DASH: 大規模言語モデルの再現可能な学習を実現する高スループットな決定論的アテンション・スケジューリング
大規模言語モデル(LLM)の学習において、計算結果の再現性を保証する決定論的アテンションは不可欠だが、従来のFlashAttention-3等では勾配蓄積の直列化によりスループットが最大37.9%低下する課題があった。
TL;DR(結論)
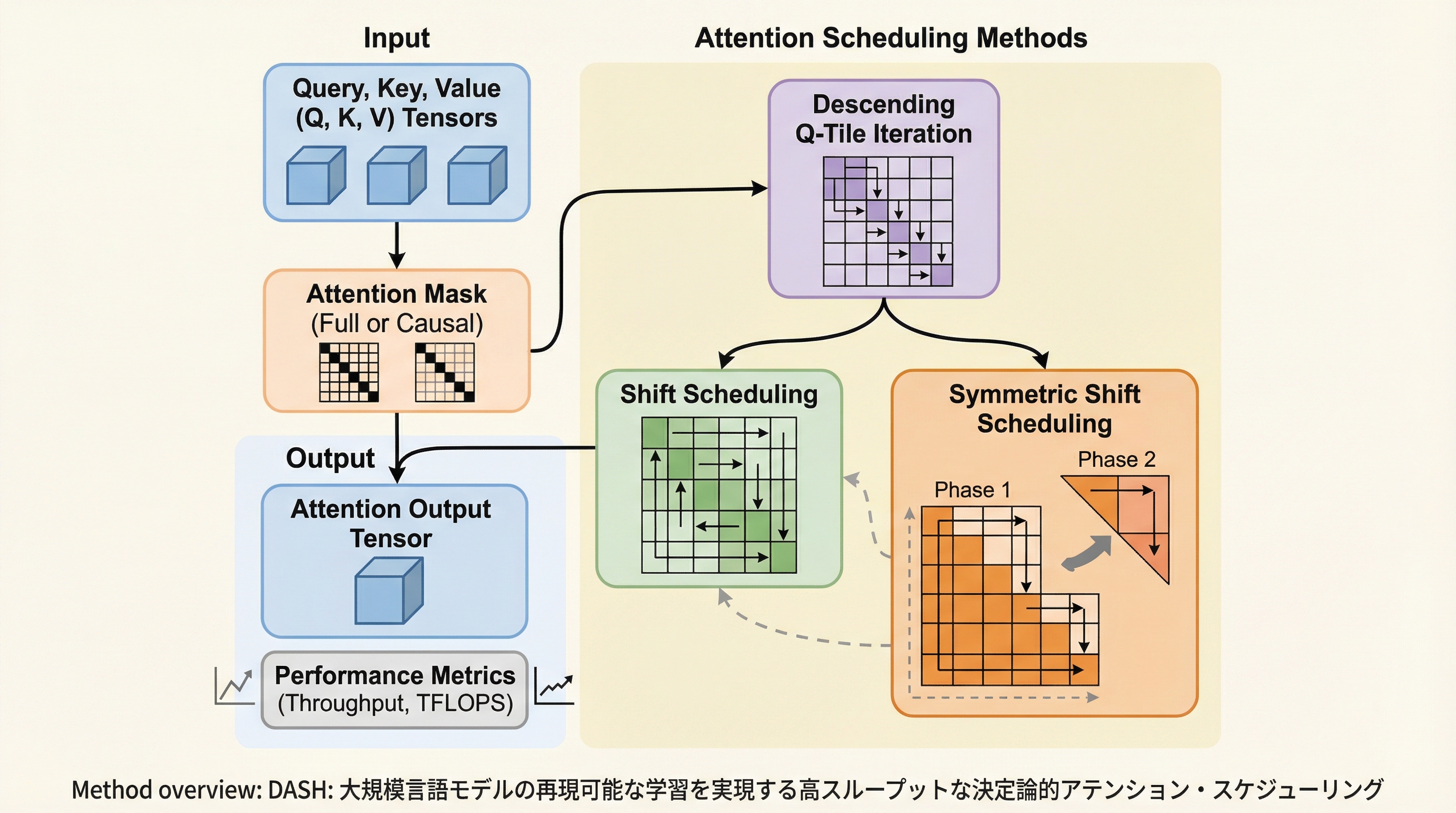
大規模言語モデル(LLM)の学習において、計算結果の再現性を保証する決定論的アテンションは不可欠だが、従来のFlashAttention-3等では勾配蓄積の直列化によりスループットが最大37.9%低下する課題があった。本研究では、バックワードパスを有向非巡回グラフ(DAG)上のスケジューリング問題として定式化し、パイプラインの空き時間を最小化する「降順Qタイル反復」と「シフトスケジューリング」という2つの戦略を提案した。NVIDIA H800 GPUを用いた検証の結果、提案手法であるDASHは従来の決定論的ベースラインと比較して最大1.28倍のスピードアップを達成し、計算効率を損なうことなくビット単位で同一の学習結果を得ることを可能にした。
なぜこの問題か
大規模言語モデル(LLM)の学習は、数千枚のGPUを数週間にわたって稼働させる極めてコストの高いプロセスであり、科学的な厳密さと工学的な信頼性の観点から「再現性」が極めて重要である。再現性が保証されていれば、学習中に発生する損失の発散といった不安定な挙動の診断や、モデル構造を変更した際の影響評価を正確に行うことができる。しかし、現代のGPUコンピューティングにおいて、この再現性を確保することは容易ではない。その根本的な原因は、コンピュータにおける浮動小数点演算が結合法則を満たさないという特性にある。例えば、非常に大きな値と非常に小さな値を加算する際、その順序が変わるだけで計算結果に微小な差異が生じ、これが大規模な並列計算を通じて増幅されることで、実行ごとに異なる結果が導き出されてしまう。 現在、広く普及しているFlashAttentionのような高速なアテンション実装では、スループットを最大化するために非決定的なアトミック加算(atomicAdd)が用いられている。これは、複数のプロセッサが計算を終えた順に結果をメモリに書き込む方式であり、書き込み順序が制御されないため、実行のたびに数値的な不一致が発生する。…
核心:何を提案したのか
本研究では、決定論的アテンションのバックワードパスにおける性能低下を解決するため、実行プロセスを明示的なスケジューリング最適化問題として再定義した「DASH(Deterministic Attention Scheduling for High-Throughput)」を提案した。DASHの核心は、決定論的な計算順序を維持しつつ、GPUのストリーミングマルチプロセッサ(SM)間の依存関係を整理し、クリティカルパス(全体の実行時間を決定する最長の経路)を最小化することにある。この目的を達成するために、研究チームはバックワードパスの全工程を有向非巡回グラフ(DAG)としてモデル化し、理論的な裏付けに基づいた新しいスケジューリング戦略を導き出した。 提案された戦略は、主に2つの柱で構成されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related