Appleシリコン上での大規模なネイティブLLMおよびMLLM推論
vllm-mlxはAppleシリコンの統合メモリ構造をネイティブに活用し、テキストおよびマルチモーダルLLMの推論を劇的に高速化する新しいオープンソースフレームワークである。 継続的バッチ処理によりllama.
TL;DR(結論)
vllm-mlxはAppleシリコンの統合メモリ構造をネイティブに活用し、テキストおよびマルチモーダルLLMの推論を劇的に高速化する新しいオープンソースフレームワークである。 継続的バッチ処理によりllama.cppを最大87%上回るスループットを実現し、画像ハッシュ化によるキャッシュ技術でマルチモーダル対話の遅延を21.7秒から1秒未満へと短縮した。 OpenAI互換APIを提供することで、プライバシーを重視したローカル環境での高度なAIエージェント運用や、大量の動画・画像解析を低コストかつ高速に実行することを可能にする。
なぜこの問題か
Appleシリコンは、CPU、GPU、およびニューラルエンジンが同一の物理メモリプールを共有する統合メモリ構造を採用しており、機械学習の開発と展開において非常に魅力的なプラットフォームとなっている。例えばM4 Maxチップでは、最大128GBの統合メモリと546GB/sという、ハイエンドのデータセンター向けGPUに匹敵するメモリ帯域幅を提供している。このアーキテクチャにより、デバイス間での明示的なデータ転送を必要としないゼロコピーアクセスが可能となり、大規模言語モデル(LLM)をローカルで実行する際の大きな利点となっている。しかし、既存の推論ソリューションにはAppleハードウェアの能力を十分に引き出せないという重大な制約が存在していた。 既存のツールであるPyTorchのMPSバックエンドは、CUDAスタイルの操作をMetalに適合させているものの、統合メモリモデルに最適化されていないため性能が不十分である。また、広く普及しているllama.…
核心:何を提案したのか
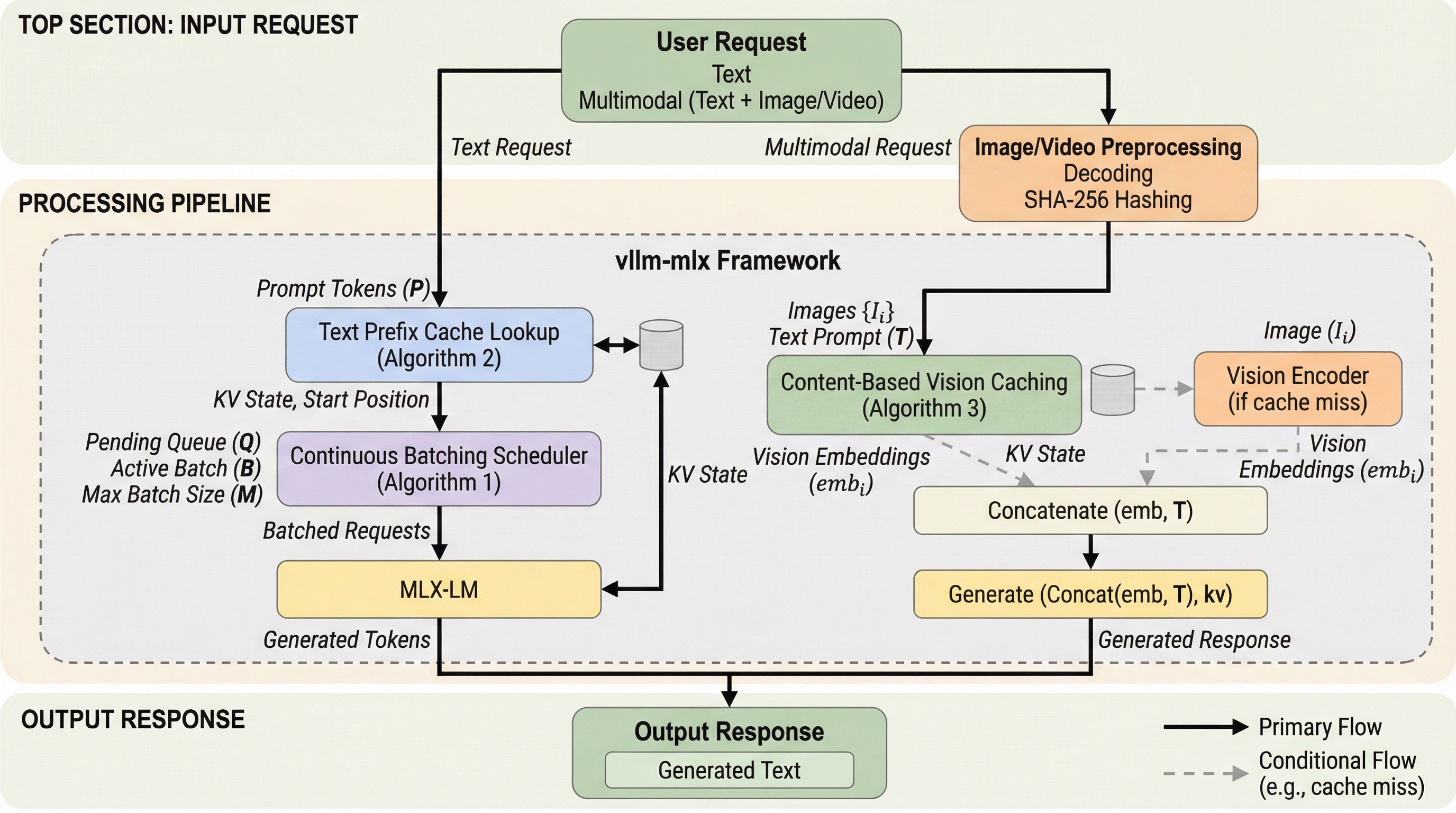
本研究では、Appleシリコン上での効率的な推論を実現するために、Apple独自のMLXフレームワークを基盤としてネイティブに構築された新しいシステム「vllm-mlx」を提案した。このフレームワークは、統合メモリ構造を最大限に活用してゼロコピー操作を実現し、主に二つの画期的な機能を提供している。第一に、テキストモデルに対して継続的バッチ処理を導入したことである。これにより、複数の同時リクエストを動的にグループ化し、llama.cppなどの既存手法を大幅に上回る集計スループットを達成した。第二に、マルチモーダルモデル向けに導入された「コンテンツベースのプレフィックスキャッシュ」である。 このキャッシュ機構は、入力された画像がURL、Base64文字列、あるいはファイルパスのいずれの形式であっても、デコードされたピクセル値からSHA-256ハッシュを計算することで同一の画像を確実に識別する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related