ヒントにお金を払え、答えではなく:コスト効率の良い推論のためのLLMシェパディング
大規模言語モデル(LLM)の回答全体を生成させるのではなく、冒頭の数トークンを「ヒント」として購入し、それを小規模言語モデル(SLM)に与えて推論を完結させる新しいフレームワーク「LLMシェパディング」が提案されました。
TL;DR(結論)
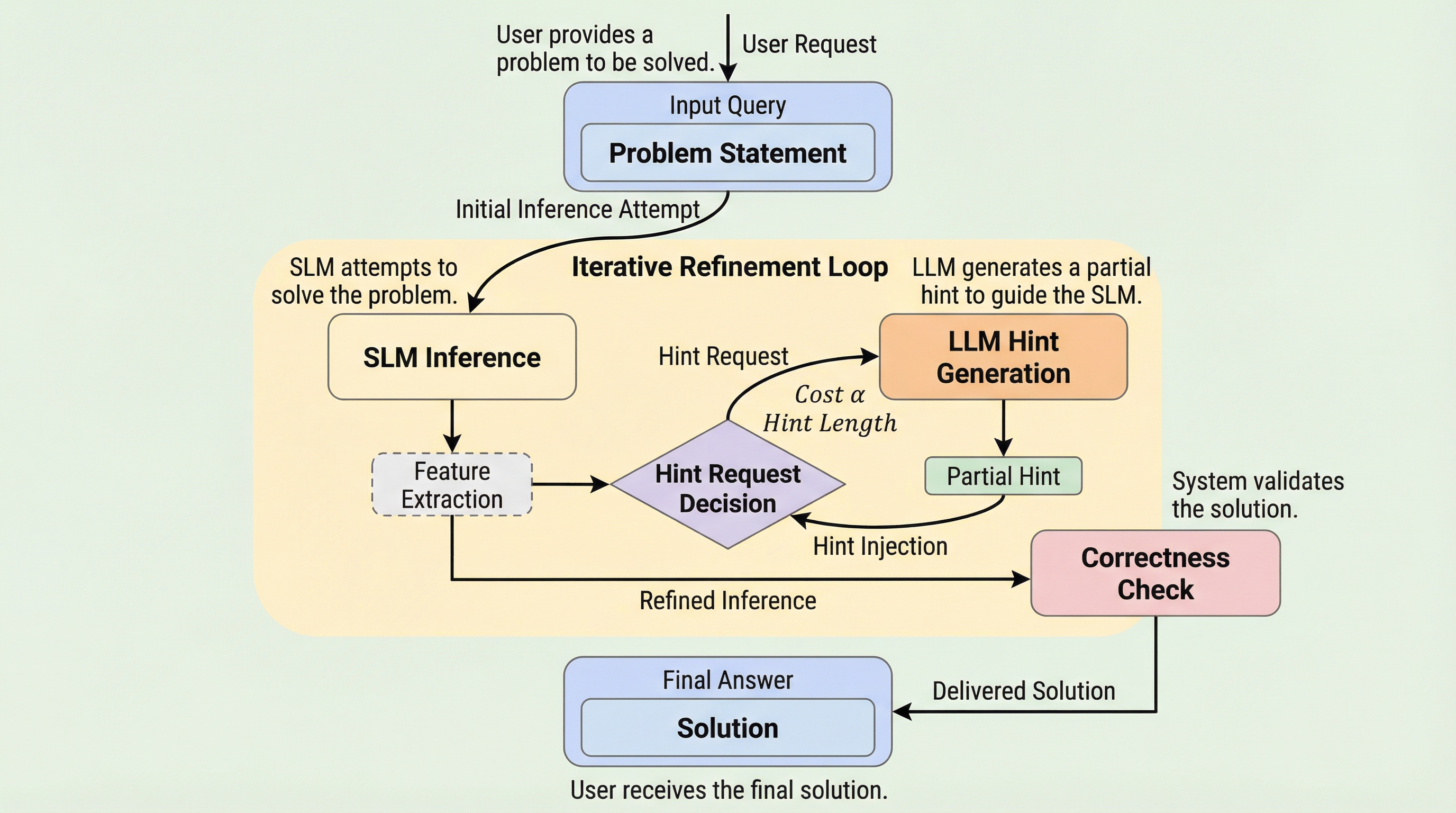
大規模言語モデル(LLM)の回答全体を生成させるのではなく、冒頭の数トークンを「ヒント」として購入し、それを小規模言語モデル(SLM)に与えて推論を完結させる新しいフレームワーク「LLMシェパディング」が提案されました。この手法は、数学やプログラミングのタスクにおいて、LLMの回答のわずか10〜30%をヒントとして利用するだけでSLMの精度を劇的に向上させ、従来のルーティングやカスケード手法と比較して最大2.8倍のコスト削減を実現します。ヒントが必要かどうかと必要なトークン数を予測する2段階の予測モデルを導入することで、LLMを「全か無か」の資源としてではなく、トークン単位で予算制御可能なリソースとして活用することに成功し、全体で42〜94%のコスト削減を達成しました。
なぜこの問題か
現在、大規模言語モデル(LLM)は複雑な推論タスクにおいて最高水準の性能を発揮していますが、その膨大な推論コストが大規模な導入を阻む大きな壁となっています。一方で、オープンソースの小規模言語モデル(SLM)は、低遅延、プライバシーの向上、そして金銭的・エネルギー的コストの劇的な削減という利点を持っていますが、論理的思考や数学的タスクにおいてはLLMに大きく劣るという精度の格差が存在します。このため、ユーザーは「低コストだが低品質な回答」を受け入れるか、「高品質だが高額なLLM」を利用するかという困難な二者択一を迫られています。このコストと品質のトレードオフを解決するために、既存の解決策として「ルーティング」と「カスケード」という2つのパラダイムが登場しています。 ルーティングは、クエリの複雑さに応じてSLMかLLMのどちらか一方に処理を振り分ける手法です。カスケードは、まずSLMが回答を試み、その信頼性が低い場合にのみLLMを呼び出す逐次的な手法です。しかし、これらの手法には共通の根本的な限界があります。それは、LLMを「全か無か(all-or-nothing)」のリソースとして扱っている点です。…
核心:何を提案したのか
本論文では、LLMから短い接頭辞(プレフィックス)である「ヒント」のみを取得し、それをSLMに提供して最終的な回答を生成させる「LLMシェパディング(LLM Shepherding)」というフレームワークを提案しています。これは、LLMに答えをすべて書かせるのではなく、解法の糸口となる最初の数トークンだけを生成させ、その後の推論をSLMに委ねるというアプローチです。この手法の核心は、LLMの回答のわずか10〜30%程度の長さのヒントであっても、SLMの精度を劇的に向上させることができるという発見にあります。数学的推論やコード生成のタスクにおいて、LLMが示す最初の数ステップや方針が、SLMが正しい結論に到達するための強力なガイドとして機能します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related