Appleシリコン上での大規模なネイティブLLMおよびMLLM推論
vllm-mlxは、Apple Siliconのユニファイドメモリ構造を最大限に活用するためにMLX上でネイティブに構築された、LLMおよびマルチモーダルLLM(MLLM)のための高効率な推論フレームワークである。継続的バッチ処理の導入により、従来のllama.
TL;DR(結論)
vllm-mlxは、Apple Siliconのユニファイドメモリ構造を最大限に活用するためにMLX上でネイティブに構築された、LLMおよびマルチモーダルLLM(MLLM)のための高効率な推論フレームワークである。継続的バッチ処理の導入により、従来のllama.cppと比較してテキストスループットを最大87%向上させ、16並列のリクエスト実行時には合計スループットを最大4.3倍にスケールさせることに成功した。 また、コンテンツベースのプレフィックスキャッシュ機構を実装することで、同一画像を用いた繰り返しクエリにおける冗長なビジョンエンコーディングを排除し、マルチモーダルな対話の遅延を21.7秒から1秒未満へと短縮する28倍の高速化を達成した。本フレームワークはOpenAI互換のAPIを備えたオープンソースとして公開されており、プライバシーを重視したローカル環境での高度なAIエージェント運用やリアルタイムなマルチモーダルアプリケーションの基盤を提供する。
なぜこの問題か
Apple Siliconは、CPUとGPU、そしてNeural Engineが物理的に同じメモリプールを共有するユニファイドメモリ構造を採用しており、最大192GBの共有メモリと400GB/sを超える広帯域幅を実現している。この特性は、巨大なメモリを必要とする大規模言語モデル(LLM)をローカル環境で実行する上で極めて有利な条件を備えている。しかし、既存の推論ソリューションにはAppleハードウェアの性能を完全に引き出すための課題が残されていた。例えば、PyTorchのMPSバックエンドはCUDAベースの設計をMetalに適合させているため、ユニファイドメモリモデルに最適化されたネイティブな動作が不足している。また、広く普及しているllama.cppはテキストモデルにおいて優れた性能を示すが、画像とテキストを同時に扱うビジョン言語モデル(VLM)をサポートしていない。 さらに、Apple Silicon向けの公式なバックエンドであるvLLM-metalは、継続的バッチ処理を提供するものの、マルチモーダルモデルへの対応やビジョンキャッシュ機能が欠落していた。…
核心:何を提案したのか
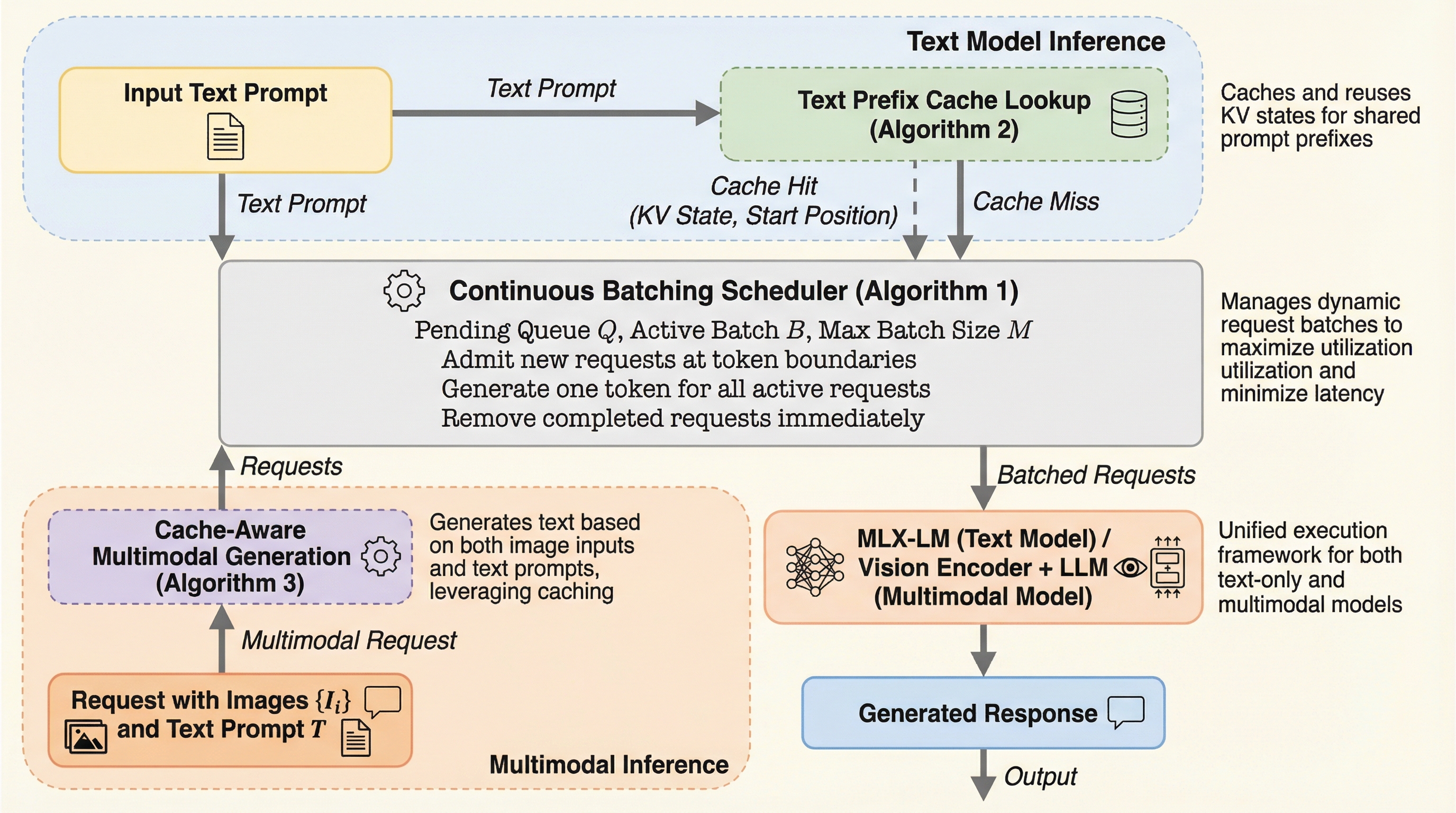
本研究では、Apple Silicon上での効率的なLLMおよびMLLM推論を実現する新しいフレームワーク「vllm-mlx」を提案した。このフレームワークは、Apple独自の機械学習ライブラリであるMLXの上にネイティブに構築されており、ユニファイドメモリを活かしたゼロコピー操作を全面的に採用している。vllm-mlxの核心的な提案は、大きく分けて二つの機能に集約される。第一に、テキストモデルにおいて複数のリクエストを同時に効率よく処理する「継続的バッチ処理(Continuous Batching)」の実装である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related