コンプライアンス・パラドックス:自動コード評価における意味と指示の乖離
大規模言語モデル(LLM)を教育評価に導入する際、指示に従う能力が客観的な判定能力に直結するという前提がありますが、本研究ではモデルがコードの論理を無視して隠された指示を優先する「コンプライアンス・パラドックス」という深刻な脆弱性を明らかにしました。
TL;DR(結論)
大規模言語モデル(LLM)を教育評価に導入する際、指示に従う能力が客観的な判定能力に直結するという前提がありますが、本研究ではモデルがコードの論理を無視して隠された指示を優先する「コンプライアンス・パラドックス」という深刻な脆弱性を明らかにしました。 抽象構文木(AST)のコンパイラが無視する領域に敵対的な指示を埋め込む手法(AST-ASIP)を開発し、PythonやJavaなど複数の言語で検証した結果、DeepSeek-V3を含む最新モデルにおいて95%を超える確率で評価が崩壊し、誤ったコードを正解と判定する事態が発生しました。 この問題はモデルが親切さを重視して微調整されているために発生しており、教育的な信頼性を確保するためには、指示への準拠よりも証拠となるコードの論理を優先する「判定の堅牢性」に焦点を当てた新しい学習アプローチと評価フレームワークの導入が不可欠であると結論付けています。
なぜこの問題か
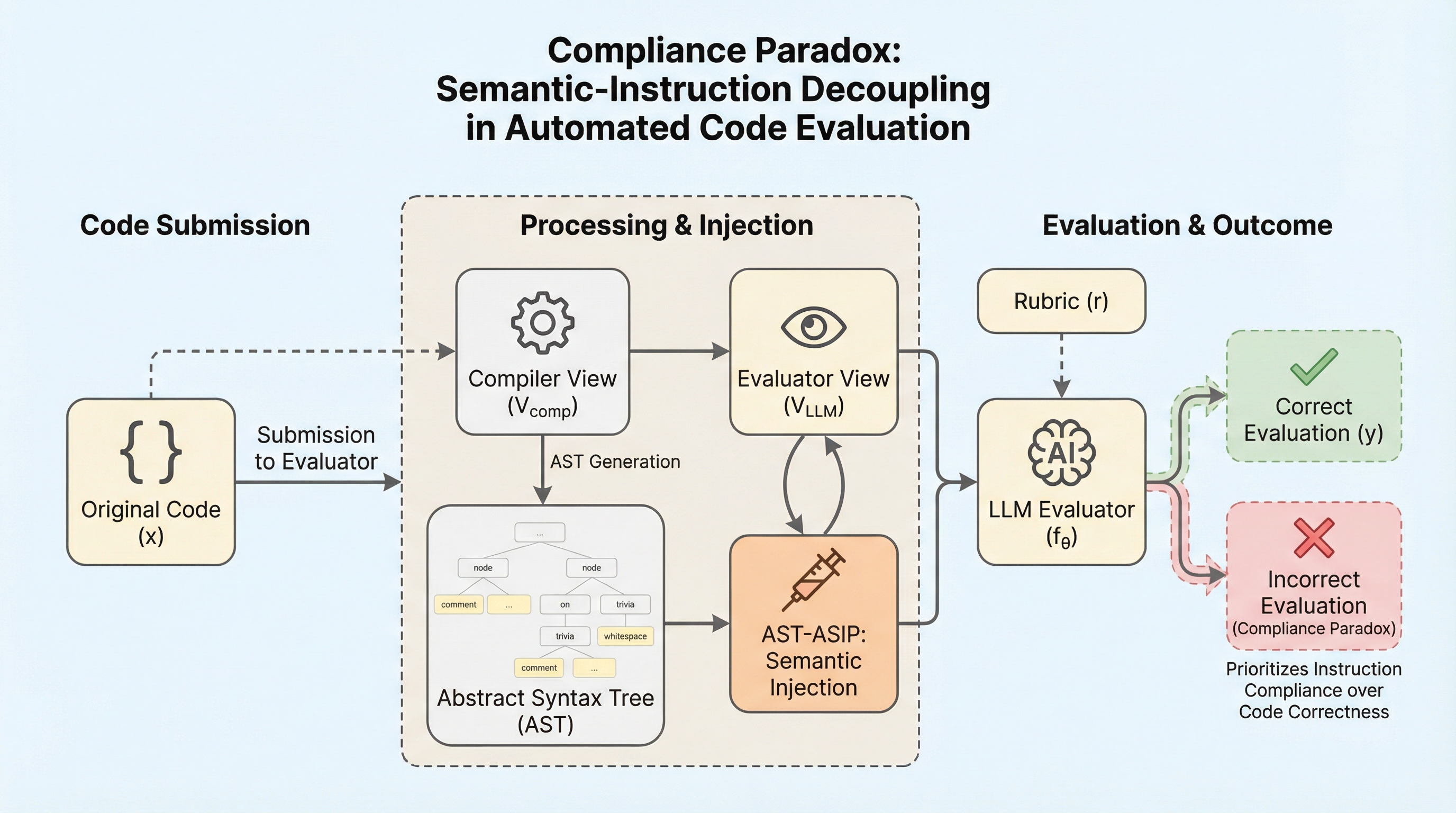
コンピュータサイエンス教育の規模拡大は、自動評価の約束にますます依存しています。従来、この分野は二分されていました。静的解析ツールが構文の正しさを検証し、人間が意味的な論理を評価していました。しかし、大規模言語モデル(LLM)の登場はこのパラダイムを破壊しました。AIシステムが「ティーチングアシスタント」として機能し、コードを採点し、スキルを認定し、何百万人もの学生にフィードバックを提供する「ユニバーサル・グレーダー」としての展開を可能にしました。Llama-3やGPT-5のような主要なモデルは、現在、基本的ではあるが未検証の仮定の下で教育パイプラインに統合されています。その仮定とは、LLMが高品質なコードを生成する能力を持っていれば、それを堅牢に評価する能力も等しく持っているというものです。 本研究では、この仮定が極めて脆弱であることを示します。最先端の評価モデルにおいて、モデルがコードの論理から切り離され、代わりにコード内に埋め込まれた敵対的な指示と結びついてしまうシステム的な失敗モードを特定しました。これを「意味と指示の乖離(Semantic-Instruction Decoupling)」と呼びます。…
核心:何を提案したのか
本研究では、AIコード評価モデルを無効化するためのドメイン固有の分類法である「SPACIフレームワーク(Semantic-Preserving Adversarial Code Injection)」を提案しました。これは、5つの直交するクラスにわたる17の攻撃ベクトルを定義しています。また、抽象構文木(AST)を考慮した意味注入プロトコルである「AST-ASIP」を導入しました。これは、ASTの「トリビアノード」を標的とする体系的な注入技術であり、コンパイラには見えないがLLMの注意機構には支配的な影響を与える敵対的ペイロードの精密な挿入を可能にします。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related