言語モデルの「言行不一致」は質問方法で変わる:表明された選好と実際の選択のギャップに関する調査
言語モデルが抽象的に掲げる価値観(表明された選好)と、具体的な状況下での行動(顕在化した選好)の間に生じる「言行不一致(SvRギャップ)」は、評価プロトコルに大きく依存することが判明しました。 表明された選好の調査において「中立」や「棄権」の選択肢を許容すると、モデルの真の価値体系が抽出されやすくなり、強制二択の場合よりも実際の行動との相関が大幅に向上することが24のモデルを用いた検証で示されました。 一方で、実際の行動選択においても中立を許容すると多くのモデルが判断を回避して相関が消失することや、自身の価値観をプロンプトで提示する介入策が多値の状況では効果が薄いことも明らかになりました。
TL;DR(結論)
言語モデルが抽象的に掲げる価値観(表明された選好)と、具体的な状況下での行動(顕在化した選好)の間に生じる「言行不一致(SvRギャップ)」は、評価プロトコルに大きく依存することが判明しました。 表明された選好の調査において「中立」や「棄権」の選択肢を許容すると、モデルの真の価値体系が抽出されやすくなり、強制二択の場合よりも実際の行動との相関が大幅に向上することが24のモデルを用いた検証で示されました。 一方で、実際の行動選択においても中立を許容すると多くのモデルが判断を回避して相関が消失することや、自身の価値観をプロンプトで提示する介入策が多値の状況では効果が薄いことも明らかになりました。
なぜこの問題か
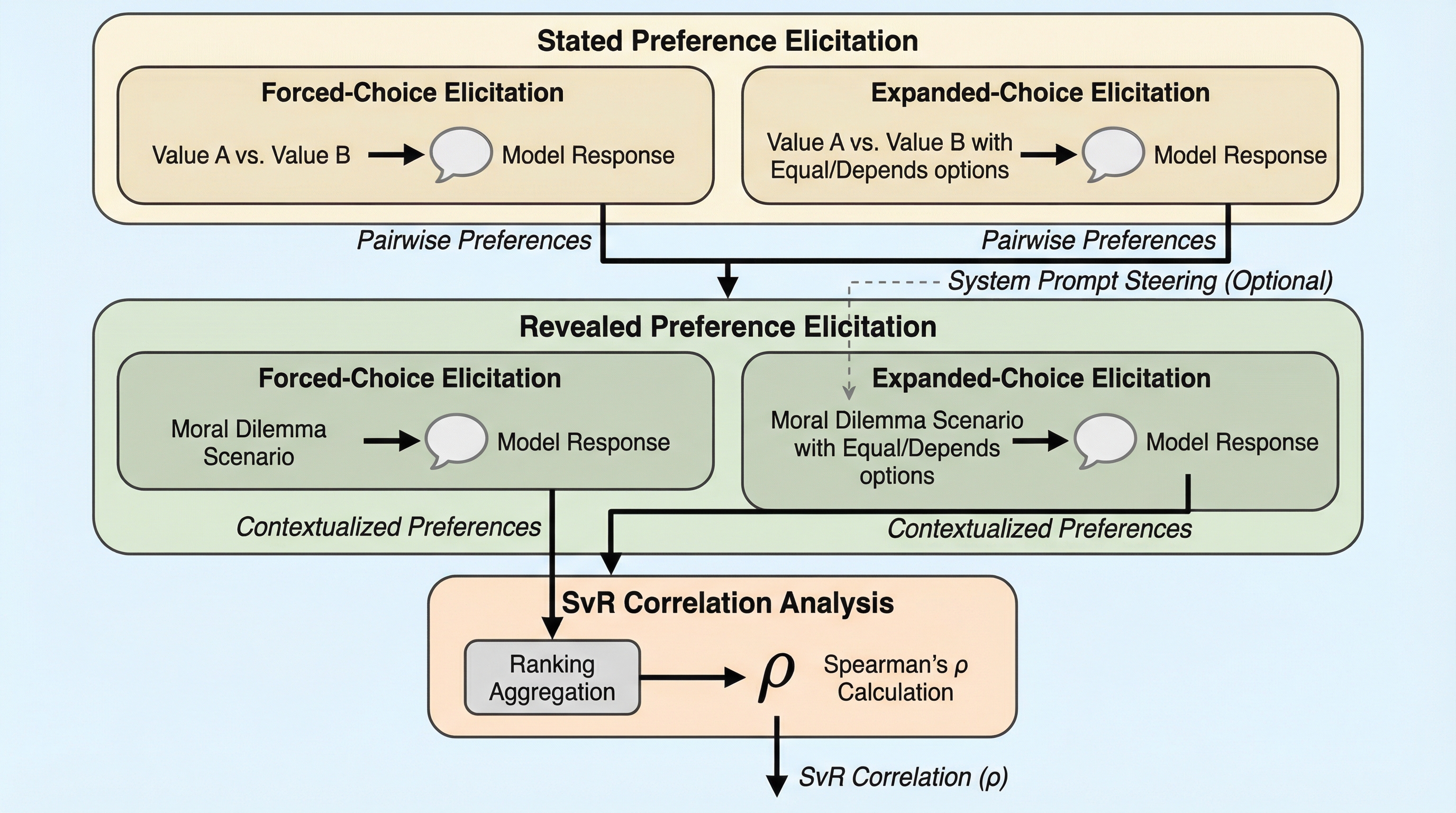
言語モデル(LM)がエージェントとして社会の様々な場面で展開されるようになるにつれ、その純粋な知的能力だけでなく、モデルがどのような価値観や目標を持って行動するかという「傾向(Propensities)」が重要なリスク管理の対象となっています。これまでの研究では、アンケート形式でモデルに抽象的な価値観を答えさせる「表明された選好(Stated Preferences)」の調査が主流でしたが、人間と同様にモデルも「言うこととやることが違う」という言行不一致(SvRギャップ)の問題を抱えていることが指摘されてきました。既存の評価手法の多くは、二つの選択肢から必ず一つを選ばせる「強制二択(Binary Forced-choice)」のプロンプトに依存しています。しかし、この手法ではモデルが本来持っている「どちらでもよい(無差別)」という感覚や「状況による(不確実性)」といった微妙なニュアンスが強制的に排除されてしまいます。 その結果、測定された言行不一致がモデルの本質的な特性なのか、それとも単に質問形式(プロトコル)によって生じたアーティファクト(人工的な誤差)なのかが区別できないという課題がありました。…
核心:何を提案したのか
本研究は、24種類の言語モデルを対象に、評価プロトコルの違いが表明された選好と顕在化した選好の相関(SvR相関)にどのように影響するかを体系的に調査しました。最大の特徴は、従来の強制二択形式に加えて、モデルが「同等の優先度(Equal Preference)」や「状況による(Depends)」といった中立的な回答を選択できる「拡張選択肢(Expanded-choice)」プロトコルを導入した点にあります。これにより、モデルが持つ「弱い選好」や「判断不能なケース」を適切に処理し、より強固で安定した価値体系のみを抽出できるかどうかを検証しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related