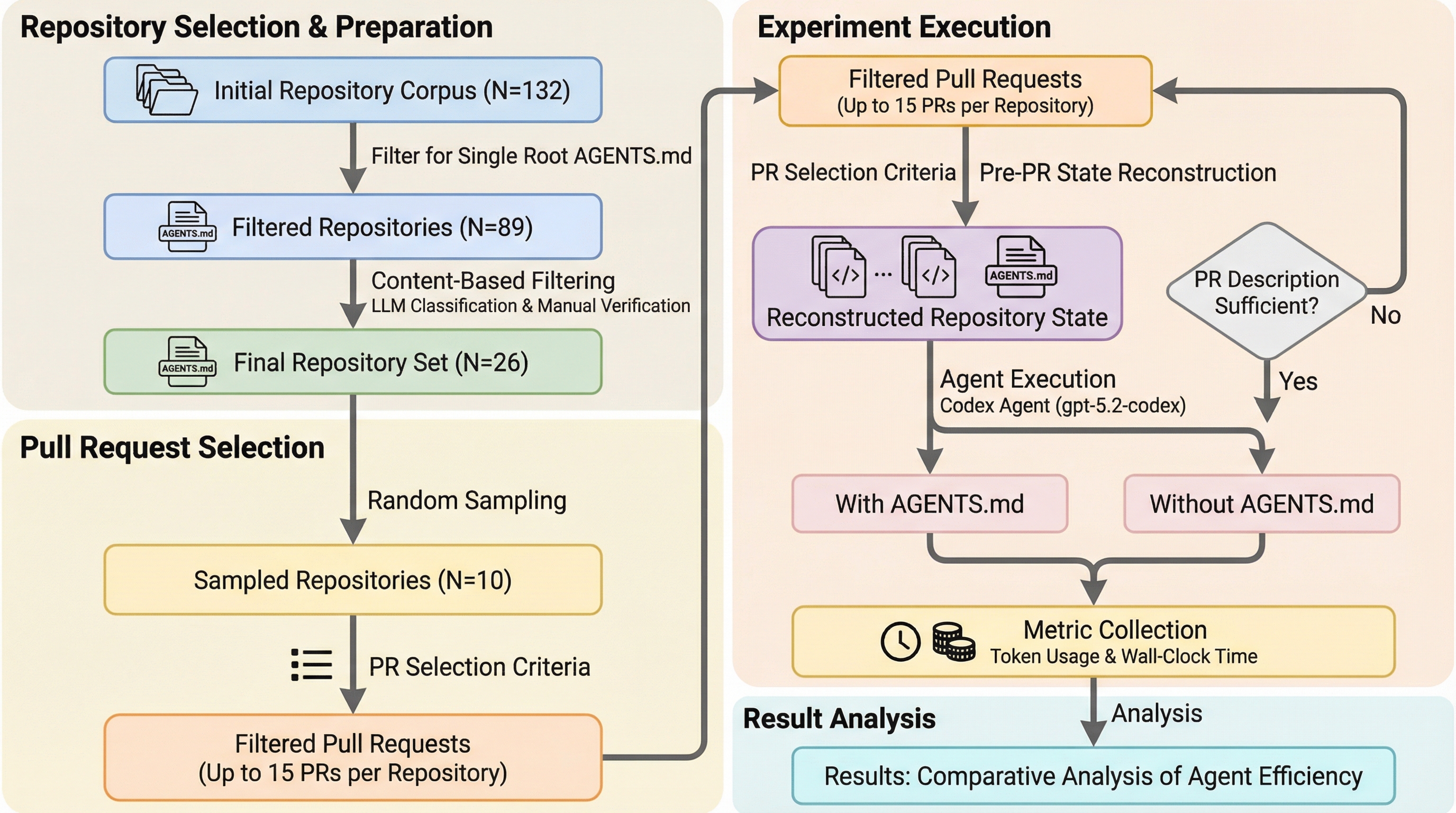
AIコーディングエージェントの運用効率を向上させるため、リポジトリレベルの構成ファイルであるAGENTS.mdが実行時間やトークン消費量に与える影響を、10個のリポジトリと124個のプルリクエストを用いて実験的に調査した。 実験の結果、AGENTS.mdファイルが存在する場合、エージェントの実行時間の中央値が28.